













Bởi Một Kỹ Sư Full-Stack Cấp Cao | Báo Cáo Kinh Nghiệm Bên Thứ Ba Với Những Góc Nhìn Thực Tế & Tác Động Đến Đội Nhóm
Giới Thiệu: Tại Sao Công Cụ Này Đã Thay Đổi Cách Chúng Tôi Thiết Kế Cơ Sở Dữ Liệu
Là một kỹ sư full-stack cấp cao tại một startup SaaS hoạt động nhanh, tôi đã chứng kiến quy trình thiết kế cơ sở dữ liệu của chúng tôi trải qua nhiều thử thách. Từ những bản phác thảo vội vàng trên bảng trắng đến việc tái cấu trúc lược đồ vào phút cuối khiến hệ thống sản xuất bị sập, cơ sở dữ liệu thường là điểm yếu nhất trong chuỗi cung ứng của chúng tôi.
Chúng tôi đã thử mọi thứ: công cụ ERD, các tiện ích vẽ sơ đồ, thậm chí cả DSL tùy chỉnh để định nghĩa lược đồ. Nhưng không công cụ nào thực sự lấp đầy khoảng cách giữa mục đích kinh doanh và SQL sẵn sàng cho sản xuất—đặc biệt khi đào tạo kỹ sư mới hoặc làm việc cùng các quản lý sản phẩm không chuyên về kỹ thuật.
Rồi đến DBModeler AI do Visual Paradigm phát triển.
Sau hai tuần thử nghiệm cùng đội nhóm của tôi, tôi có thể nói một cách chân thực: đây là công cụ thiết kế cơ sở dữ liệu mang tính cách mạng nhất mà tôi từng sử dụng trong hơn một thập kỷ.
Đây không chỉ là một công cụ sinh sơ đồ dựa trên AI khác. Đây là một động cơ thiết kế hợp tác biến ngôn ngữ tự nhiên thành lược đồ cơ sở dữ liệu được chuẩn hóa hoàn toàn, có thể kiểm thử và được tài liệu hóa đầy đủ—tất cả trong trình duyệt, không cần cài đặt gì thêm.

Trong hướng dẫn này, tôi sẽ dẫn bạn qua trải nghiệm thực tế của chúng tôi khi sử dụng DBModeler AI trên ba tính năng chính: xác thực người dùng, đăng ký khóa học và quản lý đơn hàng. Tôi sẽ chia sẻ những gì hoạt động tốt, những gì không hiệu quả, và cách chúng tôi đã tích hợp nó vào quy trình làm việc theo Agile—đầy đủ hình ảnh chụp màn hình, phản hồi từ đội nhóm và những mẹo thực tế bạn có thể áp dụng ngay lập tức.
Những Khái Niệm Quan Trọng Cho Đội Nhóm Phát Triển (Được Xem Lại Trong Bối Cảnh Thực Tế)
🎯 AI Như Một Nhà Thiết Kế Hợp Tác, Không Phải Là Sự Thay Thế
Trải Nghiệm Của Chúng Tôi:
Ban đầu chúng tôi lo lắng AI sẽ “ghi đè” lên các mô hình được thiết kế cẩn thận của chúng tôi. Nhưng sau khi thử nghiệm, chúng tôi nhận ra AI không thay thế suy luận—nó tăng cường nó.
Ví dụ, khi chúng tôi mô tả một “sinh viên có thể đăng ký nhiều khóa học”, AI đã đúng đắn suy luận mối quan hệ nhiều-đa và đề xuất một bảng liên kết. Nhưng chúng tôi có thể sửa đổi mã PlantUML trực tiếp để thêm cờ xóa mềm và thời điểm ghi nhật ký—một thứ mà AI không tự động tạo ra nhưng chúng tôi cần để tuân thủ.
✅ Kết luận: AI là một người đồng hành, chứ không phải thay thế. Bạn luôn giữ quyền kiểm soát.
