













एक सीनियर फुल-स्टैक इंजीनियर द्वारा | व्यावहारिक दृष्टिकोण और टीम प्रभाव के साथ तीसरे पक्ष का अनुभव रिपोर्ट
परिचय: इस उपकरण ने हमारे डेटाबेस डिजाइन के तरीके को क्यों बदल दिया
एक तेजी से बढ़ रहे SaaS स्टार्टअप पर एक सीनियर फुल-स्टैक विकासकर्ता के रूप में, मैंने देखा है कि हमारी डेटाबेस डिजाइन प्रक्रिया को बहुत तनाव में डाला गया। व्हाइटबोर्ड पर जल्दबाजी में बनाए गए ड्राफ्ट से लेकर उत्पादन में तोड़ने वाले आखिरी मिनट के स्कीमा रिफैक्टर तक, डेटाबेस अक्सर हमारे डिलीवरी पाइपलाइन में सबसे कमजोर जुड़ाव रहा है।सबसे कमजोर जुड़ावहमारे डिलीवरी पाइपलाइन में।
हमने सब कुछ आजमाया: ERD टूल्स, डायग्रामिंग प्लगइन्स, यहां तक कि स्कीमा परिभाषा के लिए कस्टम DSLs। लेकिन उनमें से कोई भी वास्तव में व्यावहारिक इरादे और उत्पादन-तैयार SQL के बीच के अंतर को भर नहीं पाया—खासकर जब जूनियर इंजीनियर्स के ऑनबोर्डिंग या तकनीकी नहीं जानने वाले उत्पाद प्रबंधकों के साथ काम कर रहे हों।व्यावसायिक इरादाऔरउत्पादन-तैयार SQL—खासकर जब जूनियर इंजीनियर्स के ऑनबोर्डिंग या तकनीकी नहीं जानने वाले उत्पाद प्रबंधकों के साथ काम कर रहे हों।
फिर आयाDBModeler AIVisual Paradigm द्वारा।
मेरी टीम के साथ दो सप्ताह के परीक्षण के बाद, मैं बिना अतिशयोक्ति के कह सकता हूं:यह एक दशक से अधिक समय से मैंने उपयोग किया है, इससे अधिक परिवर्तनकारी डेटाबेस डिजाइन टूल है।
यह केवल एक और AI-संचालित डायग्राम जनरेटर नहीं है। यह एकसहयोगात्मक डिजाइन इंजनहै जो प्राकृतिक भाषा को पूरी तरह से सामान्यीकृत, परीक्षण योग्य और दस्तावेजीकृत डेटाबेस स्कीमा में बदल देता है—सभी ब्राउज़र में, बिना किसी सेटअप के।

इस गाइड में, मैं आपके साथ हमारे वास्तविक दुनिया के अनुभव के बारे में बात करूंगा जब हमने DBModeler AI का उपयोग तीन प्रमुख विशेषताओं—उपयोगकर्ता प्रमाणीकरण, कोर्स नामांकन और आदेश प्रबंधन—में किया। मैं बताऊंगा कि क्या काम करा, क्या नहीं काम करा, और हमने इसे अपने एजाइल वर्कफ्लो में कैसे एकीकृत किया—स्क्रीनशॉट्स, टीम के प्रतिक्रिया और तुरंत लागू करने योग्य टिप्स के साथ।
विकासकर्ता टीमों के लिए मुख्य अवधारणाएं (वास्तविक दुनिया के संदर्भ में फिर से देखा गया)
🎯 AI को एक सहयोगी डिजाइनर के रूप में, एक प्रतिस्थापन के रूप में नहीं
हमारा अनुभव:
हमने शुरू में डर लिया कि AI हमारे ध्यान से बनाए गए मॉडल को “ओवरराइट” कर देगा। लेकिन परीक्षण के बाद हमें एहसास हुआ कि AI नहीं करता हैप्रतिस्थापित करता हैतर्क—यहइसकी शक्ति बढ़ाता है.
