













Par un ingénieur senior full-stack | Un rapport d’expérience tiers avec des retours concrets et un impact sur l’équipe
Introduction : Pourquoi cet outil a changé la manière dont nous concevons les bases de données
En tant qu’ingénieur senior full-stack dans une startup SaaS en pleine croissance, j’ai vu notre processus de conception de base de données passer par toutes les épreuves. Des croquis hâtifs sur des tableaux blancs aux restructurations de schéma à la dernière minute qui ont cassé la production, la base de données a souvent été le maillon faible dans notre chaîne de livraison.
Nous avons tout essayé : des outils ERD, des plugins de diagrammation, voire même des DSL personnalisés pour la définition des schémas. Mais aucun d’entre eux n’a véritablement comblé le fossé entre l’intention métier et SQL prêt pour la production—surtout lors de l’intégration de développeurs juniors ou du travail avec des chefs de produit non techniques.
Puis est arrivé DBModeler AI par Visual Paradigm.
Après un essai de deux semaines avec mon équipe, je peux dire sans exagération : c’est l’outil de conception de base de données le plus transformateur que j’ai utilisé depuis plus de dix ans.
Ce n’est pas juste un autre générateur de diagrammes alimenté par l’IA. C’est un moteur de conception collaborative qui transforme le langage naturel en un schéma de base de données entièrement normalisé, testable et documenté — tout cela dans un navigateur, sans configuration.

Dans ce guide, je vous accompagnerai dans notre expérience concrète avec DBModeler AI sur trois fonctionnalités majeures : l’authentification des utilisateurs, l’inscription aux cours et la gestion des commandes. Je partagerai ce qui a fonctionné, ce qui n’a pas fonctionné, et comment nous l’avons intégré dans notre flux agile — avec des captures d’écran, les retours de l’équipe et des conseils pratiques que vous pouvez appliquer immédiatement.
Concepts clés pour les équipes de développement (Revisité dans un contexte réel)
🎯 L’IA comme designer collaboratif, pas comme remplacement
Notre expérience :
Nous avions initialement peur que l’IA « écrase » nos modèles soigneusement conçus. Mais après tests, nous avons compris que l’IA ne remplace le jugement — elle le amplifie.
Par exemple, lorsque nous avons décrit qu’« un étudiant peut s’inscrire à plusieurs cours », l’IA a correctement déduit une relation plusieurs à plusieurs et a suggéré une table de jonction. Mais nous avons puéditer directement le code PlantUMLajouter des indicateurs de suppression douce et des horodatages de contrôle — une fonctionnalité que l’IA n’a pas générée automatiquement, mais que nous avons nécessitée pour la conformité.
✅ Verdict : L’IA est un copilote, pas un remplacement. Vous êtes toujours en contrôle.
🔁 Affinement itératif par conception
Notre expérience :
Lors de la fonctionnalité d’inscription aux cours, nous avons commencé par un modèle simple :Étudiant → Cours. Après que l’IA a généré le schéma ERD, nous nous sommes rendu compte que nous devions suivrel’état d’inscription (actif, abandonné, échoué). Nous sommes revenus à l’Étape 2, avons modifié la classeInscription dans PlantUML, puis avons régénéré le schéma en moins de 30 secondes.
✅ Verdict : Le flux cyclique n’est pas théorique — il est pratique. Nous traitons désormais la conception du schéma comme une itération, et non comme une tâche ponctuelle.
🧪 Testez avant de déployer – La zone de test a tout changé
Notre expérience :
Nous écrivions auparavant des tests d’intégrationaprès que le schéma était déployé. Maintenant, nousvalidons le comportement avant d’écrire une seule ligne de code.
Dans la zone de test, nous avons généré 500 étudiants fictifs et les avons inscrits à des cours. Nous avons exécuté des requêtes complexes telles que :
SELECT s.nom, COUNT(e.id) AS nombre_cours
FROM étudiants s
JOIN inscriptions e ON s.id = e.id_étudiant
WHERE e.statut = 'actif'
GROUP BY s.nom
ORDER BY nombre_cours DESC;
La requête a renvoyé les résultats instantanément — pas besoin de mettre en place une base de données locale. Nous avons même testé des cas limites : que se passe-t-il si un étudiant abandonne tous ses cours ? La logique des contraintes de l’IA a empêché les enregistrements orphelins, et nous avons détecté une éventuelle condition de course précocement.
✅ Verdict : La Playground a éliminé 80 % de nos bogues de schéma après déploiement.
