













Przez starszego inżyniera full-stack | Raport z doświadczenia zewnętrznej strony z praktycznymi wskazówkami i wpływem na zespół
Wprowadzenie: Dlaczego to narzędzie zmieniło sposób projektowania baz danych
Jako starszy inżynier full-stack w szybko rozwijającym się startupie SaaS, widziałem, jak nasz proces projektowania bazy danych przechodził przez trudne czasy. Od pośpiesznych szkiców na tablicach po ostatnimi chwilami przekształcania schematu, które psuły produkcję, baza danych często była najsłabszym ogniwem w naszym pipeline dostarczania.
Wypróbowaliśmy wszystko: narzędzia ERD, wtyczki do tworzenia diagramów, nawet niestandardowe DSL do definicji schematu. Ale żadne z nich nie naprawdę zniżyło przerwy między intencją biznesową a gotowym do produkcji SQL—szczególnie podczas onboardowania młodych inżynierów lub pracy z niemających technicznych menedżerów produktu.
Potem pojawiło się DBModeler AI od Visual Paradigm.
Po dwutygodniowym testowaniu z moim zespołem mogę powiedzieć bez przesady: to najbardziej przełomowe narzędzie do projektowania baz danych, jakie użyłem w ciągu ostatnich dziesięciu lat.
To nie jest tylko kolejne narzędzie do generowania diagramów z wykorzystaniem AI. To silnik wspólnej pracy nad projektem który przekształca język naturalny w kompletnie znormalizowany, testowalny i dokumentowany schemat bazy danych — wszystko w przeglądarce, bez żadnej konfiguracji.

W tym przewodniku przejdę przez nasze doświadczenie z rzeczywistego świata związane z wykorzystaniem DBModeler AI w trzech kluczowych funkcjach: uwierzytelnianie użytkownika, rejestracja kursów i zarządzanie zamówieniami. Podzielę się tym, co działało, czego nie, oraz jak zintegrowaliśmy to z naszym procesem agile — wraz z zrzutami ekranu, opiniami zespołu i praktycznymi wskazówkami, które możesz od razu zastosować.
Kluczowe koncepcje dla zespołów deweloperskich (Przegląd z kontekstem z rzeczywistego świata)
🎯 AI jako wspierający projektanta, a nie zastępczy
Nasze doświadczenie:
Na początku obawialiśmy się, że AI „nadpisze” nasze starannie opracowane modele. Ale po przetestowaniu zrozumieliśmy, że AI nie zastępuje oceny — on jej zwiększa.
Na przykład, gdy opisaliśmy „student może rejestrować się na wiele kursów”, AI poprawnie wnioskowało o relację wiele do wielu i zaproponowało tabelę pośrednią. Ale byliśmy w stanie edytować kod PlantUML bezpośrednio dodać flagi miękkiego usuwania i znaczniki czasu audytu – coś, co AI nie wygenerowało automatycznie, ale było nam potrzebne w celu zgodności z wymogami.
✅ Wnioski: AI to współpilot, a nie zastępca. Zawsze macie kontrolę nad procesem.
🔁 Iteracyjna poprawa zgodnie z projektem
Nasze doświadczenie:
Podczas implementacji funkcji rejestracji na kursy zaczęliśmy od prostego modelu: Student → Kurs. Po tym, jak AI wygenerowało diagram ERD, zrozumieliśmy, że musimy śledzić status rejestracji (aktywny, wypisany, nieudany). Wróciliśmy do kroku 2, edytowaliśmy klasę Rejestracja w PlantUML i ponownie wygenerowaliśmy schemat w mniej niż 30 sekund.
✅ Wnioski: Cykliczny przepływ pracy nie jest teoretyczny – jest praktyczny. Teraz traktujemy projektowanie schematu jak sprint, a nie jednorazową czynność.
🧪 Testuj przed wdrożeniem – Playground zmienił wszystko
Nasze doświadczenie:
Dawniej pisaliśmy testy integracyjne po wdrożenia schematu. Teraz weryfikujemy zachowanie, zanim napiszemy jedną linię kodu.