उदाहरण के लिए, जब हमने एक “छात्र एक से अधिक कोर्स में नामांकन कर सकता है” का वर्णन किया, तो AI ने सही ढंग से बहु-से-बहु संबंध का निष्कर्ष निकाला और एक जंक्शन टेबल का सुझाव दिया। लेकिन हम सक्षम थे प्लांटयूएमएल को कोड सीधे संपादित करना नरम-हटाने के फ्लैग और ऑडिट समयांक जोड़ने के लिए—जो कि AI ने स्वचालित रूप से उत्पन्न नहीं किया था, लेकिन हमें संगति के लिए आवश्यक था।
✅ निर्णय: AI एक सह-चालक है, एक प्रतिस्थापन नहीं। आप हमेशा नियंत्रण में हैं।
🔁 डिज़ाइन के अनुसार चरणबद्ध सुधार
हमार pengalaman:
कोर्स नामांकन फीचर के दौरान, हमने एक सरल मॉडल से शुरुआत की: छात्र → कोर्स. AI द्वारा एरडी उत्पन्न करने के बाद, हमें यह बताया कि हमें ट्रैक करने की आवश्यकता थी नामांकन स्थिति (सक्रिय, छोड़ दिया गया, विफल)। हम चरण 2 पर वापस गए, और प्लांटयूएमएल में नामांकन क्लास को संपादित किया, और 30 सेकंड से कम समय में स्कीमा को पुनर्जनित किया।
✅ निर्णय: चक्रीय वर्कफ्लो सिर्फ सैद्धांतिक नहीं है—यह व्यावहारिक है। अब हम स्कीमा डिज़ाइन को एक स्प्रिंट की तरह लेते हैं, एक बार के कार्य की तरह नहीं।
🧪 आपके डेप्लॉय करने से पहले परीक्षण करें – प्लेग्राउंड ने सब कुछ बदल दिया
हमार pengalaman:
हम पहले इंटीग्रेशन टेस्ट लिखते थे बाद में स्कीमा डेप्लॉय करने के बाद। अब, हम एक भी कोड लाइन लिखने से पहले व्यवहार की पुष्टि करते हैं.
प्लेग्राउंड में, हमने 500 नमूना छात्र उत्पन्न किए और उन्हें कोर्स में नामांकित किया। हमने जटिल क्वेरीज़ जैसे चलाईं:
SELECT s.name, COUNT(e.id) AS course_count
FROM students s
JOIN enrollments e ON s.id = e.student_id
WHERE e.status = 'active'
GROUP BY s.name
ORDER BY course_count DESC;
क्वेरी ने परिणाम तुरंत लौटाए—स्थानीय डीबी चालू करने की आवश्यकता नहीं थी। हमने एक सीमा मामले का भी परीक्षण किया: यदि एक छात्र सभी कोर्स छोड़ देता है तो क्या होता है? AI के नियम तंत्र ने असंगत रिकॉर्ड को रोका, और हमने एक संभावित रेस कंडीशन को जल्दी ही पकड़ लिया।
✅ फैसला: प्लेग्राउंड ने हमारे डेप्लॉयमेंट के बाद के स्कीमा बग्स का 80% हिस्सा खत्म कर दिया।
📐 नॉर्मलाइजेशन एक प्रथम श्रेणी की सुविधा के रूप में
