













Por un ingeniero senior de desarrollo completo | Un informe de experiencia de terceros con perspectivas prácticas e impacto en el equipo
Introducción: Por qué esta herramienta cambió la forma en que diseñamos bases de datos
Como ingeniero senior de desarrollo completo en una startup de SaaS de rápido crecimiento, he visto cómo nuestro proceso de diseño de bases de datos ha pasado por el tamiz. Desde bocetos apresurados en pizarras hasta reestructuraciones de esquema de último minuto que rompieron producción, la base de datos ha sido a menudo el eslabón más débil en nuestra cadena de entrega.
Hemos probado todo: herramientas de ERD, complementos de diagramación e incluso DSLs personalizadas para la definición de esquemas. Pero ninguna de ellas realmente cerró la brecha entre intención del negocio y SQL listo para producción—especialmente cuando incorporamos ingenieros junior o trabajamos con gerentes de producto no técnicos.
Entonces llegó DBModeler AI de Visual Paradigm.
Después de una prueba de dos semanas con mi equipo, puedo decir sin exagerar: esta es la herramienta de diseño de bases de datos más transformadora que he usado en más de una década.
Esto no es solo otro generador de diagramas impulsado por IA. Es un motor de diseño colaborativo que convierte el lenguaje natural en un esquema de base de datos completamente normalizado, comprobable y documentado, todo en un navegador, sin configuración alguna.

En esta guía, te mostraré nuestra experiencia real usando DBModeler AI en tres funciones principales: autenticación de usuarios, inscripción en cursos y gestión de pedidos. Compartiré lo que funcionó, lo que no y cómo lo hemos integrado en nuestro flujo ágil de trabajo, incluyendo capturas de pantalla, comentarios del equipo y consejos prácticos que puedes aplicar de inmediato.
Conceptos clave para los equipos de desarrollo (Revisado con contexto del mundo real)
🎯 IA como diseñador colaborativo, no como sustituto
Nuestra experiencia:
Al principio temíamos que la IA “sobrescribiera” nuestros modelos cuidadosamente elaborados. Pero tras probarla, nos dimos cuenta de que la IA no reemplace el juicio, sino que lo amplifique.
Por ejemplo, cuando describimos un «estudiante puede inscribirse en múltiples cursos», la IA inferió correctamente una relación muchos a muchos y sugirió una tabla de unión. Pero pudimos editar directamente el código de PlantUML para agregar marcas de eliminación suave y marcas de auditoría, algo que la IA no generó automáticamente, pero que necesitábamos para cumplir con las normativas.
✅ Veredicto: La IA es un copiloto, no un sustituto. Siempre estás al mando.
🔁 Perfeccionamiento iterativo por diseño
Nuestra experiencia:
Durante la funcionalidad de inscripción en cursos, comenzamos con un modelo simple: Estudiante → Curso. Después de que la IA generó el diagrama ER, nos dimos cuenta de que necesitábamos rastrear estado de inscripción (activo, abandonado, fallido). Volvimos al Paso 2, editamos la clase Inscripción en PlantUML y regeneramos el esquema en menos de 30 segundos.
✅ Veredicto: El flujo de trabajo cíclico no es teórico: es práctico. Ahora tratamos el diseño de esquemas como una sprint, no como una tarea única.
🧪 Prueba antes de desplegar – La zona de pruebas cambió todo
Nuestra experiencia:
Solíamos escribir pruebas de integración después de que el esquema se desplegara. Ahora, nosotros validamos el comportamiento antes de escribir una sola línea de código.
En la zona de pruebas, generamos 500 estudiantes de muestra y los inscribimos en cursos. Ejecutamos consultas complejas como:
SELECT s.nombre, COUNT(e.id) AS cantidad_cursos
FROM estudiantes s
JOIN inscripciones e ON s.id = e.estudiante_id
WHERE e.estado = 'activo'
GROUP BY s.nombre
ORDER BY cantidad_cursos DESC;
La consulta devolvió resultados de inmediato, sin necesidad de levantar una base de datos local. Incluso probamos casos extremos: ¿qué sucede si un estudiante abandona todos los cursos? La lógica de restricciones de la IA evitó registros huérfanos, y detectamos una posible condición de carrera temprano.
✅ Veredicto: El Playground eliminó el 80 % de nuestros errores de esquema posteriores al despliegue.
📐 Normalización como una característica de primer orden
Nuestra experiencia:
Nuestro desarrollador junior se confundió al ver por qué la IA dividió Curso en Curso y InstructorCurso. Pero después de recorrer los pasos de 1FN → 2FN → 3FN, ellos entendieron la lógica, especialmente cuando la IA mostró cómo se eliminaron los grupos repetidos.