🔁 Sửa đổi dần dần theo thiết kế
Kinh nghiệm của chúng tôi:
Trong tính năng đăng ký khóa học, chúng tôi bắt đầu với một mô hình đơn giản: Sinh viên → Khóa học. Sau khi AI tạo sơ đồ ERD, chúng tôi nhận ra mình cần theo dõi trạng thái đăng ký (chưa hoàn thành, bỏ học, trượt). Chúng tôi quay lại Bước 2, chỉnh sửa lớp Đăng ký trong PlantUML, và tái tạo sơ đồ trong vòng dưới 30 giây.
✅ Kết luận: Luồng công việc vòng tròn không phải lý thuyết—nó thực tế. Bây giờ chúng tôi coi thiết kế sơ đồ như một đợt sprint, chứ không phải một công việc duy nhất.
🧪 Kiểm thử trước khi triển khai – Khu vực thử nghiệm đã thay đổi mọi thứ
Kinh nghiệm của chúng tôi:
Trước đây, chúng tôi thường viết các bài kiểm thử tích hợp sau khi sơ đồ được triển khai. Bây giờ, chúng tôi xác minh hành vi trước khi viết một dòng mã nào.
Trong Khu vực thử nghiệm, chúng tôi tạo ra 500 sinh viên mẫu và đăng ký họ vào các khóa học. Chúng tôi chạy các truy vấn phức tạp như:
SELECT s.name, COUNT(e.id) AS so_luong_khoa_hoc
FROM sinh_vien s
JOIN dang_ky e ON s.id = e.sinh_vien_id
WHERE e.trang_thai = 'active'
GROUP BY s.name
ORDER BY so_luong_khoa_hoc DESC;
Truy vấn trả về kết quả ngay lập tức—không cần khởi động cơ sở dữ liệu cục bộ. Chúng tôi thậm chí đã kiểm thử các trường hợp biên: điều gì xảy ra nếu một sinh viên bỏ tất cả các khóa học? Logic ràng buộc của AI đã ngăn chặn các bản ghi bị bỏ rơi, và chúng tôi phát hiện sớm một tình huống cạnh tranh tiềm ẩn.
✅ Phán quyết: Sân chơi đã loại bỏ 80% các lỗi cấu trúc sau triển khai của chúng tôi.
📐 Chuẩn hóa như một tính năng hàng đầu
Kinh nghiệm của chúng tôi:
Lập trình viên mới của chúng tôi bối rối vì sao AI lại chia tách Khóa học thành Khóa học và Giảng viênKhóa học. Nhưng sau khi đi qua các bước 1NF → 2NF → 3NF, họ hiểu được lý do—đặc biệt khi AI cho thấy cách các nhóm lặp lại đã được loại bỏ.
Bây giờ chúng tôi sử dụng bước này như một module đào tạo cho nhân viên mới. Nó giống như một cuốn sách giáo khoa trực tiếp về lý thuyết cơ sở dữ liệu.
✅ Phán quyết: Chuẩn hóa không còn là một mục kiểm tra nữa—nó là một quy trình có thể dạy được và hiển thị rõ ràng.
🌐 Tích hợp trình duyệt, không cần cài đặt
Kinh nghiệm của chúng tôi:
Một thành viên trong nhóm của chúng tôi đang dùng máy tính công ty bị khóa, không có quyền quản trị viên. Họ không thể cài Docker hay PostgreSQL. Nhưng họ tham gia dự án thông qua ứng dụng web, tạo một lược đồ và đóng góp vào thiết kế trong vòng dưới 10 phút.
✅ Phán quyết: Đây là công cụ cơ sở dữ liệu bao gồm nhất mà tôi từng sử dụng. Việc đưa nhân viên mới vào làm việc hiện giờ hoàn toàn trơn tru.
Quy trình AI 7 bước: Cuộc thám hiểm sâu của nhà phát triển – Hành trình của đội ngũ chúng tôi
Bước 1: Nhập vấn đề (Nhập liệu khái niệm)
Lời nhắc của chúng tôi:
“Xây dựng một hệ thống quản lý các khóa học đại học, sinh viên và đăng ký. Sinh viên có thể đăng ký nhiều khóa học. Mỗi khóa học có một giảng viên. Các đăng ký sẽ theo dõi điểm số, thời gian đánh dấu và trạng thái (đang hoạt động, bỏ học, trượt). Tất cả các bảng phải bao gồm
created_atvàupdated_at.”