हमारा अनुभव:
हमारे जूनियर डेवलपर को यह समझने में भ्रम था कि AI ने क्यों विभाजित किया कोर्स में कोर्स और कोर्सइन्स्ट्रक्टर. लेकिन 1NF → 2NF → 3NF चरणों के माध्यम से चलने के बाद, उन्हें समझ आया तर्क—खासकर जब AI ने दिखाया कि दोहराए जाने वाले समूह कैसे हटाए गए।
अब हम इस चरण का उपयोग एक प्रशिक्षण मॉड्यूल नए कर्मचारियों के लिए। यह डेटाबेस सिद्धांत पर एक लाइव पुस्तक की तरह है।
✅ फैसला: नॉर्मलाइजेशन अब एक चेकबॉक्स नहीं है—यह एक सिखाने योग्य, दिखाई देने वाली प्रक्रिया है।
🌐 ब्राउज़र-नेटिव, कोई इंस्टॉलेशन ओवरहेड नहीं
हमारा अनुभव:
हमारे टीम के एक सदस्य के पास कंपनी-लॉक्ड लैपटॉप था जिस पर कोई एडमिन अधिकार नहीं था। उन्हें Docker या PostgreSQL इंस्टॉल नहीं करने दिया गया। लेकिन वे वेब ऐप के माध्यम से प्रोजेक्ट में शामिल हुए, स्कीमा बनाया, और 10 मिनट से कम समय में डिज़ाइन में योगदान दिया।
✅ फैसला: यह वह सबसे अधिक समावेशी डेटाबेस टूल है जो मैंने कभी उपयोग किया है। अब ऑनबोर्डिंग बिना किसी दिक्कत के हो रही है।
7-चरण का एआई वर्कफ्लो: एक डेवलपर की गहन जांच – हमारी टीम की यात्रा
चरण 1: समस्या इनपुट (अवधारणात्मक इनपुट)
हमारा प्रॉम्प्ट:
“विश्वविद्यालय के कोर्स, छात्र और नामांकन को प्रबंधित करने के लिए एक प्रणाली बनाएं। छात्र एक से अधिक कोर्स में नामांकित हो सकते हैं। प्रत्येक कोर्स के लिए एक इंस्ट्रक्टर होता है। नामांकन में ग्रेड, समयचिह्न और स्थिति (सक्रिय, छोड़ दिया गया, असफल) का ट्रैक रखा जाता है। सभी टेबल में शामिल होना चाहिए
बनाए गए_समयऔरअद्यतनित_समय.”
हमारा मत:
एआई के वर्णन जनरेटर ने हमें हमारे इनपुट को बेहतर बनाने में मदद की। हमने वे सीमाएं और व्यापार नियम जोड़े जिन्हें हमने शुरू में नजरअंदाज कर दिया था।
✅ टिप्पणी: बुलेट पॉइंट्स का उपयोग करें। एआई लंबे पैराग्राफ की तुलना में उन्हें बेहतर तरीके से पार्स करता है।
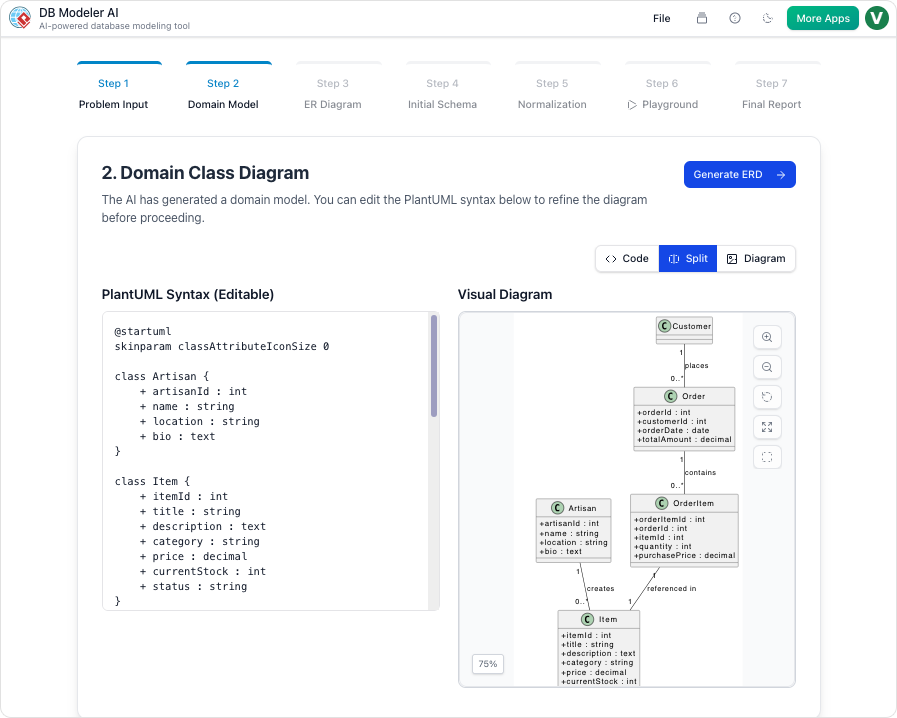
चरण 2: डोमेन मॉडल (अवधारणात्मक मॉडलिंग)
हमारा कार्य:
एआई ने प्लांटयूएमएल आधारित डोमेन मॉडल बनाया। हमने छात्र को उपयोगकर्ता, जोड़ा ईमेल, भूमिका, और सक्रिय_है विशेषताएं, और नामांकन वर्ग को स्पष्ट किया।
हमारा मत:
दृश्य प्रदर्शन तुरंत और स्पष्ट था। हमने प्लांटयूएमएल कोड को स्लैक में साझा किया, और हमारी फ्रंटएंड टीम को पहले से ही संरचना दिख रही थी।
✅ टिप: उपयोग करें
@नोटPlantUML में टिप्पणियाँ धारणाओं को दस्तावेज़ करने के लिए।
@note दाएं
यदि हम सॉफ्ट डिलीट जोड़ते हैं, तो इस संबंध के लिए जंक्शन टेबल की आवश्यकता हो सकती है
@end note
चरण 3: ईआर आरेख (तार्किक मॉडलिंग)
हमारी कार्रवाई:
AI ने स्वचालित रूप से पीकेएस, एफकेएस और कार्डिनैलिटी उत्पन्न की। हमने देखा कि कोर्स और इंस्ट्रक्टर—लेकिन हम चाहते थे प्रत्येक कोर्स के लिए एक इंस्ट्रक्टर, इसलिए हमने इसे 1:1.
हमारा मत:
हमने टीम के साथ कार्डिनैलिटी की दोहरी जांच की। यहाँ गलती करने से डेटा विचलन होते।
✅ टिप: अंतिम रूप देने से पहले हमेशा संबंधों की पुष्टि प्रोडक्ट ओनर्स के साथ करें।
चरण 4: प्रारंभिक स्कीमा (भौतिक कोड उत्पादन)
हमारी कार्रवाई:
PostgreSQL DDL के साथ उत्पन्न किया, जिसमें बनाए गए_समय, अद्यतनित_समय, और चेक प्रतिबंध।
हमारा मत:
हमने इसे बेसलाइन के रूप में उपयोग कियाफ्लाईवे माइग्रेशन के लिए बेसलाइन। अब तक लिखे गए DDL नहीं—केवल संस्करण नियंत्रित स्क्रिप्ट।
✅ टिप्पणी: जल्दी से DDL निर्यात करें। हम एक रखते हैं
स्कीमा/प्रारंभिकफोल्डर गिट में।
चरण 5: सामान्यीकरण (स्कीमा अनुकूलन)
हमारी कार्रवाई:
हमने 1NF → 2NF → 3NF के माध्यम से गुजरा। 2NF पर, एआई ने विभाजित कियापंजीकरण में पंजीकरण और पंजीकरण इतिहास आंशिक निर्भरता को दूर करने के लिए।
हमारा मत:
हमने यह रखने के बारे में चर्चा की। प्रदर्शन के मामले में, 3NF जॉइन के लिए धीमा था। इसलिए हमने थोड़ा असामान्य कर दिया—जोड़ा वर्तमान ग्रेड को पंजीकरण—और अंतिम रिपोर्ट में विनिमय को दर्ज किया।
✅ टिप्पणी: 3NF को अनियंत्रित रूप से स्वीकार न करें। इसका उपयोग करें समझें व्यापार करने वाले।
चरण 6: प्लेग्राउंड (प्रमाणीकरण और परीक्षण)
हमारी कार्रवाई:
हमने ब्राउज़र में PostgreSQL इंस्टेंस लॉन्च किया। AI का उपयोग करके 500 छात्रों, 100 कोर्सेज़ और 2,000 नामांकनों का उत्पादन किया।
हमारा मत:
हमने एक तनाव परीक्षण चलाया: 100 समानांतर नामांकन। स्कीमा बना रहा। हमने यह भी परीक्षण किया:
-
क्या एक छात्र एक ही कोर्स में दो बार नामांकन कर सकता है?