Ahora utilizamos este paso como un módulo de capacitación para nuevos contratos. Es como un libro de texto vivo sobre la teoría de bases de datos.
✅ Veredicto: La normalización ya no es una casilla de verificación: es un proceso enseñable y visible.
🌐 Nativo del navegador, sin sobrecarga de instalación
Nuestra experiencia:
Uno de nuestros miembros del equipo estaba en una laptop bloqueada por la empresa sin derechos de administrador. No pudieron instalar Docker ni PostgreSQL. Pero ellos se unieron al proyecto a través de la aplicación web, crearon un esquema y contribuyeron al diseño en menos de 10 minutos.
✅ Veredicto: Este es la herramienta de bases de datos más inclusiva que he usado. La incorporación ahora es sin fricciones.
El flujo de trabajo de IA de 7 pasos: Una profundización para desarrolladores – Nuestro viaje en equipo
Paso 1: Entrada de problema (entrada conceptual)
Nuestro prompt:
“Construye un sistema para gestionar cursos universitarios, estudiantes y matrículas. Los estudiantes pueden inscribirse en múltiples cursos. Cada curso tiene un instructor. Las matrículas registran calificaciones, marcas de tiempo y estado (activo, retirado, reprobado). Todas las tablas deben incluir
created_atyupdated_at.”
Nuestra opinión:
El generador de descripciones de la IA nos ayudó a perfeccionar nuestra entrada. Añadimos restricciones y reglas de negocio que habíamos pasado por alto inicialmente.
✅ Consejo: Usa viñetas. La IA las interpreta mejor que párrafos largos.
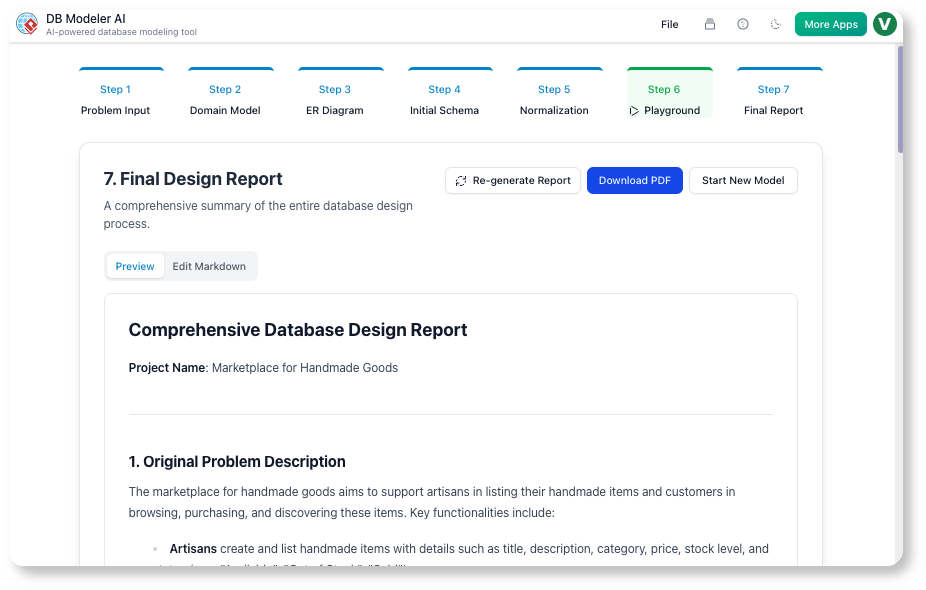
Paso 2: Modelo de dominio (modelado conceptual)
Nuestra acción:
La IA generó un modelo de dominio basado en PlantUML. Renombramos Student a User, añadimos email, rol, y is_active atributos, y aclaramos la clase Enrollment clase.
Nuestra opinión:
La representación visual fue instantánea y limpia. Compartimos el código de PlantUML en Slack, y nuestro equipo frontend ya podía ver la estructura.
✅ Consejo: Utilice
@notacomentarios en PlantUML para documentar supuestos.
@nota derecha
Esta relación podría necesitar una tabla de unión si agregamos eliminaciones suaves
@end nota
Paso 3: Diagrama ER (Modelado Lógico)
Nuestra acción:
La IA generó automáticamente PKs, FKs y cardinalidades. Notamos una relación 1:N entre Curso y Instructor—pero queríamos un instructor por curso, por lo que lo ajustamos a 1:1.
Nuestra opinión:
Revisamos dos veces la cardinalidad con el equipo. Un error aquí habría causado anomalías de datos.
✅ Consejo: Valide siempre las relaciones con los dueños del producto antes de finalizar.
