













Concevoir un processus métier robuste exige plus que la simple cartographie du scénario idéal. Bien que le « chemin heureux » montre comment un processus fonctionne lorsque tout se passe bien, le véritable test d’un système réside dans la manière dont il gère l’imprévu. Dans le contexte de Modèle et notation des processus métiers (BPMN), la gestion des flux d’exception est cruciale pour maintenir l’intégrité, la conformité et la continuité opérationnelle. Ce guide explore les mécanismes de gestion des erreurs dans les normes BPMN 2.0, garantissant que vos diagrammes de processus restent propres, logiques et résilients.
🧩 Comprendre les flux d’exception dans BPMN
Les flux d’exception représentent les chemins alternatifs qu’un processus emprunte lorsqu’une condition spécifique s’écarte de la norme. Ce ne sont pas simplement des messages d’erreur ; ce sont des décisions structurées qui déterminent l’état futur d’une transaction commerciale. Sans une définition appropriée, un diagramme de processus devient fragile et se brise dès la moindre perturbation. Un flux d’exception bien conçu garantit que :
- Consistance de l’état : Le processus ne laisse pas les données dans un état ambigu.
- Visibilité : Les parties prenantes peuvent voir exactement où et pourquoi un processus s’est écarté.
- Récupération : Des mécanismes existent pour corriger l’erreur ou terminer le processus de manière ordonnée.
Lors de la modélisation des exceptions, l’objectif est la clarté. Un diagramme doit répondre à la question : « Que se passe-t-il ensuite ? » même lorsque les choses tournent mal. Cela exige une compréhension approfondie des éléments BPMN spécifiques conçus pour détecter les interruptions.
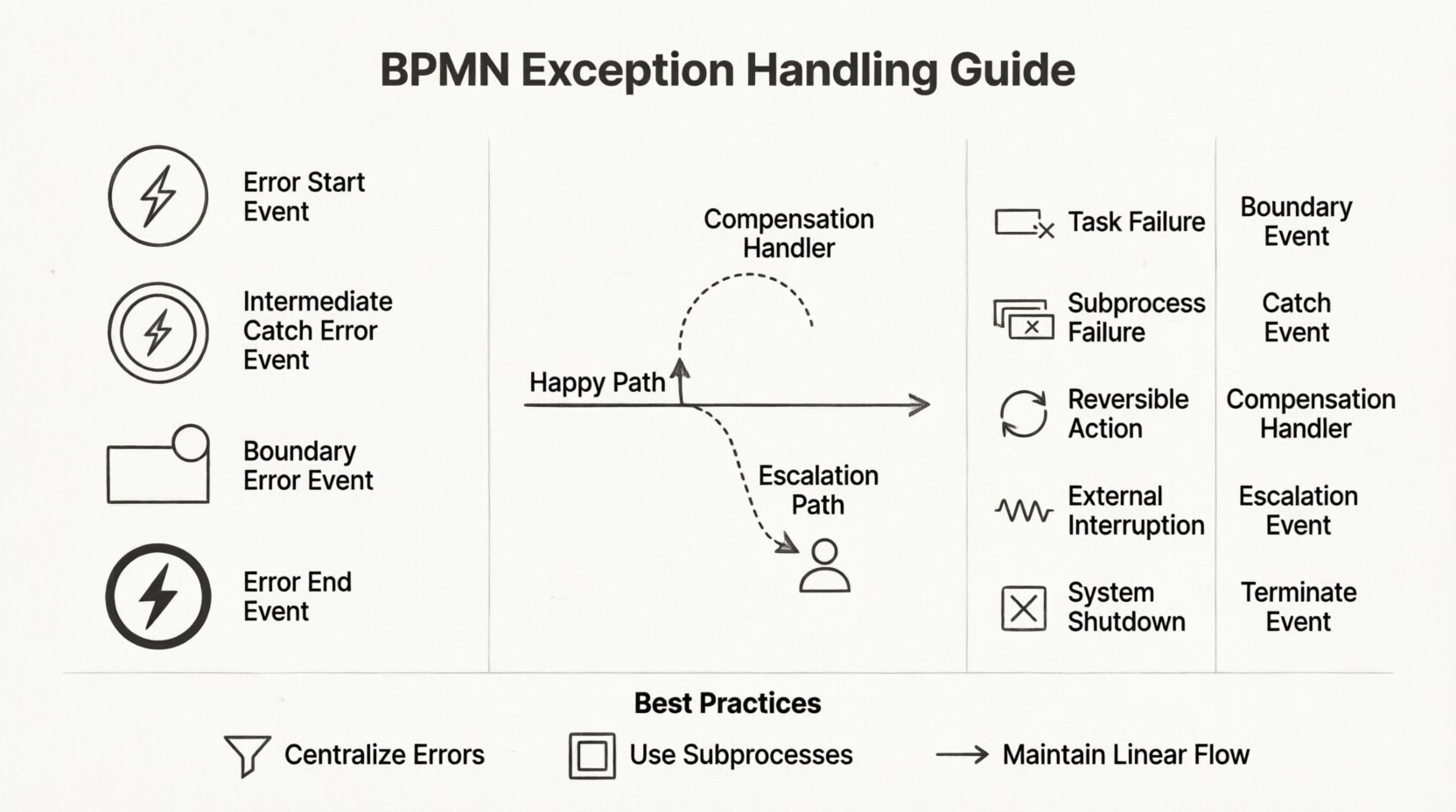
⚠️ L’anatomie d’un événement d’erreur
Les erreurs dans BPMN sont distinctes des messages ou signaux généraux. Elles sont spécifiquement conçues pour gérer les défaillances système, les échecs de validation ou les perturbations externes. BPMN définit trois façons principales d’intégrer ces erreurs dans un flux :
1. Événements de démarrage d’erreur