W Playgroundzie wygenerowaliśmy 500 przykładowych studentów i zapisaliśmy ich na kursy. Uruchomiliśmy złożone zapytania, takie jak:
SELECT s.name, COUNT(e.id) AS liczba_kursów
FROM studenci s
JOIN rejestracje e ON s.id = e.student_id
WHERE e.status = 'aktywny'
GROUP BY s.name
ORDER BY liczba_kursów DESC;
Zapytanie zwróciło wyniki natychmiast – nie było potrzeby uruchamiania lokalnej bazy danych. Przetestowaliśmy nawet przypadki graniczne: co się stanie, jeśli student wypisze się ze wszystkich kursów? Logika ograniczeń AI zapobiegła powstaniu zaniedbanych rekordów, a my wykryliśmy potencjalny warunek wyścigu na wczesnym etapie.
✅ Wyrok: Playground usunął 80% naszych błędów schematu po wdrożeniu.
📐 Normalizacja jako funkcja pierwszego rzędu
Nasze doświadczenie:
Naszy junior developer był zdezorientowany, dlaczego AI podzieliło Kurs na Kurs i KursNauczyciel. Ale po przejściu kroków 1NF → 2NF → 3NF zrozumiał zrozumiał rozumowanie — zwłaszcza gdy AI pokazało, jak usunięto powtarzające się grupy.
Teraz używamy tego kroku jako moduł szkoleniowy dla nowych pracowników. To jak żywy podręcznik z teorii baz danych.
✅ Wyrok: Normalizacja już nie jest polem wyboru — to nauczalny, widoczny proces.
🌐 Natywne dla przeglądarki, bez kosztów instalacji
Nasze doświadczenie:
Jeden z członków naszego zespołu pracował na laptopie zablokowanym przez firmę bez uprawnień administratora. Nie mógł zainstalować Dockera ani PostgreSQL. Ale dołączył do projektu przez aplikację internetową, stworzył schemat i przyczynił się do projektu w mniej niż 10 minut.
✅ Wyrok: To najbardziej inkluzjowy narząd baz danych, jaki kiedykolwiek używam. Onboarding jest teraz bezproblemowy.
Siedmiokrokowy przepływ AI: Głęboka analiza dla programisty – Nasza podróż zespołu
Krok 1: Wejście problemu (wejście konceptualne)
Nasze polecenie:
„Zbuduj system do zarządzania kursami uczelnianymi, studentami i zapisami. Studenci mogą się zapisać na wiele kursów. Każdy kurs ma jednego prowadzącego. Zapisy śledzą oceny, znaczniki czasu i status (aktywny, wypisany, niezdany). Wszystkie tabele muszą zawierać
utworzono_wizaktualizowano_w.”
Nasze spojrzenie:
Generator opisów AI pomógł nam w dopracowaniu naszego wejścia. Dodałem ograniczenia i zasady biznesowe, które początkowo przeoczyliśmy.
✅ Wskazówka: Używaj punktów listy. AI lepiej je przetwarza niż długie akapity.
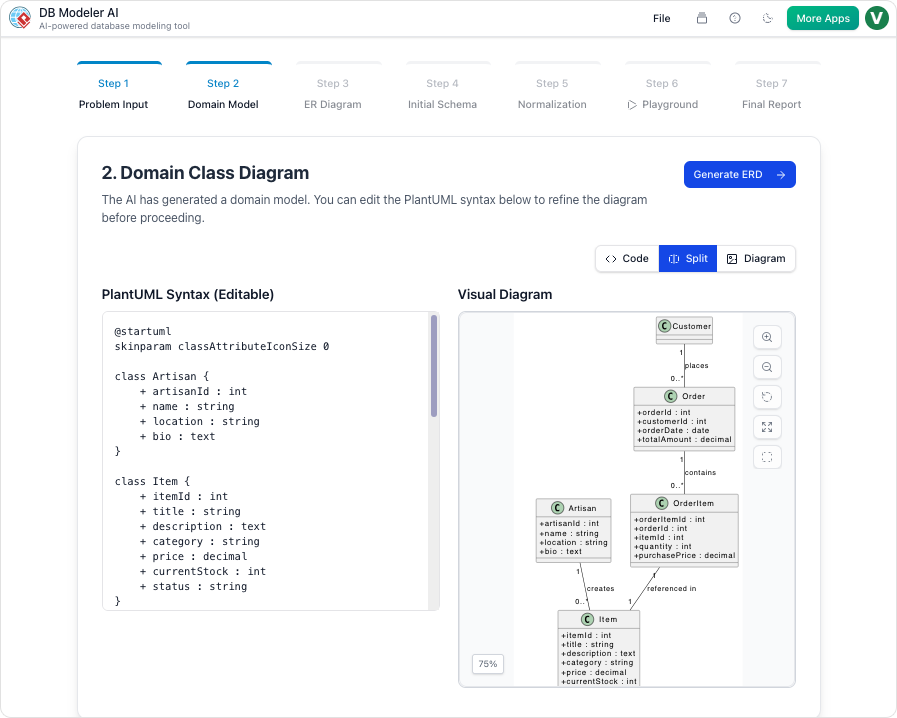
Krok 2: Model domeny (modelowanie konceptualne)
Nasza czynność:
AI wygenerował model domeny oparty na PlantUML. Przemianowaliśmy Student na Użytkownik, dodałem email, rola, oraz is_active atrybuty, oraz wyjaśniłem klasę Zapis klasy.