-
क्या एक संचालक एक साथ दो कोर्सेज़ पढ़ा सकता है?
प्रतिबंधों ने अमान्य डेटा को रोका। हमने अपनी तर्क में एक बग पकड़ापहले बैकएंड कोड लिखने से
✅ टिप: सैकड़ों रिकॉर्ड उत्पन्न करें। क्वेरी प्रदर्शन केवल स्केल पर ही प्रकट होता है।
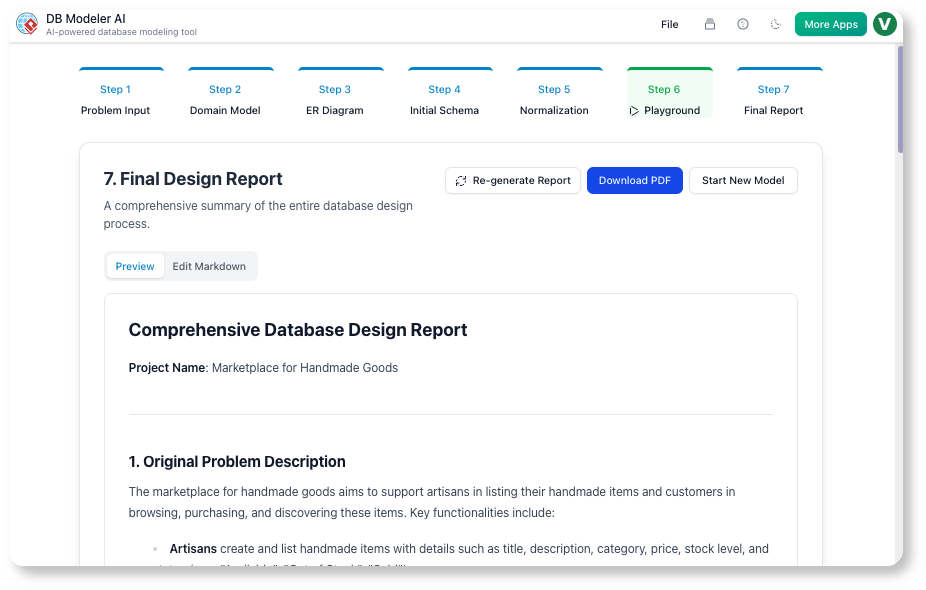
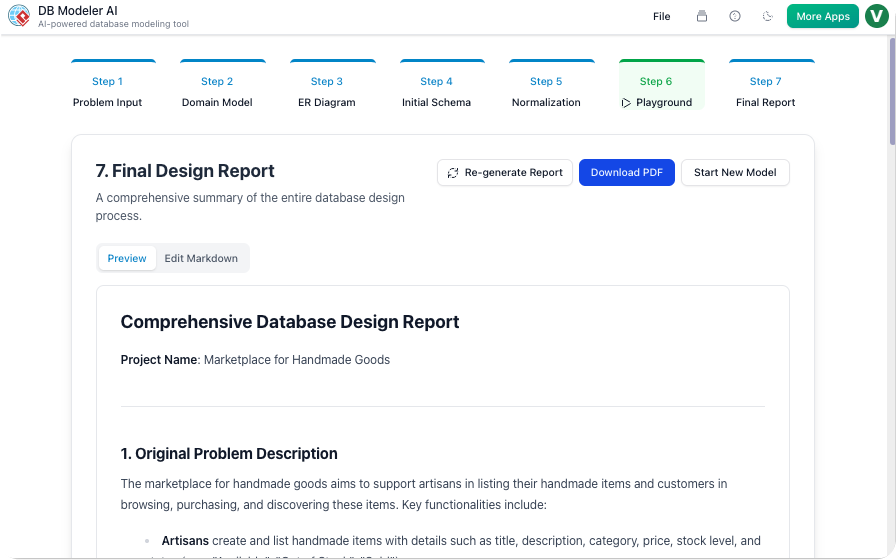
चरण 7: अंतिम रिपोर्ट (दस्तावेज़ीकरण)
हमारी कार्रवाई:
AI ने मार्कडाउन रिपोर्ट बनाई जिसमें शामिल थे:
-
समस्या कथन
-
चित्र (PNG + PlantUML)
-
अंतिम स्कीमा
-
नमूना
INSERTकथन
हमने एक डिज़ाइन निर्णय खंड:
“हमने
current_gradeरियल-टाइम नामांकन प्रश्नों में JOINs से बचने के लिए। इससे प्रदर्शन में सुधार होता है, लेकिन लिखने की जटिलता थोड़ी बढ़ जाती है।”
हमारा मत:
इस रिपोर्ट को हमारा बन गया ऑनबोर्डिंग दस्तावेज़. नए डेवलपर्स ने इसे पढ़ा और 15 मिनट में स्कीमा को समझ लिया।
✅ टिप्पणी: अंतिम रिपोर्ट का उपयोग एक के रूप में करें हैंडऑफ एज़िक्ट डेवोप्स और क्वालिटी एसुरेंस को।
निर्देश और बेस्ट प्रैक्टिसेज़: जिस तरह से हमने कठिनाई से सीखा
| अभ्यास | हमारा सबक |
|---|---|
| छोटे से शुरू करें | हमने पूरे विश्वविद्यालय प्रणाली को एक ही बार में मॉडल करने की कोशिश की। विफल। अब हम इसे मॉड्यूल में बांटते हैं: उपयोगकर्ता, पाठ्यक्रम, नामांकन. |