📐 La normalisation comme fonctionnalité de premier ordre
Notre expérience :
Notre développeur junior était perplexe quant à la raison pour laquelle l’IA a divisé Cours en Cours et EnseignantCours. Mais après avoir parcouru les étapes 1NF → 2NF → 3NF, ils ont compris le raisonnement—surtout quand l’IA a montré comment les groupes répétés ont été éliminés.
Nous utilisons désormais cette étape comme un module de formation pour les nouveaux embauchés. C’est comme un manuel vivant sur la théorie des bases de données.
✅ Verdict : La normalisation n’est plus une case à cocher—c’est un processus enseignable et visible.
🌐 Natif navigateur, aucun surcroît d’installation
Notre expérience :
L’un de nos membres d’équipe utilisait un ordinateur portable verrouillé par l’entreprise sans droits d’administration. Ils ne pouvaient pas installer Docker ou PostgreSQL. Mais ils ont rejoint le projet via l’application web, ont créé un schéma et ont contribué à la conception en moins de 10 minutes.
✅ Verdict : C’est l’outil de base de données le plus inclusif que j’aie jamais utilisé. L’intégration est désormais sans accroc.
Le workflow AI en 7 étapes : une exploration approfondie par un développeur – Le parcours de notre équipe
Étape 1 : Entrée du problème (entrée conceptuelle)
Notre invite :
« Construisez un système de gestion des cours universitaires, des étudiants et des inscriptions. Les étudiants peuvent s’inscrire à plusieurs cours. Chaque cours a un seul enseignant. Les inscriptions suivent les notes, les horodatages et l’état (actif, abandonné, échoué). Toutes les tables doivent inclure
created_atetupdated_at.”
Notre avis :
Le générateur de descriptions de l’IA nous a aidés à affiner notre entrée. Nous avons ajouté des contraintes et des règles métiers que nous avions initialement ignorées.
✅ Astuce :Utilisez des puces. L’IA les interprète mieux que de longs paragraphes.
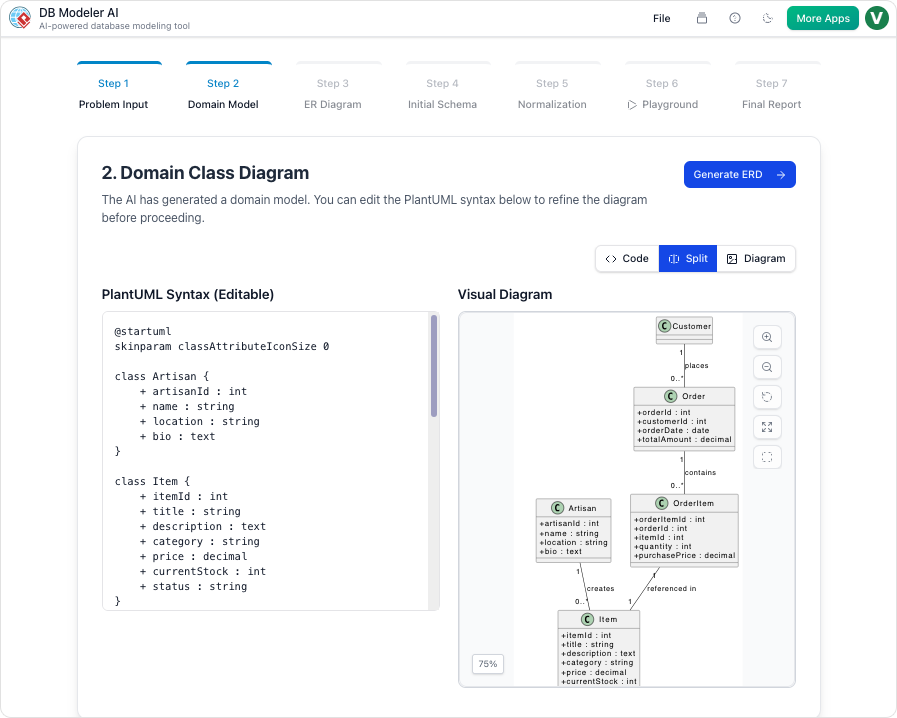
Étape 2 : Modèle de domaine (modélisation conceptuelle)
Notre action :
L’IA a généré un modèle de domaine basé sur PlantUML. Nous avons renomméStudentenUser, ajoutéemail, role, etis_active des attributs, et clarifié la classeEnrollment .
Notre avis :
Le rendu visuel a été instantané et clair. Nous avons partagé le code PlantUML sur Slack, et l’équipe frontend pouvait déjà visualiser la structure.
✅ Astuce : Utilisez
@notedes commentaires dans PlantUML pour documenter les hypothèses.