Un événement de démarrage d’erreur déclenche un processus déclenché par une défaillance ailleurs. Cela est utile pour les systèmes de surveillance. Par exemple, si une passerelle de paiement échoue, un événement de démarrage d’erreur peut déclencher un flux de notification pour alerter l’équipe financière. Cela permet au système de réagir de manière asynchrone aux défaillances sans bloquer le flux principal des transactions.
2. Événements d’erreur intermédiaires de capture
Ces événements mettent en pause un processus en attendant une condition d’erreur. Contrairement à un événement de message intermédiaire standard, qui attend une communication, celui-ci attend un signal d’erreur spécifique. Il est souvent utilisé pour :
- Capturer les erreurs remontant depuis des sous-processus.
- Mettre en œuvre une logique de réessai en revenant à une tâche précédente.
- Rediriger le processus vers un sous-processus spécialisé de gestion des erreurs.
3. Événements d’erreur à la limite
C’est peut-être la méthode la plus courante pour gérer les exceptions au sein d’une tâche. Un événement d’erreur à la limite est attaché à la bordure d’une tâche ou d’un sous-processus. Si une erreur survient pendant l’exécution de cette activité spécifique, le flux se divise immédiatement vers le chemin connecté à l’événement à la limite. Cela maintient le flux principal propre, car la logique normale reste inchangée jusqu’à ce qu’une erreur survienne réellement.
4. Événements de fin d’erreur
Lorsqu’une erreur ne peut pas être récupérée, un événement de fin d’erreur termine l’instance du processus. Il est crucial de définir quelles informations sont capturées à ce stade. Les métadonnées concernant le code ou le message d’erreur doivent être enregistrées avant la fermeture de l’instance. Cela garantit que les traces d’audit restent intactes même après un échec du processus.
🔄 Compensation : annulation des actions
Toutes les exceptions n’impliquent pas la terminaison. Parfois, un processus doit revenir à un état antérieur. C’est là que les gestionnaires de compensation entrent en jeu. Dans BPMN, la compensation consiste à annuler une activité terminée. Cela est essentiel pour les transactions impliquant des règlements financiers, des mises à jour de stock ou des saisies de données.
