













由資深全端工程師撰寫 | 第三方實務經驗報告,包含實用洞察與團隊影響
引言:為何這項工具改變了我們設計資料庫的方式
作為一家快速發展的 SaaS 新創公司的資深全端工程師,我見證了我們資料庫設計流程的煎熬歷程。從白板上匆忙草擬的圖稿,到臨時緊急重構資料結構導致生產環境崩潰,資料庫經常是我們交付流程中的 最弱的一環交付流程中的弱點。
我們試過所有方法:ERD 工具、圖示插件,甚至為資料結構定義設計的自訂 DSL。但沒有一個真正彌補了 商業意圖與 可投入生產的 SQL——特別是在招募新手工程師或與非技術背景的產品經理合作時。
直到 DBModeler AI由 Visual Paradigm 推出。
在與團隊進行兩週試用後,我毫不誇張地說: 這是我十年來使用過最具轉變性的資料庫設計工具。
這不只是另一個由 AI 驅動的圖示生成工具。它是一個 協作式設計引擎能將自然語言轉化為完全規範化、可測試且具文件化的資料庫結構——全部在瀏覽器中完成,無需任何設定。

在本指南中,我將帶你走過我們在三個主要功能上使用 DBModeler AI 的真實經驗:使用者驗證、課程註冊與訂單管理。我會分享哪些做法有效、哪些無效,以及我們如何將其整合進敏捷工作流程——包含截圖、團隊反饋,以及你可以立即應用的實用建議。
開發團隊的關鍵概念 (結合真實世界情境重新探討)
🎯 AI 是協作設計者,而非取代者
我們的經驗:
我們最初擔心 AI 會「覆寫」我們精心設計的模型。但經過測試後,我們發現 AI 並不會 取代判斷力——它反而 強化判斷力.
例如,當我們描述「學生可以註冊多門課程」時,AI正確地推斷出多對多關係,並建議建立一個關聯表。但我們能夠直接編輯 PlantUML 程式碼以新增軟刪除標記和稽核時間戳——這一點是 AI 未自動產生的,但我們為了合規性必須加入。
✅ 結論:AI 是副駕駛,而非替代者。你始終掌握控制權。
🔁 設計上的迭代優化
我們的經驗:
在課程註冊功能的開發過程中,我們從一個簡單的模型開始:學生 → 課程。在 AI 產生實體關係圖後,我們意識到需要追蹤註冊狀態(活躍、退選、失敗)。我們回到第二步,編輯了註冊類別的 PlantUML 程式碼,並在不到 30 秒內重新產生資料結構。
✅ 結論:這種循環式工作流程並非理論上的構想——而是實際可行的。現在我們將資料結構設計視為一個迭代的 Sprint,而非一次性任務。
🧪 部署前先測試——沙盒環境徹底改變了一切
我們的經驗:
我們過去總是在資料結構部署後才撰寫整合測試。現在,我們在撰寫任何程式碼之前就先驗證行為在撰寫任何程式碼之前就驗證行為.
在沙盒環境中,我們產生了 500 名示例學生並為他們註冊課程。我們執行了複雜的查詢,例如:
SELECT s.name, COUNT(e.id) AS course_count
FROM students s
JOIN enrollments e ON s.id = e.student_id
WHERE e.status = 'active'
GROUP BY s.name
ORDER BY course_count DESC;
查詢結果立即回傳——無需啟動本地資料庫。我們甚至測試了邊界情況:如果一名學生退掉所有課程會發生什麼?AI 的約束邏輯防止了孤立記錄的產生,我們也提早發現了潛在的競爭條件。
✅ 判決: Playground 消除了我們部署後 80% 的資料結構錯誤。
📐 標準化作為一等特性
我們的經驗:
我們的資深開發人員對 AI 為何將其拆分感到困惑課程 拆分為 課程 和 課程講師。但在走完 1NF → 2NF → 3NF 的步驟後,他們 理解了 其中的邏輯——特別是當 AI 展示如何消除重複群組時。
我們現在將這一步驟作為一個 訓練模組 用於新進員工。這就像一本活生生的資料庫理論教科書。
✅ 判決: 標準化不再只是一個勾選框——它是一個可教學、可見的流程。
🌐 瀏覽器原生,無安裝負擔
我們的經驗:
我們團隊中的一位成員使用的是公司鎖定的筆電,沒有管理員權限。他們無法安裝 Docker 或 PostgreSQL。但他們 透過網頁應用程式加入專案,建立資料結構,並在不到十分鐘內參與設計。
✅ 判決: 這是我用過最具包容性的資料庫工具。入職流程現在完全無摩擦。
七步AI工作流程:開發者的深入探討——我們團隊的旅程
步驟 1:問題輸入(概念性輸入)
我們的提示:
「建立一個用於管理大學課程、學生和註冊的系統。學生可以註冊多門課程。每門課程有一位授課教師。註冊記錄應包含成績、時間戳和狀態(活躍、退課、失敗)。所有資料表都必須包含
created_at以及updated_at.”