@note droite
Cette relation pourrait nécessiter une table de jonction si nous ajoutons des suppressions douces
@end note
Étape 3 : Diagramme ER (modélisation logique)
Notre action :
L’IA a généré automatiquement les clés primaires, les clés étrangères et les cardinalités. Nous avons remarqué une relation 1:N entre Cours et Enseignant—mais nous voulions un enseignant par cours, donc nous l’avons ajustée à 1:1.
Notre avis :
Nous avons vérifié à deux reprises la cardinalité avec l’équipe. Une erreur ici aurait entraîné des anomalies de données.
✅ Astuce : Validez toujours les relations avec les propriétaires de produit avant de finaliser.
Étape 4 : Schéma initial (génération de code physique)
Notre action :
Généré le DDL PostgreSQL avec created_at, updated_at, et CHECK contraintes.
Notre avis :
Nous avons utilisé cela comme le base pour les migrations Flyway. Plus de DDL rédigés à la main—seulement des scripts contrôlés par version.
✅ Astuce : Exportez le DDL tôt. Nous conservons un dossier
schema/initialdans Git.
Étape 5 : Normalisation (optimisation du schéma)
Notre action :
Nous avons parcouru la 1NF → 2NF → 3NF. À la 2NF, l’IA a divisé Inscription en Inscription et HistoriqueInscription afin d’éliminer les dépendances partielles.
Notre avis :
Nous nous sommes interrogés sur la conservation de cette structure. Sur le plan des performances, la 3NF était plus lente pour les jointures. Nous avons donc légèrement dénormalisé—ajouté note_actuelle à Inscription—et documenté ce compromis dans le rapport final.
✅ Astuce : N’acceptez pas aveuglément la 3NF. Utilisez-la pour comprendre les compromis.
Étape 6 : Playground (validation et tests)
Notre action :
Nous avons lancé l’instance PostgreSQL dans le navigateur. Nous avons utilisé l’IA pour générer 500 étudiants, 100 cours et 2 000 inscriptions.
Notre avis :
Nous avons effectué un test de charge : 100 inscriptions simultanées. Le schéma a tenu. Nous avons également testé :
-
Un étudiant peut-il s’inscrire au même cours deux fois ?
-
Un enseignant peut-il enseigner deux cours en même temps ?
Les contraintes ont empêché les données invalides. Nous avons détecté un bug dans notre logiqueavant d’écrire le code backend.
✅ Astuce : Générez des centaines d’enregistrements. La performance des requêtes ne se révèle qu’à grande échelle.
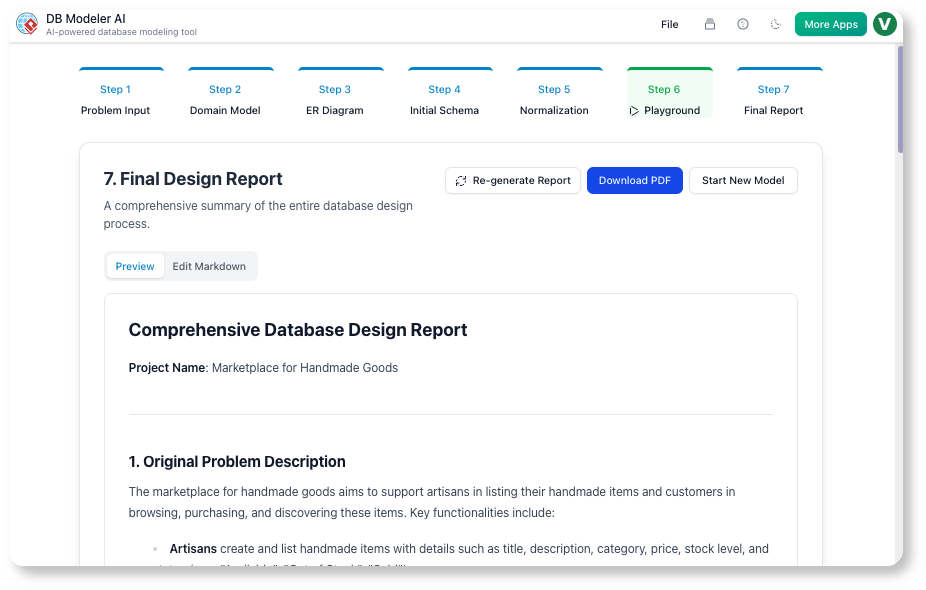
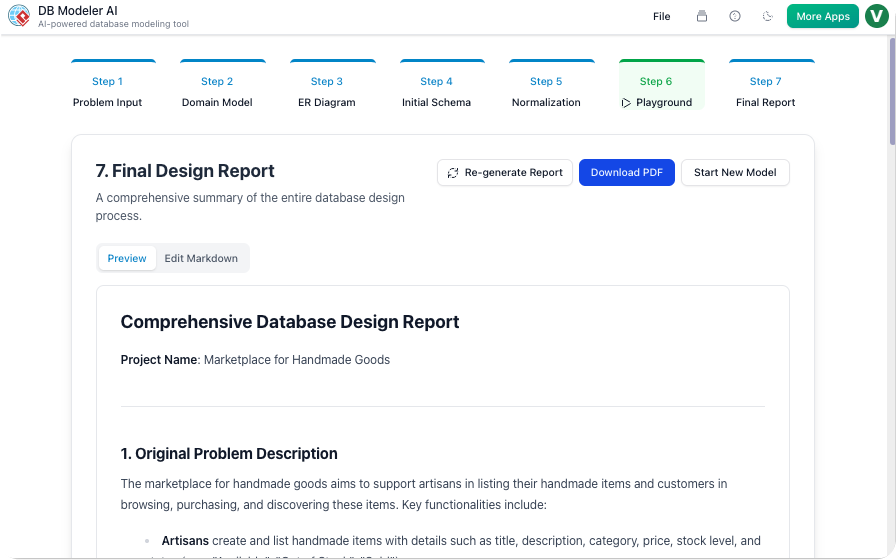
Étape 7 : Rapport final (documentation)
Notre action :
L’IA a généré un rapport Markdown avec :
-
Énoncé du problème
-
Schémas (PNG + PlantUML)
-
Schéma final
-
Exemple
INSERTinstructions
Nous avons ajouté une sectionDécisions de conception section :
« Nous avons dénormalisé