| वर्जन नियंत्रण प्लांटयूएमएल | हमने प्लांटयूएमएल फ़ाइलों को गिट में कमिट किया। डिफ़्स ने स्कीमा विकास को दिखाया। ऑडिट के लिए बड़ी सफलता। |
| सैकड़ों रिकॉर्ड्स के साथ टेस्ट करें | 10 टेस्ट रिकॉर्ड्स प्रदर्शन समस्याओं को छिपाते हैं। 500+ ने धीमे जॉइन्स को उजागर किया। |
| मान्यताओं को दस्तावेज़ करें | “कोई सॉफ्ट डिलीट नहीं” → बाद में एक बग का कारण बना। अब हम हर मान्यता को दस्तावेज़ करते हैं। |
| सीआई/सीडी के साथ एकीकृत करें | हमने एक जोड़ा validate-schema.sh स्क्रिप्ट जो चलती है पीजीलिंट निर्यातित डीडीएल पर। |
पावर उपयोगकर्ताओं के लिए टिप्स और ट्रिक्स (हमारी टीम के साबित शॉर्टकट्स)
🔹 प्रॉम्प्ट इंजीनियरिंग = गेम-चेंजर
बजाय इसके:
“एक ब्लॉग सिस्टम बनाएं”
हम अब उपयोग करते हैं:
*”एक मल्टी-टेंटेंट ब्लॉग प्लेटफॉर्म के लिए पोस्टग्रेसक्वल स्कीमा डिज़ाइन करें जहां:
प्रत्येक टेंटेंट के अलग-अलग पोस्ट और कमेंट हैं
पोस्ट टैग और समयबद्ध प्रकाशन का समर्थन करते हैं
कमेंट्स तीन स्तर तक नेस्टेड हो सकते हैं
सभी टेबल में शामिल हैं
निर्माण_समयऔरअद्यतनित_समय“*
परिणाम: आईएआई ने एक टेंटेंट-सचेत स्कीमा जिसमें सही अलगाव है—जो हमें हाथ से छूट जाता।
🔹 टीम सिंक के लिए प्लांटयूएमएल कमेंट्स का उपयोग करें
हम अब प्लांटयूएमएल में हर महत्वपूर्ण निर्णय को टिप्पणी करते हैं। उदाहरण:
' @टीम: इस संबंध की समीक्षा करें—क्या हमें `सॉफ्ट_डिलीटेड` फ्लैग जोड़ना चाहिए?