Nhận xét của chúng tôi:
Trình sinh mô tả của AI đã giúp chúng tôi tinh chỉnh đầu vào của mình. Chúng tôi đã thêm các ràng buộc và quy tắc kinh doanh mà ban đầu chúng tôi đã bỏ qua.
✅ Mẹo: Sử dụng danh sách đánh dấu. AI xử lý chúng tốt hơn so với các đoạn văn dài.
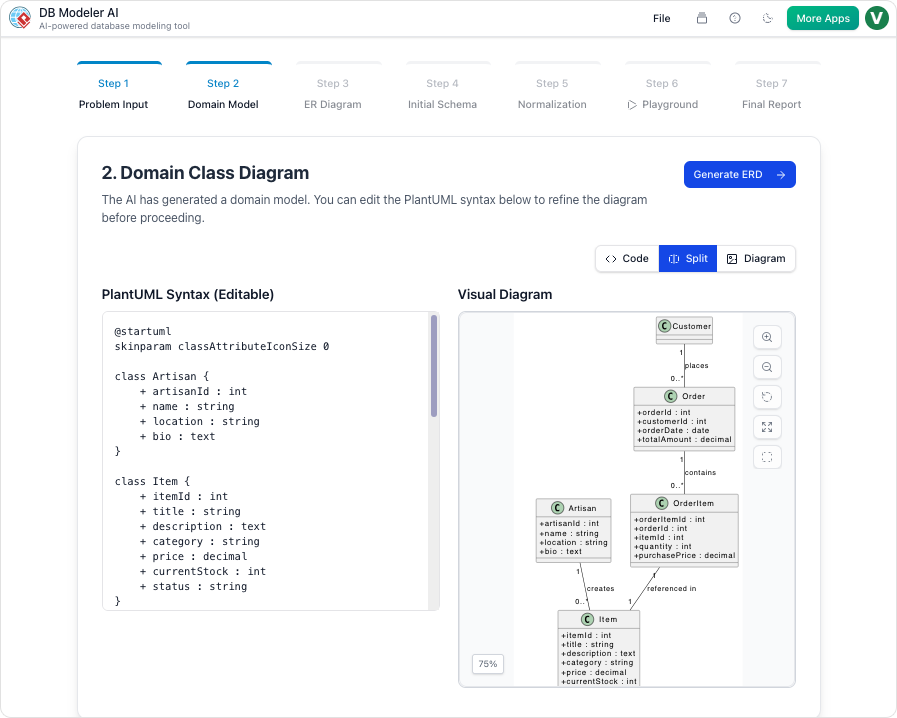
Bước 2: Mô hình miền (Mô hình hóa khái niệm)
Hành động của chúng tôi:
AI đã tạo ra một mô hình miền dựa trên PlantUML. Chúng tôi đã đổi tên Student thành User, thêm email, role, và is_active các thuộc tính, và làm rõ lớp Enrollment lớp.
Nhận xét của chúng tôi:
Bản vẽ trực quan được tạo ngay lập tức và rõ ràng. Chúng tôi đã chia sẻ mã PlantUML trên Slack, và đội ngũ frontend đã có thể nhìn thấy cấu trúc ngay lập tức.
✅ Mẹo: Sử dụng
@notecác chú thích trong PlantUML để tài liệu hóa các giả định.
@note phải
Mối quan hệ này có thể cần một bảng giao điểm nếu chúng ta thêm chức năng xóa mềm
@end note
Bước 3: Sơ đồ ER (Mô hình hóa logic)
Hành động của chúng tôi:
AI tự động sinh các khóa chính, khóa ngoại và các cấp độ quan hệ. Chúng tôi nhận thấy mối quan hệ 1:N giữa Khóa học và Giảng viên—nhưng chúng tôi muốn một giảng viên cho mỗi khóa học, vì vậy chúng tôi đã điều chỉnh nó thành 1:1.