Nasze spojrzenie:
Wizualna prezentacja była natychmiastowa i czysta. Udostępniliśmy kod PlantUML w Slacku, a zespół frontendowy mógł już zobaczyć strukturę.
✅ Wskazówka: Użyj
@notekomentarze w PlantUML do dokumentowania założeń.
@note right
Ta relacja może wymagać tabeli pośredniej, jeśli dodamy miękkie usuwanie
@end note
Krok 3: Diagram ER (modelowanie logiczne)
Nasze działanie:
AI automatycznie wygenerowało klucze podstawowe, klucze obce i liczności. Zauważyliśmy relację 1:N między Course i Instructor—ale chcieliśmy jeden instruktor na kurs, więc zmieniliśmy ją na 1:1.
Nasze spojrzenie:
Sprawdziliśmy dwukrotnie liczność z zespołem. Błąd tutaj spowodowałby anomalie danych.
✅ Wskazówka: Zawsze weryfikuj relacje z właścicielami produktu przed finalizacją.
Krok 4: Początkowy schemat (generowanie kodu fizycznego)
Nasze działanie:
Wygenerowano DDL PostgreSQL z created_at, updated_at, oraz CHECK ograniczenia.
Nasze zdanie:
Użyliśmy tego jako bazę dla migracji Flyway. Nie ma już ręcznie pisanych DDL — tylko skrypty kontrolowane wersjami.
✅ Wskazówka: Eksportuj DDL jak najszybciej. Przechowujemy folder
schemat/początkowyw Git.
Krok 5: Normalizacja (optymalizacja schematu)
Nasza czynność:
Przeszliśmy przez 1NF → 2NF → 3NF. Na 2NF AI podzielił Zapis na Zapis i HistoriaZapisów w celu usunięcia zależności częściowych.
Nasze zdanie:
Dyskutowaliśmy, czy zostawić to. Pod względem wydajności 3NF była wolniejsza przy łączeniach. Dlatego nieco zdenormalizowaliśmy—dodaliśmy obecna_ocena do Zapis—i zarejestrowaliśmy ten kompromis w Raporcie końcowym.
✅ Wskazówka: Nie przyjmuj bezmyślnie 3NF. Używaj jej do zrozumieć zakłady kompromisów.
Krok 6: Playground (walidacja i testowanie)
Nasze działanie:
Uruchomiliśmy instancję PostgreSQL w przeglądarce. Użyliśmy sztucznej inteligencji do wygenerowania 500 studentów, 100 kursów i 2000 zapisów.
Nasze spojrzenie:
Przeprowadziliśmy test obciążeniowy: 100 równoczesnych zapisów. Schemat wytrzymał. Sprawdziliśmy również:
-
Czy student może zapisać się na ten sam kurs dwukrotnie?
-
Czy instruktor może prowadzić dwa kursy jednocześnie?
Ograniczenia zapobiegły wprowadzeniu danych nieprawidłowych. Zauważyliśmy błąd w naszej logice przed napisaniem kodu backendowego.
✅ Wskazówka: Generuj setki rekordów. Wydajność zapytań ujawnia się dopiero w dużym zakresie.