Lorsqu’un processus atteint un point où une étape antérieure doit être annulée, le modèle doit définir une frontière de compensation. Cela implique :
- Définir l’activité spécifique qui nécessite un retour en arrière.
- Préciser le flux de compensation qui exécute l’action inverse.
- Assurer que le flux de compensation est idempotent (sans danger à exécuter plusieurs fois).
Prenons l’exemple d’un processus d’approbation de prêt. Si une demande de client est approuvée mais que la génération du contrat suivante échoue, l’état d’approbation doit être annulé. Un gestionnaire de compensation assure que l’état « Approuvé » soit rétabli à « En attente » sans intervention manuelle.
📊 Comparaison des stratégies de gestion des exceptions
Le choix du bon mécanisme dépend de la nature de l’échec. Le tableau ci-dessous indique quand utiliser des constructions BPMN spécifiques pour la gestion des exceptions.
| Type d’exception | Élément BPMN | Meilleur cas d’utilisation |
|---|---|---|
| Échec de tâche | Événement d’erreur à la limite | Une tâche spécifique échoue, un réessai local ou une alerte est nécessaire. |
| Échec du sous-processus | Événement d’interception intermédiaire (global) | L’ensemble du sous-processus échoue, une réponse de haut niveau est nécessaire. |
| Action réversible | Gestionnaire de compensation | Il faut annuler des étapes terminées après un échec ultérieur. |
| Interruption externe | Événement d’escalade | Exige une gestion humaine ou un changement de politique externe. |
| Arrêt du système | Événement de terminaison | Le processus doit s’arrêter immédiatement en raison d’une erreur critique. |
🚨 Escalades vs. Erreurs
Il est important de distinguer une erreur d’une escalade. Bien qu’elles représentent toutes deux des écarts, elles ont des fonctions sémantiques différentes.
- Erreurs :Échecs techniques ou logiques. Le système ne peut pas poursuivre en raison d’un état défectueux (par exemple, format de données invalide, ressource manquante).
- Escalades : Failles procédurales ou de gestion. Le processus ne peut pas progresser car une condition nécessite une attention humaine ou une annulation de politique (par exemple, dépassement de la limite d’approbation, violation du SLA).
Utiliser des événements d’escalade vous permet de modéliser l’aspect humain des exceptions. Lorsqu’un escalade se produit, le processus peut être redirigé vers une tâche manuelle pour revue. Cela maintient la logique automatisée séparée de la logique de prise de décision, préservant ainsi la clarté du diagramme.
🕸️ Éviter le piège du « spaghetti »
L’un des défis les plus courants en BPMN est le brouillage visuel qui survient lors de l’ajout de flux d’exception. Si chaque tâche possède un événement de bordure menant à un point final différent, le diagramme devient illisible. Pour maintenir l’intégrité logique sans compromettre la clarté visuelle, suivez ces principes structurels :
1. Centraliser le traitement des erreurs
Au lieu de créer des chemins uniques pour chaque petite erreur, regroupez les erreurs similaires. Par exemple, si trois tâches différentes peuvent toutes échouer en raison d’un délai d’attente de base de données, redirigez les trois événements de bordure vers un seul sous-processus « Gestion des erreurs système ». Cela réduit le nombre de lignes traversant le diagramme.
2. Utiliser des sous-processus pour la complexité
Si un flux d’exception implique plusieurs étapes (par exemple, journalisation, notification, réessai, annulation), encapsulez-le dans un sous-processus. N’embrouillez pas le diagramme principal avec les détails de la logique de récupération. Cela maintient la vue de haut niveau propre et vous permet d’approfondir le traitement des exceptions uniquement lorsque cela est nécessaire.
3. Maintenir un flux linéaire là où c’est possible
Même en présence d’exceptions, le processus devrait idéalement avoir un aspect linéaire. Évitez de créer des boucles qui remontent trop loin dans le processus. Si une boucle de réessai est nécessaire, limitez-la à un nombre spécifique d’itérations ou à une fenêtre de temps précise. Les boucles infinies peuvent faire bloquer le moteur de processus ou générer des journaux excessifs.