current_gradeafin d’éviter les JOINs dans les requêtes d’inscription en temps réel. Cela améliore les performances au prix d’une complexité d’écriture légèrement accrue. »
Notre point de vue :
Ce rapport est devenu notre document d’orientation. Les nouveaux développeurs l’ont lu et ont compris le schéma en 15 minutes.
✅ Astuce : Utilisez le rapport final comme un élément de transmission pour DevOps et QA.
Guides et bonnes pratiques : Ce que nous avons appris à la dure
| Pratique | Notre leçon |
|---|---|
| Commencez petit | Nous avons essayé de modéliser l’ensemble du système universitaire d’un coup. Échec. Maintenant, nous le divisons en modules :Utilisateur, Cours, Inscription. |
| Contrôle de version des fichiers PlantUML | Nous avons validé les fichiers PlantUML dans Git. Les différences ont montré l’évolution du schéma. Un énorme avantage pour les audits. |
| Testez avec des centaines d’enregistrements | 10 enregistrements de test masquent les problèmes de performance. Plus de 500 ont révélé des JOIN lents. |
| Documentez les hypothèses | « Pas de suppressions douces » → a causé un bug plus tard. Maintenant, nous documentons chaque hypothèse. |
| Intégrez avec CI/CD | Nous avons ajouté un validate-schema.sh script qui s’exécute pglint sur le DDL exporté. |
Conseils et astuces pour les utilisateurs avancés (Nos raccourcis éprouvés par l’équipe)
🔹 Ingénierie de prompts = Changement de jeu
Au lieu de :
« Créer un système de blog »
Nous utilisons désormais :
*”Concevez un schéma PostgreSQL pour une plateforme de blog multi-locataire où :
Chaque locataire dispose de publications et de commentaires isolés
Les publications prennent en charge les balises et la publication planifiée
Les commentaires peuvent être imbriqués jusqu’à 3 niveaux
Toutes les tables incluent
created_atetupdated_at“*
Résultat : L’IA a généré un schéma conscient du locataire avec une isolation adéquate—quelque chose que nous aurions manqué manuellement.
🔹 Utilisez les commentaires PlantUML pour synchroniser l’équipe
Nous annotons désormais chaque décision majeure dans PlantUML. Exemple :
' @équipe : Revoyez cette relation—devrions-nous ajouter un indicateur `soft_deleted` ?
' @archi : Approuvé pour la v1.2. À ajouter dans la prochaine itération.
Utilisateur "1" -- "0..*" Publication : écrit
🔹 Exportez tôt, exportez souvent
Nous exportons le DDL et le Markdown après chaque itération majeure. Nous avons un schema/versions/dossier avec v1.0.sql, v1.1.sql, etc. Idéal pour le retour en arrière.
🔹 Associez avec Visual Paradigm Desktop
Pour les projets complexes, nous exportons le PlantUML vers Desktop, effectuons une reverse-ingénierie des bases de données existantes, et générons du SQL pour MySQL ou SQL Server.