我們的看法:
AI的描述生成器幫助我們優化了輸入內容。我們補充了最初忽略的約束條件和業務規則。
✅ 提示: 使用項目符號。AI對項目符號的解析效果優於長段落。
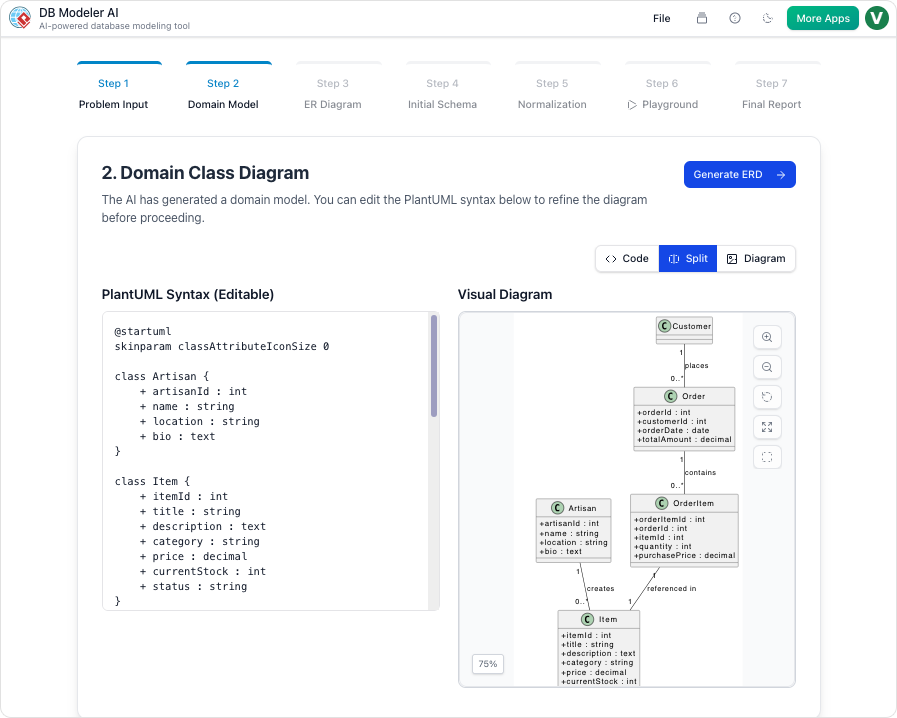
步驟 2:領域模型(概念建模)
我們的行動:
AI生成了一個基於PlantUML的領域模型。我們將 Student 改為 User,新增了 email, role、 is_active 屬性,並明確了 Enrollment 類別。
我們的看法:
視覺化呈現即時且清晰。我們將PlantUML程式碼分享至Slack,前端團隊已能立即看到結構。
✅ 提示: 使用
@note在 PlantUML 中使用註釋來記錄假設。
@note right
如果我們加入軟刪除功能,此關係可能需要一個中繼表
@end note
步驟 3:ER 圖(邏輯建模)
我們的行動:
AI 自動產生主鍵、外鍵和基數。我們注意到 Course 和 Instructor——但我們希望 每門課程僅有一位講師,因此我們將其調整為 1:1.