Paso 4: Esquema inicial (Generación de código físico)
Nuestra acción:
Generó DDL de PostgreSQL con creado_en, actualizado_en, y CHECK restricciones.
Nuestra opinión:
Lo utilizamos como el base para las migraciones de Flyway. Ya no más DDL escritos a mano—solo scripts controlados por versión.
✅ Consejo: Exporta el DDL temprano. Mantenemos una carpeta
esquema/inicialen Git.
Paso 5: Normalización (optimización de esquema)
Nuestra acción:
Recorrimos 1FN → 2FN → 3FN. En la 2FN, la IA dividió Inscripción en Inscripción y HistorialInscripción para eliminar dependencias parciales.
Nuestra opinión:
Discutimos si mantenerlo. Desde el punto de vista del rendimiento, la 3FN era más lenta para las uniones. Así que denormalizamos ligeramente—añadimos calificacion_actual a Inscripción—y documentamos el compromiso en el Informe Final.
✅ Consejo: No aceptes ciegamente la 3FN. úsala para entender los compromisos.
Paso 6: Entorno de pruebas (validación y prueba)
Nuestra acción:
Lanzamos una instancia de PostgreSQL en el navegador. Utilizamos IA para generar 500 estudiantes, 100 cursos y 2.000 matrículas.
Nuestra opinión:
Realizamos una prueba de estrés: 100 matrículas concurrentes. El esquema resistió. También probamos:
-
¿Puede un estudiante matricularse en el mismo curso dos veces?
-
¿Puede un instructor impartir dos cursos al mismo tiempo?
Las restricciones evitaron datos inválidos. Detectamos un error en nuestra lógicaantes de escribir el código del backend.
✅ Consejo: Genera cientos de registros. El rendimiento de las consultas solo se revela a gran escala.
Paso 7: Informe final (documentación)
Nuestra acción:
La IA generó un informe en Markdown con:
-
Enunciado del problema
-
Diagramas (PNG + PlantUML)
-
Esquema final
-
Ejemplo
INSERTARsentencias
Añadimos una Decisiones de diseño sección:
“Normalizamos
current_gradepara evitar JOINs en las consultas de matrícula en tiempo real. Esto mejora el rendimiento a costa de una complejidad de escritura ligeramente mayor.”
Nuestro punto de vista:
Este informe se convirtió en nuestro documento de incorporación. Los nuevos desarrolladores lo leyeron y entendieron el esquema en 15 minutos.
✅ Consejo: Utiliza el informe final como un artefacto de transferencia a DevOps y QA.
Guías y mejores prácticas: Lo que aprendimos con dificultad
| Práctica | Nuestra lección |
|---|---|
| Empieza pequeño | Intentamos modelar todo el sistema universitario de una vez. Falló. Ahora lo dividimos en módulos: Usuario, Curso, Inscripción. |
| Control de versiones de PlantUML | Confirmamos los archivos de PlantUML en Git. Las diferencias mostraron la evolución del esquema. Gran ventaja para auditorías. |
| Prueba con cientos de registros | 10 registros de prueba ocultan problemas de rendimiento. Más de 500 revelaron JOINs lentos. |
| Documenta las suposiciones | “Sin eliminaciones suaves” → más adelante causó un error. Ahora documentamos cada suposición. |
| Integración con CI/CD | Añadimos un validate-schema.sh script que se ejecuta pglint en el DDL exportado. |
Consejos y trucos para usuarios avanzados (Nuestros atajos probados por el equipo)
🔹 Ingeniería de prompts = Cambio de juego
En lugar de:
“Construye un sistema de blog”
Ahora usamos:
*”Diseña un esquema de PostgreSQL para una plataforma de blog multi-tenant donde:
Cada inquilino tiene publicaciones y comentarios aislados
Las publicaciones admiten etiquetas y publicación programada
Los comentarios pueden anidarse hasta 3 niveles
Todas las tablas incluyen
creado_enyactualizado_en“*
Resultado: La IA generó un esquema consciente de inquilinos con aislamiento adecuado—algo que habríamos pasado por alto manualmente.
🔹 Usa comentarios de PlantUML para sincronización del equipo
Ahora anotamos cada decisión importante en PlantUML. Ejemplo:
' @equipo: Revisa esta relación—¿debemos agregar una bandera `eliminado_sucio`?
' @arquitecto: Aprobado para v1.2. Lo agregaremos en la próxima iteración.
Usuario "1" -- "0..*" Publicación : escribe
🔹 Exporta temprano, exporta a menudo
Exportamos DDL y Markdown después de cada iteración importante. Tenemos un esquema/versions/carpeta con v1.0.sql, v1.1.sql, etc. Perfecto para deshacer cambios.