' @आर्क: v1.2 के लिए अनुमोदित। अगले स्प्रिंट में जोड़ा जाएगा।
उपयोगकर्ता "1" -- "0..*" पोस्ट : लिखता है
🔹 जल्दी निर्यात करें, अक्सर निर्यात करें
हम हर महत्वपूर्ण इटरेशन के बाद डीडीएल और मार्कडाउन निर्यात करते हैं। हमारे पास एक स्कीमा/संस्करणों/फ़ोल्डर के साथv1.0.sql, v1.1.sql, आदि। रोलबैक के लिए आदर्श।
🔹 विजुअल पैराडाइम डेस्कटॉप के साथ जोड़ें
जटिल परियोजनाओं के लिए, हम प्लांटयूएमएल को डेस्कटॉप पर निर्यात करते हैं, मौजूदा डीबी को उल्टा डिज़ाइन करते हैं, और माइक्रोसॉफ्ट एसक्यूएल या एसक्यूएल सर्वर के लिए एसक्यूएल उत्पन्न करते हैं।
🔹 नॉर्मलाइज़ेशन स्टेप्स के साथ पढ़ाएं
हम एक “स्कीमा वॉर गेम” चलाते हैं जहां नवीनतम स्टेप के अगले नॉर्मलाइज़ेशन स्टेप की भविष्यवाणी करते हैं। हर बार एआई की व्याख्या जीतती है।
पहुंच, लाइसेंसिंग और एकीकरण नोट्स (हमारी टीम की सेटअप)
| पहलू | हमारी सेटअप |
|---|---|
| प्लेटफॉर्म | वेब-आधारित के माध्यम सेविजुअल पैराडाइम एआई टूलबॉक्स |
| लाइसेंसिंग | विजुअल पैराडाइम ऑनलाइन कॉम्बो (एआई फीचर्स के लिए आवश्यक) |
| एसक्यूएल डायलेक्ट | पोस्टग्रेसक्यूएल (प्राथमिक); माइक्रोसॉफ्ट एसक्यूएल या एसक्यूएल सर्वर के लिए डेस्कटॉप संस्करण |
| निर्यात स्वरूप | DDL, मार्कडाउन, पीडीएफ, जेसॉन, प्लांटयूएमएल |
| टीम सहयोग | जीटी + मार्कडाउन + साझा प्लेग्राउंड लिंक |
| ऑफलाइन उपयोग | आवश्यक नहीं—वेब संस्करण तेज़ और विश्वसनीय है |
💡 प्रो नोट: हम अपग्रेड कर रहे हैं टीमवर्क सर्वर केंद्रीकृत मॉडल संस्करण और पहुँच नियंत्रण के लिए। उद्यम टीमों के लिए आदर्श।
निष्कर्ष: डेटाबेस डिज़ाइन का भविष्य सहयोगात्मक, एआई-संचालित और मानव-केंद्रित है
वास्तविक दुनिया में दो महीने के उपयोग के बाद, डीबीमॉडेलर एआई हमारे विकास कार्यप्रणाली का मुख्य हिस्सा बन गया है.
यह सिर्फ तेज़ नहीं है—यह बुद्धिमान. यह हमें नॉर्मलाइज़ेशन, सीमाएँ और किनारे के मामलों के बारे में आलोचनात्मक सोचने के लिए मजबूर करता है। यह भूमिकाओं के बीच डेटाबेस डिज़ाइन को लोकतांत्रिक बनाता है। और यह महंगे स्कीमा पुनर्निर्माण के जोखिम को कम करता है समस्याओं को पकड़कर पहले उन्हें उत्पादन में पहुँचने से पहले।
सबसे मूल्यवान अंतर्दृष्टि? एआई विशेषज्ञता को नहीं बदलता—यह उसे ऊपर ले जाता है। हम कम कोड नहीं लिख रहे हैं। हम बेहतर कोड, तेज़ी से, अधिक आत्मविश्वास के साथ।
अगर आप गड़बड़, दस्तावेज़हीन या टूटे हुए स्कीमा से थक गए हैं—अगर आप एक पेशेवर की तरह डेटाबेस डिज़ाइन करना चाहते हैं, लेकिन तीव्र सीखने के झंझट से बचना चाहते हैंएक पेशेवर की तरह डेटाबेस डिज़ाइन करें, तीव्र सीखने के झंझट के बिना—तो डीबीमॉडेलर एआई सिर्फ एक उपकरण नहीं है। यह एक खेल बदल देने वाला है।
क्या आप अपने डेटाबेस कार्यप्रणाली को बदलने के लिए तैयार हैं?