Quan điểm của chúng tôi:
Chúng tôi đã kiểm tra lại cấp độ quan hệ với đội nhóm. Một sai sót ở đây có thể dẫn đến các hiện tượng bất thường trong dữ liệu.
✅ Mẹo: Luôn xác minh các mối quan hệ với người sở hữu sản phẩm trước khi hoàn tất.
Bước 4: Sơ đồ ban đầu (Tạo mã vật lý)
Hành động của chúng tôi:
Tạo DDL PostgreSQL với created_at, updated_at, và CHECK các ràng buộc.
Quan điểm của chúng tôi:
Chúng tôi đã sử dụng điều này làm điểm chuẩn cho các bản cập nhật Flyway. Không còn DDL được viết tay nữa—chỉ còn các tập lệnh được kiểm soát phiên bản.
✅ Mẹo: Xuất DDL sớm. Chúng tôi duy trì một thư mục
schema/initialtrong Git.
Bước 5: Chuẩn hóa (Tối ưu hóa lược đồ)
Hành động của chúng tôi:
Chúng tôi đi qua từng bước 1NF → 2NF → 3NF. Ở 2NF, AI đã chia Enrollment thành Enrollment và EnrollmentHistory để loại bỏ các phụ thuộc riêng phần.
Quan điểm của chúng tôi:
Chúng tôi tranh luận xem có nên giữ lại hay không. Về mặt hiệu suất, 3NF chậm hơn khi thực hiện các phép nối. Vì vậy, chúng tôi giảm mức độ chuẩn hóa một chút—thêm current_grade vào Enrollment—và ghi nhận sự đánh đổi này trong Báo cáo Cuối cùng.
✅ Mẹo: Đừng chấp nhận 3NF một cách máy móc. Sử dụng nó để hiểu những thỏa hiệp.
Bước 6: Sân chơi (Xác minh và Kiểm thử)
Hành động của chúng tôi:
Chúng tôi đã khởi chạy phiên bản PostgreSQL trong trình duyệt. Sử dụng AI để tạo ra 500 sinh viên, 100 khóa học và 2.000 đăng ký.
Quan điểm của chúng tôi:
Chúng tôi đã thực hiện kiểm thử tải trọng: 100 đăng ký đồng thời. Cấu trúc dữ liệu vẫn ổn định. Chúng tôi cũng đã kiểm thử:
-
Một sinh viên có thể đăng ký cùng một khóa học hai lần không?
-
Một giảng viên có thể dạy hai khóa học cùng lúc không?
Các ràng buộc đã ngăn dữ liệu không hợp lệ. Chúng tôi đã phát hiện ra một lỗi trong logic của mìnhtrước khi viết mã phía backend.
✅ Mẹo: Tạo hàng trăm bản ghi. Hiệu suất truy vấn chỉ thực sự thể hiện khi ở quy mô lớn.
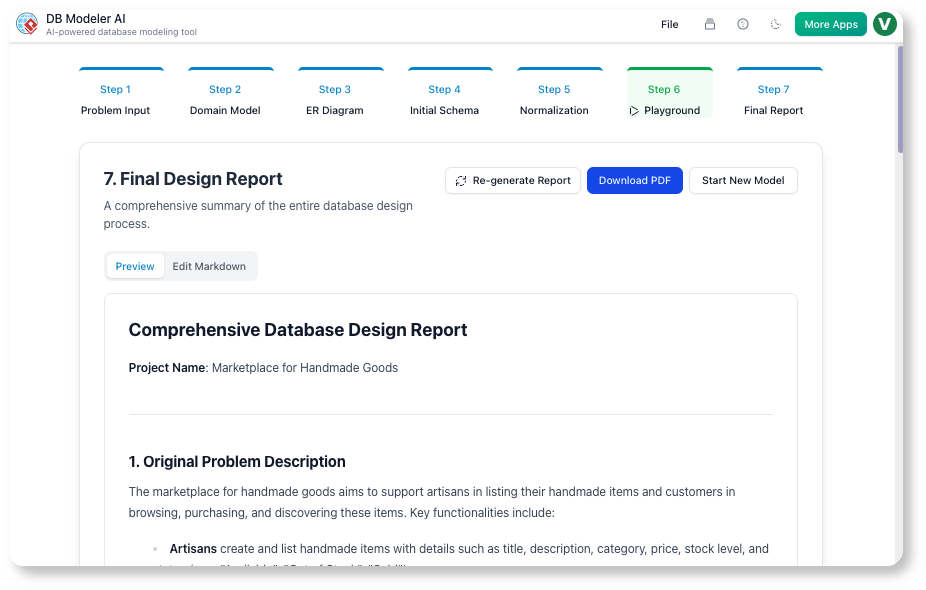
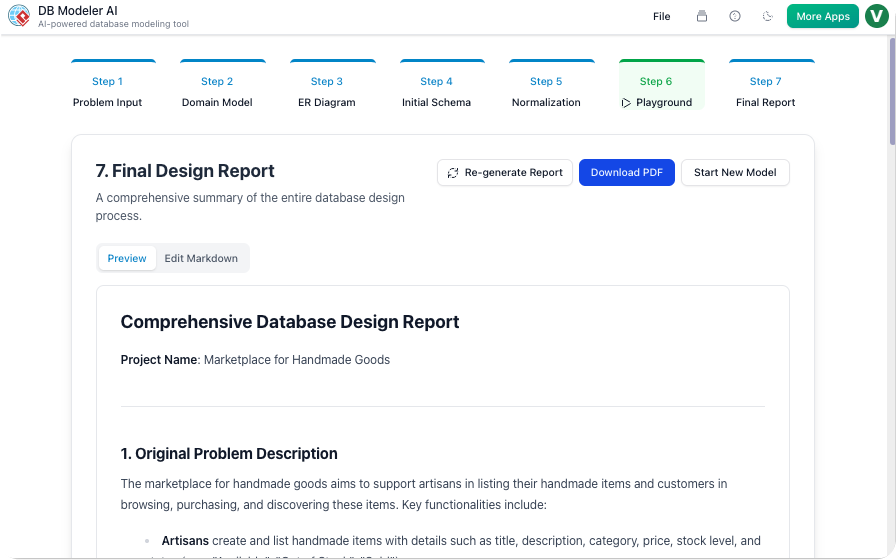
Bước 7: Báo cáo cuối cùng (Tài liệu)
Hành động của chúng tôi:
AI đã tạo báo cáo định dạng Markdown với:
-
Phát biểu vấn đề
-
Sơ đồ (PNG + PlantUML)
-
Cấu trúc cuối cùng
-
Mẫu
INSERTlệnh
Chúng tôi đã thêm phầnCác quyết định thiết kế phần:
“Chúng tôi đã loại bỏ chuẩn hóa
current_gradeđể tránh các JOIN trong các truy vấn đăng ký thời gian thực. Điều này cải thiện hiệu suất nhưng làm tăng độ phức tạp ghi dữ liệu một chút.”
Quan điểm của chúng tôi:
Báo cáo này đã trở thành tài liệu tài liệu hướng dẫn người mới. Các lập trình viên mới đọc nó và hiểu sơ đồ trong vòng 15 phút.
✅ Mẹo: Sử dụng Báo cáo Cuối cùng như một tài liệu chuyển giao cho DevOps và QA.