🔹 Emparejar con Visual Paradigm Desktop
Para proyectos complejos, exportamos el PlantUML a Desktop, realizamos ingeniería inversa de bases de datos existentes y generamos SQL para MySQL o SQL Server.
🔹 Enseñar con pasos de normalización
Realizamos un ‘Juego de Guerra de Esquemas’ donde los principiantes predicen el siguiente paso de normalización. La explicación de la IA gana cada vez.
Notas de acceso, licenciamiento e integración (Nuestra configuración)
| Aspecto | Nuestra configuración |
|---|---|
| Plataforma | Basado en web a través de Caja de herramientas de IA de Visual Paradigm |
| Licenciamiento | Combo Visual Paradigm Online (requerido para funciones de IA) |
| Dialecto SQL | PostgreSQL (principal); edición de escritorio para MySQL/SQL Server |
| Formatos de exportación | DDL, Markdown, PDF, JSON, PlantUML |
| Colaboración en equipo | Git + Markdown + enlaces compartidos de Playground |
| Uso sin conexión | No necesario—la versión web es rápida y confiable |
💡 Nota profesional:Estamos actualizando a Teamwork Serverpara la versión centralizada de modelos y control de acceso. Perfecto para equipos empresariales.
Conclusión: El futuro del diseño de bases de datos es colaborativo, impulsado por IA y centrado en el ser humano
Después de dos meses de uso en el mundo real, DBModeler AI se ha convertido en una parte fundamental de nuestro flujo de trabajo de desarrollo.
No es solo más rápido, es más inteligente. Nos obliga a pensar críticamente sobre la normalización, las restricciones y los casos límite. Democratiza el diseño de bases de datos entre los distintos roles. Y reduce el riesgo de reestructuraciones costosas de esquemasreduciendo el riesgo de reestructuraciones costosas de esquemasal detectar problemas antes deque lleguen a producción.
La conclusión más valiosa? La IA no reemplaza la experiencia, la eleva.No estamos escribiendo menos código. Estamos escribiendo código mejor, más rápido, con más confianza.
Si estás cansado de esquemas desordenados, sin documentar o dañados, si quieres diseñar bases de datos como un profesional, sin la curva de aprendizaje pronunciada—entonces DBModeler AI no es solo una herramienta. Es un cambio de juego.
¿Listo para transformar tu flujo de trabajo de bases de datos?
👉 Empieza con DBModeler AI
Sin instalación. Sin configuración. Solo escribe tu idea y crea un esquema listo para producción en minutos.
Referencias
- DB Modeler AI | Herramienta de diseño de bases de datos impulsada por IA de Visual Paradigm: Página oficial de características que detalla capacidades, casos de uso y opciones de integración para DBModeler AI.
- Dominando DBModeler AI de Visual Paradigm: Tutorial detallado y recorrido paso a paso del flujo de trabajo por un experto de la comunidad, que cubre estrategias prácticas de implementación.
- Página de la herramienta DBModeler AI: Página de aterrizaje interactiva de la herramienta con preguntas frecuentes, destacados de funciones y acceso directo al generador de IA.
- Notas de lanzamiento de DBModeler AI: Registros oficiales de actualizaciones, anuncios de nuevas funciones y historial de versiones de Visual Paradigm.
- Visión general del generador de bases de datos DBModeler AI: Resumen conciso de la propuesta de valor de la herramienta y su flujo de trabajo de 7 pasos.
- Sistema de gestión hospitalaria con DBModeler AI: Estudio de caso real que demuestra el diseño de bases de datos completo para un dominio sanitario.
- Caja de herramientas de IA de Visual Paradigm – Aplicación DBModeler AI: Punto de entrada directo para iniciar la aplicación web de DBModeler AI.
- Recorrido en video de DBModeler AI: Tutorial oficial en video que muestra la interfaz, el flujo de trabajo y las funciones clave en acción.
- Lanzamiento del analizador de diagramas de casos de uso de IA gratuita: Contexto sobre el ecosistema más amplio de cajas de herramientas de IA de Visual Paradigm y instrucciones de acceso para usuarios Online.
- Tutorial de integración con el escritorio: Guía en video sobre la conexión de las salidas de DBModeler AI con Visual Paradigm Desktop para flujos de trabajo avanzados de exportación y ingeniería inversa.
✅ Último pensamiento:
Las mejores bases de datos no se construyen en aislamiento. Se crean co-creadas—por producto, ingeniería y IA.
Con DBModeler AI, esa colaboración es finalmente fluida.
Empiece a construir mejores fundamentos de datos—hoy mismo.