👉 डीबीमॉडेलर एआई के साथ शुरुआत करें
कोई इंस्टॉलेशन नहीं। कोई सेटअप नहीं। बस अपने विचार को टाइप करें और मिनटों में उत्पादन के लिए तैयार स्कीमा बनाएं।
संदर्भ
- डीबी मॉडेलर एआई | विजुअल पैराडाइम द्वारा एआई-संचालित डेटाबेस डिज़ाइन टूल: डीबीमॉडेलर एआई के क्षमताओं, उपयोग के मामलों और एकीकरण विकल्पों का विवरण देने वाला आधिकारिक फीचर पेज।
- Visual Paradigm द्वारा DBModeler AI को समझना: समुदाय के एक विशेषज्ञ द्वारा गहन पाठ्यक्रम और कार्यप्रवाह चलाना, जो व्यावहारिक कार्यान्वयन रणनीतियों को कवर करता है।
- DBModeler AI टूल पेज: एफ़क्यूएस, विशेषताओं के उल्लेख और AI जनरेटर तक सीधे पहुंच के साथ इंटरैक्टिव टूल लैंडिंग पेज।
- DBModeler AI रिलीज नोट्स: Visual Paradigm से आधिकारिक अपडेट लॉग, नए फीचर घोषणाएं और संस्करण इतिहास।
- DBModeler AI डेटाबेस जनरेटर ओवरव्यू: टूल के मूल्य प्रस्ताव और 7-चरणीय कार्यप्रवाह का संक्षिप्त सारांश।
- DBModeler AI के साथ अस्पताल प्रबंधन प्रणाली: स्वास्थ्य क्षेत्र के लिए संपूर्ण डेटाबेस डिजाइन को दर्शाने वाला वास्तविक दुनिया का केस स्टडी।
- Visual Paradigm AI टूलबॉक्स – DBModeler AI ऐप: वेब-आधारित DBModeler AI ऐप लॉन्च करने के लिए सीधा प्रवेश बिंदु।
- DBModeler AI वीडियो वॉकथ्रू: इंटरफेस, कार्यप्रवाह और मुख्य विशेषताओं को कार्यान्वयन में दिखाने वाला आधिकारिक वीडियो ट्यूटोरियल।
- मुफ्त AI उपयोग केस डायग्राम विश्लेषक रिलीज: Visual Paradigm के विस्तृत AI टूलबॉक्स प्रणाली के संदर्भ और ऑनलाइन उपयोगकर्ताओं के लिए पहुंच निर्देश।
- डेस्कटॉप एकीकरण ट्यूटोरियल: DBModeler AI आउटपुट को उन्नत निर्यात और उल्टा डिजाइन कार्यप्रवाह के लिए Visual Paradigm डेस्कटॉप के साथ जोड़ने के लिए वीडियो गाइड।
✅ अंतिम विचार:
सर्वश्रेष्ठ डेटाबेस अलगाव में नहीं बनाए जाते हैं। वे हैं सह-निर्मित—उत्पाद, इंजीनियरिंग और एआई द्वारा।
DBModeler AI के साथ, यह सहयोग अंततः निर्विघ्न है।
आज ही बेहतर डेटा आधार बनाना शुरू करें।
यह पोस्ट Deutsch, English, Español, فارسی, Français, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 और 繁體中文 में भी उपलब्ध है।