Krok 7: Ostateczny raport (dokumentacja)
Nasze działanie:
Sztuczna inteligencja wygenerowała raport w formacie Markdown z:
-
Stwierdzenie problemu
-
Diagramy (PNG + PlantUML)
-
Ostateczny schemat
-
Przykładowe
INSERTzapytania
Dodaliśmy sekcję Decyzje projektowe sekcji:
„Zredukowaliśmy normalizację
current_gradew celu uniknięcia JOIN-ów w zapytaniach dotyczących rejestracji w czasie rzeczywistym. Poprawia to wydajność kosztem nieco większej złożoności zapisu.”
Nasze zdanie:
Ten raport stał się naszym dokument onboardingu. Nowi deweloperzy przeczytali go i zrozumieli schemat w ciągu 15 minut.
✅ Wskazówka: Użyj finalnego raportu jako artefakt przekazania do DevOps i QA.
Zasady i najlepsze praktyki: Co nauczyliśmy się z trudem
| Ćwiczenie | Nasza lekcja |
|---|---|
| Zacznij mało | Próbowaliśmy zamodelować całą system uniwersytetu naraz. Nie powiodło się. Teraz dzielimy to na moduły: Użytkownik, Kurs, Zapisy. |
| Kontrola wersji PlantUML | Zatwierdziliśmy pliki PlantUML w Git. Różnice pokazywały ewolucję schematu. Ogromna zaleta dla audytów. |
| Testuj z setkami rekordów | 10 rekordów testowych ukrywa problemy wydajności. Powyżej 500 ujawniło powolne JOIN-y. |
| Dokumentuj założenia | „Brak miękkich usuwań” → później spowodowało błąd. Teraz dokumentujemy każde założenie. |
| Zintegruj z CI/CD | Dodaliśmy skrypt validate-schema.sh który uruchamia pglint w wyeksportowanym DDL. |
Porady i sztuczki dla zaawansowanych użytkowników (Dowodzone skróty naszego zespołu)
🔹 Inżynieria promptów = przewaga
Zamiast:
„Stwórz system bloga”
Teraz używamy:
*”Zaprojektuj schemat PostgreSQL dla platformy blogowej z wieloma klientami, gdzie:
Każdy klient ma izolowane wpisy i komentarze
Wpisy obsługują tagi i publikację zaplanowaną na przyszłość
Komentarze mogą być zagnieżdżone do 3 poziomów
Wszystkie tabele zawierają
utworzono_wizaktualizowano_w“*
Wynik: AI wygenerował schemat zorientowany na klientów z odpowiednią izolacją—co moglibyśmy pominąć ręcznie.
🔹 Używaj komentarzy PlantUML do synchronizacji zespołu
Teraz komentujemy każdą istotną decyzję w PlantUML. Przykład:
' @zespół: Przejrzyj to połączenie — czy powinniśmy dodać flagę `soft_deleted`?
' @arch: Zatwierdzono do wersji 1.2. Doda się w kolejnym sprintie.
Użytkownik "1" -- "0..*" Post : pisze
🔹 Eksportuj wcześnie, eksportuj często
Eksportujemy DDL i Markdown po każdej istotnej iteracji. Mamy schemat/wersje/folder z v1.0.sql, v1.1.sql, itd. Idealne do cofnięcia zmian.
🔹 Połącz z Visual Paradigm Desktop
W przypadku złożonych projektów eksportujemy PlantUML do Desktop, odwrotnie inżynieryjemy istniejące bazy danych i generujemy SQL dla MySQL lub SQL Servera.
🔹 Naucz z krokami normalizacji
Przeprowadzamy „Gry w schemat”, w której młodsi członkowie zespołu przewidują następny krok normalizacji. Wyjaśnienie AI zawsze wygrywa.
Informacje o dostępie, licencjonowaniu i integracji (Nasze ustawienia zespołu)
| Aspekt | Nasze ustawienia |
|---|---|
| Platforma | Dostępne przez przeglądarkę za pośrednictwem Wtyczka Visual Paradigm AI |
| Licencjonowanie | Visual Paradigm Online Combo (wymagane do funkcji AI) |
| Dialekt SQL | PostgreSQL (główny); wydanie Desktop dla MySQL/SQL Server |
| Formaty eksportu | DDL, Markdown, PDF, JSON, PlantUML |
| Współpraca zespołowa | Git + Markdown + wspólne linki do Playground |
| Użycie offline | Nie potrzebne — wersja internetowa jest szybka i niezawodna |
💡 Uwaga dla profesjonalistów: Uaktualniamy do Serwer Teamwork do centralnego zarządzania wersjami modelu i kontroli dostępu. Idealne dla zespołów korporacyjnych.