我們的看法:
我們與團隊再次確認了基數。這裡的任何錯誤都可能導致資料異常。
✅ 提示: 在最終確定前,務必與產品負責人驗證關係。
步驟 4:初始模式(物理代碼生成)
我們的行動:
使用 created_at, updated_at,以及 CHECK 約束。
我們的看法:
我們將此作為 Flyway 迁移的基線。不再手動編寫 DDL——僅使用版本控制的腳本。
✅ 提示: 盡早導出 DDL。我們在 Git 中保留一個
schema/initial資料夾。
步驟 5:規範化(資料庫結構優化)
我們的行動:
我們逐一檢視 1NF → 2NF → 3NF。在 2NF 時,AI 將 Enrollment 拆分為 Enrollment 和 EnrollmentHistory 以消除部分依賴。
我們的看法:
我們曾討論是否保留它。就效能而言,3NF 在連接操作上較慢。因此我們 稍微去規範化——新增 current_grade 至 Enrollment——並在最終報告中記錄了此權衡。
✅ 提示: 不要盲目接受 3NF。應利用它來 理解 權衡取捨。
步驟 6:沙盒環境(驗證與測試)
我們的行動:
我們啟動了瀏覽器內的 PostgreSQL 實例。使用 AI 生成了 500 名學生、100 門課程和 2,000 次註冊。
我們的看法:
我們執行了壓力測試:100 次同時註冊。資料結構保持穩定。我們還測試了:
-
學生能否重複註冊同一門課程?
-
一名講師能否同時教授兩門課程?
這些約束阻止了無效資料的輸入。我們在撰寫後端程式碼之前發現了一個邏輯錯誤之前 撰寫後端程式碼。
✅ 提示: 生成數百筆記錄。查詢效能只有在大量資料下才會顯現。
步驟 7:最終報告(文件化)
我們的行動:
AI 生成了一份 Markdown 格式的報告,內容包括:
-
問題陳述
-
圖表(PNG + PlantUML)
-
最終資料結構
-
範例
INSERT語句
我們新增了一個 設計決策 章節:
「我們將
current_grade去規範化,以避免即時註冊查詢中的 JOIN 操作。這提升了效能,但帶來了稍高的寫入複雜度。」
我們的看法:
這份報告成為了我們的 入職文件。新開發人員閱讀後,15分鐘內就理解了資料結構。
✅ 小提示: 使用最終報告作為 交接文件 提供給 DevOps 和 QA。
指南與最佳實務:我們吃過苦頭才學到的
| 實踐 | 我們的教訓 |
|---|---|
| 從小處著手 | 我們試圖一次建構整個大學系統。失敗了。現在我們將它拆分成模組: 使用者, 課程, 註冊. |
| 使用版本控制管理 PlantUML | 我們將 PlantUML 檔案提交至 Git。差異比對清楚顯示了資料結構的演進歷程。對審計而言是巨大的優勢。 |
| 使用數百筆資料進行測試 | 僅使用10筆測試資料會隱藏效能問題。超過500筆才暴露出緩慢的 JOIN 操作。 |
| 記錄假設 | 「不使用軟刪除」→ 後來導致了錯誤。現在我們會記錄每一項假設。 |
| 與 CI/CD 整合 | 我們新增了一個 validate-schema.sh 腳本,用來執行 pglint在匯出的 DDL 上。 |
進階使用者的技巧與訣竅 (我們團隊驗證過的捷徑)
🔹 提示工程 = 改變遊戲規則的關鍵
而不是:
「建立一個部落格系統」
我們現在使用:
*「設計一個適用於多租戶部落格平台的 PostgreSQL 資料結構,其中:
每個租戶擁有獨立的文章與留言
文章支援標籤與排程發佈
留言可巢狀至多 3 層
所有資料表皆包含
created_at以及updated_at“*
結果:AI 產生了一個具租戶感知的資料結構,並具備適當的隔離——這正是我們手動設計時可能會忽略的部分。
🔹 使用 PlantUML 註解進行團隊同步
我們現在在 PlantUML 中註解每一項重要決策。範例:
' @team: 請審查此關係——我們是否應加入 `soft_deleted` 標記?