Hướng dẫn & Thực hành Tốt: Những điều Chúng tôi đã học được một cách khó khăn
| Thực hành | Bài học của chúng tôi |
|---|---|
| Bắt đầu nhỏ | Chúng tôi đã cố gắng mô hình hóa toàn bộ hệ thống trường đại học trong một lần. Thất bại. Bây giờ chúng tôi chia nó thành các mô-đun: Người dùng, Khóa học, Đăng ký. |
| Kiểm soát phiên bản PlantUML | Chúng tôi đã đưa các tệp PlantUML vào Git. Các thay đổi (diffs) cho thấy sự phát triển của sơ đồ. Một chiến thắng lớn cho kiểm toán. |
| Kiểm thử với hàng trăm bản ghi | 10 bản ghi kiểm thử che giấu các vấn đề hiệu suất. Hơn 500 bản ghi đã tiết lộ các truy vấn JOIN chậm. |
| Tài liệu hóa các giả định | “Không xóa mềm” → sau này gây ra lỗi. Bây giờ chúng tôi ghi lại mọi giả định. |
| Tích hợp với CI/CD | Chúng tôi đã thêm một validate-schema.sh script chạy pglinttrên DDL đã xuất ra. |
Mẹo và Thủ thuật cho Người dùng Nâng cao (Những Cách Nhanh Chứng Minh của Đội Nhóm Chúng Tôi)
🔹 Kỹ thuật Gợi ý = Chìa khóa Thay đổi Cuộc chơi
Thay vì:
“Xây dựng một hệ thống blog”
Bây giờ chúng tôi sử dụng:
*”Thiết kế một lược đồ PostgreSQL cho nền tảng blog đa người dùng, nơi mà:
Mỗi người dùng có các bài viết và bình luận riêng biệt
Các bài viết hỗ trợ thẻ và xuất bản theo lịch trình
Các bình luận có thể lồng nhau đến 3 cấp độ
Tất cả các bảng đều bao gồm
created_atvàupdated_at“*
Kết quả:AI đã tạo ra mộtlược đồ nhận biết người dùng với sự tách biệt phù hợp—điều mà chúng tôi có thể đã bỏ sót nếu làm thủ công.
🔹 Sử dụng chú thích PlantUML để đồng bộ hóa đội nhóm
Bây giờ chúng tôi ghi chú mọi quyết định quan trọng trong PlantUML. Ví dụ:
' @team: Xem xét mối quan hệ này—chúng ta có nên thêm cờ `soft_deleted` không?
' @arch: Đã chấp thuận cho phiên bản v1.2. Sẽ thêm trong sprint tiếp theo.
Người dùng "1" -- "0..*" Bài viết : viết
🔹 Xuất sớm, xuất thường xuyên
Chúng tôi xuất DDL và Markdown sau mỗi lần lặp quan trọng. Chúng tôi có mộtschema/versions/thư mục vớiv1.0.sql, v1.1.sql, v.v. Lý tưởng cho thao tác quay lại.
🔹 Kết hợp với Visual Paradigm Desktop
Đối với các dự án phức tạp, chúng tôi xuất PlantUML sang Desktop, khôi phục ngược cơ sở dữ liệu hiện có và tạo ra SQL cho MySQL hoặc SQL Server.
🔹 Dạy học bằng các bước chuẩn hóa
Chúng tôi tổ chức một trò chơi ‘Chiến tranh lược đồ’ nơi các thành viên mới dự đoán bước chuẩn hóa tiếp theo. Giải thích của AI luôn thắng trong mọi lần.
Ghi chú về truy cập, cấp phép và tích hợp (Cài đặt của Đội Nhóm Chúng Tôi)
| Khía cạnh | Cài đặt của Chúng Tôi |
|---|---|
| Nền tảng | Dựa trên web thông quaHộp công cụ AI của Visual Paradigm |
| Cấp phép | Gói Online của Visual Paradigm (bắt buộc cho các tính năng AI) |
| Ngữ pháp SQL | PostgreSQL (chính); phiên bản Desktop cho MySQL/SQL Server |
| Định dạng xuất | DDL, Markdown, PDF, JSON, PlantUML |
| Hợp tác nhóm | Git + Markdown + liên kết Playground chia sẻ |
| Sử dụng ngoại tuyến | Không cần thiết—phiên bản web nhanh và đáng tin cậy |
💡 Ghi chú Chuyên gia: Chúng tôi đang nâng cấp lên Teamwork Server để quản lý phiên bản mô hình tập trung và kiểm soát truy cập. Lý tưởng cho các đội nhóm doanh nghiệp.
Kết luận: Tương lai của thiết kế cơ sở dữ liệu là hợp tác, được hỗ trợ bởi AI và lấy con người làm trung tâm
Sau hai tháng sử dụng thực tế, DBModeler AI đã trở thành một phần cốt lõi trong quy trình phát triển của chúng tôi.