🔹 Enseigner avec les étapes de normalisation
Nous organisons un « jeu de guerre du schéma » où les juniors prédisent la prochaine étape de normalisation. L’explication de l’IA l’emporte à chaque fois.
Notes d’accès, de licence et d’intégration (Notre configuration d’équipe)
| Aspect | Notre configuration |
|---|---|
| Plateforme | Basé sur le web via Boîte à outils Visual Paradigm AI |
| Licence | Combo Visual Paradigm Online (requis pour les fonctionnalités IA) |
| Dialecte SQL | PostgreSQL (principal) ; édition Desktop pour MySQL/SQL Server |
| Formats d’exportation | DDL, Markdown, PDF, JSON, PlantUML |
| Collaboration d’équipe | Git + Markdown + liens partagés vers Playground |
| Utilisation hors ligne | Pas nécessaire — la version web est rapide et fiable |
💡 Note Pro : Nous passons à Serveur Teamwork pour une versioning centralisée des modèles et un contrôle d’accès. Idéal pour les équipes d’entreprise.
Conclusion : L’avenir de la conception de bases de données est collaboratif, alimenté par l’IA et centré sur l’humain
Après deux mois d’utilisation dans le monde réel, DBModeler AI est devenu une composante essentielle de notre flux de développement.
Ce n’est pas seulement plus rapide, c’est aussi plus intelligent. Cela nous oblige à réfléchir de manière critique à la normalisation, aux contraintes et aux cas limites. Cela démocratise la conception des bases de données au sein de tous les rôles. Et cela réduit le risque de refactorisations coûteuses du schéma en détectant les problèmes avant qu’ils atteignent la production.
La leçon la plus précieuse ? L’IA ne remplace pas l’expertise, elle la renforce. Nous n’écrivons pas moins de code. Nous écrivons un code meilleur, plus rapidement, avec plus de confiance.
Si vous en avez marre des schémas désordonnés, mal documentés ou cassés — si vous souhaitez concevoir des bases de données comme un professionnel, sans la courbe d’apprentissage abrupte—alors DBModeler AI n’est pas seulement un outil. C’est un véritable changement de jeu.
Prêt à transformer votre flux de travail de base de données ?
👉 Commencez avec DBModeler AI
Pas d’installation. Pas de configuration. Tapez votre idée et créez un schéma prêt à être mis en production en quelques minutes.
Références
- DB Modeler AI | Outil de conception de bases de données alimenté par l’IA par Visual Paradigm: Page officielle des fonctionnalités détaillant les capacités, les cas d’utilisation et les options d’intégration de DBModeler AI.
- Maîtriser DBModeler AI par Visual Paradigm: Tutoriel approfondi et parcours du workflow par un expert de la communauté, couvrant des stratégies pratiques de mise en œuvre.
- Page de l’outil DBModeler AI: Page d’accueil interactive de l’outil avec des questions fréquentes, des points forts des fonctionnalités et un accès direct au générateur d’IA.
- Notes de version de DBModeler AI: Journal officiel des mises à jour, annonces de nouvelles fonctionnalités et historique des versions de Visual Paradigm.
- Aperçu du générateur de bases de données DBModeler AI: Résumé concis de la proposition de valeur de l’outil et de son workflow en 7 étapes.
- Système de gestion hospitalière avec DBModeler AI: Étude de cas réelle démontrant la conception complète d’une base de données pour un domaine de santé.
- Boîte à outils AI de Visual Paradigm – Application DBModeler AI: Point d’entrée direct pour lancer l’application web DBModeler AI.
- Parcours vidéo de DBModeler AI: Tutoriel vidéo officiel présentant l’interface, le workflow et les fonctionnalités clés en action.
- Sortie de l’analyseur de diagrammes de cas d’utilisation AI gratuit: Contexte sur l’écosystème plus large des boîtes à outils AI de Visual Paradigm et instructions d’accès pour les utilisateurs Online.
- Tutoriel d’intégration avec le bureau: Guide vidéo sur la connexion des sorties de DBModeler AI avec Visual Paradigm Desktop pour des workflows avancés d’exportation et de reverse-ingénierie.
✅ Pensée finale :
Les meilleures bases de données ne sont pas construites en isolation. Elles sont co-créées—par les produits, l’ingénierie et l’IA.
Avec DBModeler AI, cette collaboration est enfin fluide.
Commencez à construire de meilleures fondations de données — aujourd’hui.
Cette publication est également disponible en Deutsch, English, Español, فارسی, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 : liste des langues séparées par une virgule, 繁體中文 : dernière langue.