' @arch: 已核准用於 v1.2。將在下一個衝刺中加入。
User "1" -- "0..*" Post : 寫作
🔹 盡早匯出,經常匯出
我們在每次主要迭代後都會匯出 DDL 與 Markdown。我們有一個schema/versions/包含資料夾v1.0.sql, v1.1.sql等,非常適合用於回滾。
🔹 搭配 Visual Paradigm Desktop 使用
對於複雜專案,我們將 PlantUML 匯出至 Desktop,反向工程現有的資料庫,並為 MySQL 或 SQL Server 產生 SQL。
🔹 透過規範化步驟進行教學
我們進行「結構戰爭遊戲」,讓初學者預測下一個規範化步驟。AI 的解釋總是勝出。
存取、授權與整合注意事項 (我們團隊的設定)
| 面向 | 我們的設定 |
|---|---|
| 平台 | 透過 Web 基於Visual Paradigm AI 工具箱 |
| 授權 | Visual Paradigm Online Combo(AI 功能所需) |
| SQL 語言 | PostgreSQL(主要);MySQL/SQL Server 使用桌面版 |
| 匯出格式 | DDL、Markdown、PDF、JSON、PlantUML |
| 團隊協作 | Git + Markdown + 共享的 Playground 連結 |
| 離線使用 | 不需要——網頁版本快速且可靠 |
💡 專業注意事項:我們正在升級至Teamwork Server用於集中化的模型版本控制和存取權限管理。非常適合企業團隊。
結論:資料庫設計的未來是協作式、人工智慧驅動且以人為本的
經過兩個月的實際使用後,DBModeler AI 已成為我們開發流程的核心部分.
它不僅更快,而且更聰明。它迫使我們深入思考資料庫正規化、約束條件與邊界情況。它讓不同角色都能參與資料庫設計。而且它降低耗費高昂的資料結構重構風險透過在問題進入生產環境前就發現它們之前就可降低風險。
最有價值的洞察是?人工智慧不會取代專業知識,而是提升它。我們並未撰寫更少的程式碼。我們正在撰寫更好的程式碼,更快,且更有信心。
如果你厭倦了雜亂無章、缺乏文件或已損壞的資料結構——如果你希望以專業水準設計資料庫,卻不必經歷陡峭的學習曲線——那麼DBModeler AI 不僅是一項工具,更是一場遊戲規則的改變。
準備好改變你的資料庫工作流程了嗎?
👉 立即開始使用 DBModeler AI
無需安裝。無需設定。只需輸入你的構想,幾分鐘內即可建立可投入生產的資料結構。
參考資料
- DB Modeler AI | 由 Visual Paradigm 提供的人工智慧驅動資料庫設計工具:官方功能頁面,詳細說明 DBModeler AI 的功能、使用案例與整合選項。
- 掌握由 Visual Paradigm 提供的 DBModeler AI:由社區專家提供的深入教程與工作流程導覽,涵蓋實用的實施策略。
- DBModeler AI 工具頁面:具互動功能的工具首頁,包含常見問題、功能亮點,以及直接存取 AI 生成器的入口。
- DBModeler AI 更新說明:由 Visual Paradigm 發布的官方更新日誌、新功能公告與版本歷史。
- DBModeler AI 資料庫生成器概覽:工具價值主張與七步工作流程的簡明總結。
- 結合 DBModeler AI 的醫院管理系統:真實案例研究,展示醫療領域端到端的資料庫設計。
- Visual Paradigm AI 工具箱 – DBModeler AI 應用程式:直接入口,用於啟動基於網頁的 DBModeler AI 應用程式。
- DBModeler AI 影片導覽:官方影片教程,展示介面、工作流程與關鍵功能的實際運作。
- 免費 AI 用例圖分析器發布:關於 Visual Paradigm 更廣泛 AI 工具箱生態系的背景資訊,以及 Online 使用者的存取說明。
- 桌面整合教學:影片指南,說明如何將 DBModeler AI 的輸出與 Visual Paradigm Desktop 連結,以進行進階匯出與逆向工程工作流程。
✅ 最後的想法:
最佳的資料庫並非孤立建構而成。它們是共同創造——由產品、工程與人工智慧共同完成。
有了 DBModeler AI,這種協作終於實現了無縫銜接。
立即開始打造更優質的資料基礎建設——從今天開始。