Không chỉ nhanh hơn—nó còn thông minh hơn. Nó buộc chúng tôi phải suy nghĩ một cách nghiêm túc về chuẩn hóa, ràng buộc và các tình huống biên. Nó phổ cập hóa thiết kế cơ sở dữ liệu cho mọi vai trò. Và nó giảm thiểu rủi ro phải tái cấu trúc lược đồ tốn kém bằng cách phát hiện các vấn đề trước khi chúng đạt đến môi trường sản xuất.
Thông tin quý giá nhất là? AI không thay thế chuyên môn—nó nâng tầm chuyên môn đó. Chúng tôi không viết ít mã hơn. Chúng tôi đang viết mã tốt hơn, nhanh hơn, với sự tự tin hơn.
Nếu bạn đã mệt mỏi với các lược đồ lộn xộn, thiếu tài liệu hoặc bị lỗi—if bạn muốn thiết kế cơ sở dữ liệu như một chuyên gia, mà không cần phải trải qua quá trình học tập phức tạp—thì DBModeler AI không chỉ là một công cụ. Đó là một bước ngoặt.
Sẵn sàng để thay đổi quy trình làm việc cơ sở dữ liệu của bạn?
👉 Bắt đầu với DBModeler AI
Không cần cài đặt. Không cần cấu hình. Chỉ cần gõ ý tưởng của bạn và xây dựng một lược đồ sẵn sàng sản xuất trong vài phút.
Tài liệu tham khảo
- DB Modeler AI | Công cụ thiết kế cơ sở dữ liệu được hỗ trợ bởi AI từ Visual Paradigm: Trang tính năng chính thức mô tả các khả năng, trường hợp sử dụng và các tùy chọn tích hợp cho DBModeler AI.
- Thành thạo DBModeler AI từ Visual Paradigm: Hướng dẫn chi tiết và đi qua quy trình làm việc bởi một chuyên gia cộng đồng, bao gồm các chiến lược triển khai thực tế.
- Trang công cụ DBModeler AI: Trang đích công cụ tương tác với các câu hỏi thường gặp, điểm nổi bật tính năng và truy cập trực tiếp vào bộ sinh AI.
- Ghi chú phát hành DBModeler AI: Nhật ký cập nhật chính thức, thông báo tính năng mới và lịch sử phiên bản từ Visual Paradigm.
- Tổng quan bộ sinh cơ sở dữ liệu DBModeler AI: Tóm tắt ngắn gọn về lợi thế cốt lõi của công cụ và quy trình 7 bước.
- Hệ thống quản lý bệnh viện với DBModeler AI: Nghiên cứu trường hợp thực tế minh họa thiết kế cơ sở dữ liệu toàn diện cho lĩnh vực y tế.
- Hộp công cụ AI Visual Paradigm – Ứng dụng DBModeler AI: Điểm vào trực tiếp để khởi chạy ứng dụng DBModeler AI dựa trên web.
- Hướng dẫn video DBModeler AI: Video hướng dẫn chính thức giới thiệu giao diện, quy trình làm việc và các tính năng chính đang hoạt động.
- Phiên bản phát hành Công cụ phân tích sơ đồ trường hợp sử dụng AI miễn phí: Bối cảnh về hệ sinh thái hộp công cụ AI rộng lớn của Visual Paradigm và hướng dẫn truy cập cho người dùng Online.
- Hướng dẫn tích hợp trên máy tính để bàn: Hướng dẫn video kết nối đầu ra của DBModeler AI với Visual Paradigm Desktop để thực hiện các quy trình xuất nâng cao và tái tạo ngược.
✅ Suy nghĩ cuối cùng:
Những cơ sở dữ liệu tốt nhất không được xây dựng một cách tách biệt. Chúng là kết quả của sự hợp tácđược cùng nhau tạo nên—giữa sản phẩm, kỹ thuật và trí tuệ nhân tạo.
Với DBModeler AI, sự hợp tác đó cuối cùng đã trở nên trơn tru.
Bắt đầu xây dựng nền tảng dữ liệu tốt hơn—ngay hôm nay.
This post is also available in Deutsch, English, Español, فارسی, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, 简体中文 and 繁體中文.