Wnioski: Przyszłość projektowania baz danych to współpraca, zasilana sztuczną inteligencją i skupiona na człowieku
Po dwóch miesiącach użytkowania w rzeczywistych warunkach, DBModeler AI stał się ważną częścią naszego przepływu pracy programistycznej.
To nie tylko szybsze—jest inteligentniejsze. Zmusza nas do krytycznego myślenia o normalizacji, ograniczeniach i przypadkach brzegowych. Demokratyzuje projektowanie baz danych wśród różnych ról. I to zmniejsza ryzyko kosztownych zmian schematu przez wykrywanie problemów przed osiągnięciem środowiska produkcyjnego.
Najcenniejsze odkrycie? Sztuczna inteligencja nie zastępuje doświadczenia—podnosi je. Nie piszemy mniej kodu. Piszesz lepszy kod, szybciej, z większą pewnością siebie.
Jeśli zmęczyłeś się nieporządnymi, niezdokumentowanymi lub uszkodzonymi schematami—if chcesz projektować bazy danych jak profesjonalista, bez ciężkiego kręgu nauki—to DBModeler AI to nie tylko narzędzie. To przewaga.
Gotowy na przekształcenie swojego przepływu pracy z bazami danych?
👉 Rozpocznij pracę z DBModeler AI
Bez instalacji. Bez konfiguracji. Po prostu wpisz swoją ideę i w kilka minut stwórz schemat gotowy do produkcji.
Zasoby
- DB Modeler AI | Narzędzie do projektowania baz danych zasilane sztuczną inteligencją od Visual Paradigm: Oficjalna strona funkcji opisująca możliwości, przypadki użycia i opcje integracji dla DBModeler AI.
- Opanowanie narzędziem DBModeler AI przez Visual Paradigm: Głęboka instrukcja i przewodnik po przepływie pracy od eksperta społeczności, obejmująca praktyczne strategie wdrażania.
- Strona narzędzia DBModeler AI: Strona startowa interaktywnego narzędzia z często zadawanymi pytaniami, wyróżnieniami funkcji i bezpośredni dostęp do generatora AI.
- Notatki wydania DBModeler AI: Oficjalne dzienniki aktualizacji, ogłoszenia nowych funkcji i historia wersji od Visual Paradigm.
- Przegląd generatora baz danych DBModeler AI: Zwięzły podsumowanie wartości narzędzia i siedmiokrokowego przepływu pracy.
- System zarządzania szpitalami z wykorzystaniem DBModeler AI: Przykład z rzeczywistego świata pokazujący projektowanie bazy danych od początku do końca w dziedzinie medycznej.
- Skarbonka AI Visual Paradigm – aplikacja DBModeler AI: Bezpośredni punkt wejścia do uruchomienia aplikacji DBModeler AI w przeglądarce internetowej.
- Wideo przewodnik po DBModeler AI: Oficjalny filmik instruktażowy pokazujący interfejs, przepływ pracy i kluczowe funkcje w działaniu.
- Wydanie darmowego analizatora diagramów przypadków użycia AI: Informacje o szerokim ekosystemie narzędzi AI Visual Paradigm oraz instrukcje dostępu dla użytkowników Online.
- Poradnik integracji z komputerem stacjonarnym: Filmowy przewodnik łączący wyjścia DBModeler AI z Visual Paradigm Desktop w celu zaawansowanych przepływów eksportu i odwrotnej inżynierii.
✅ Ostateczna myśl:
Najlepsze bazy danych nie są tworzone w izolacji. Są one współtworzone—tworzone wspólnie przez produkt, inżynierię i sztuczną inteligencję.
Z DBModeler AI ta współpraca w końcu jest płynna.
Zacznij budować lepsze podstawy danych — dziś.
Ten post dostępny jest również w Deutsch, English, Español, فارسی, Français, English, Bahasa Indonesia, 日本語, Portuguese, Ру́сский, Việt Nam, 简体中文 and 繁體中文