🛡️ Assurer l’intégrité des données
Lorsqu’une exception se produit, l’état des données est souvent le plus grand risque. Un processus pourrait avoir mis à jour un enregistrement de base de données à l’étape 1, mais échouer à l’étape 2. Si le processus se termine, cet enregistrement reste dans un état partiellement terminé. Pour y remédier :
- Définir les limites des transactions :Assurez-vous que les tâches mettant à jour des données partagées sont regroupées de manière logique. Si une tâche échoue, le système doit savoir s’il doit annuler les modifications de données associées à cette tâche.
- Journaliser le contexte de l’exception :Lorsqu’un événement de fin d’erreur est déclenché, assurez-vous que les variables de processus contenant les détails de l’erreur sont enregistrées dans un journal persistant avant la fin de l’instance. Cela est essentiel pour le débogage ultérieur.
- Utiliser la corrélation de messages :Si le processus implique des systèmes externes, utilisez des clés de corrélation pour garantir que le message d’erreur soit associé à l’instance de processus correcte.
🧪 Test des chemins d’exception
Un modèle de processus n’est bon que par sa capacité à gérer la réalité. Le test des flux d’exception nécessite un état d’esprit différent de celui du test des parcours normaux. Vous devez simuler des conditions d’échec.
Les scénarios de test clés incluent :
- Conditions aux limites : Que se passe-t-il si un champ est vide ? Et si un nombre est négatif ?
- Scénarios de délai d’attente : Que se passe-t-il si un système bloque pendant 30 secondes ?
- Échecs simultanés : Que se passe-t-il si deux instances du processus tentent de mettre à jour le même enregistrement simultanément ?
- Réussite de la récupération : Si le système réessaie après un échec, le processus se termine-t-il avec succès, ou boucle-t-il indéfiniment ?
📝 Meilleures pratiques pour la maintenance
Au fil du temps, les processus évoluent. Les exigences de gestion des exceptions changent au fur et à mesure que les règles métier évoluent. Pour maintenir vos modèles BPMN maintenables :
- Contrôle de version : Suivez toujours les modifications apportées à la logique des exceptions. Un changement dans la gestion des erreurs peut avoir un impact sur les rapports de conformité.
- Documentation : Ajoutez des commentaires aux événements limites complexes. Expliquez pourquoi un chemin d’erreur spécifique existe. Les analystes futurs pourraient ne pas comprendre le contexte métier sans cela.
- Standardisation : Établissez des conventions de nommage pour les événements d’erreur. Utilisez des codes (par exemple, « ERR_001 ») de manière cohérente dans tous les processus afin de simplifier le débogage.
- Cycles de revue : Revoyez périodiquement les chemins d’exception. Y a-t-il des chemins qui ne sont jamais empruntés ? Y a-t-il des chemins trop complexes ? Simplifiez autant que possible.
🔍 Pièges courants à éviter
Même les modélisateurs expérimentés peuvent tomber dans des pièges lors de la conception des flux d’exception. Soyez attentif à ces erreurs courantes :
- Ignorer les échecs silencieux : Le fait qu’une tâche ne lance pas d’exception ne signifie pas qu’elle a réussi. Assurez-vous que la logique de validation est explicite.
- Utilisation excessive des passerelles : N’utilisez pas les passerelles X pour gérer les erreurs. Utilisez plutôt des événements d’erreur. Les passerelles servent au branchement logique, pas à la capture d’exceptions.
- Chemins orphelins : Assurez-vous que chaque événement limite a une destination claire. Une erreur qui est capturée mais qui ne mène nulle part est une impasse.
- Mélange de types de logique : N’associez pas les événements de message et les événements d’erreur sur la même limite. Ils ont des rôles différents et peuvent induire en erreur le moteur d’exécution.
🚀 L’impact des processus résilients
Construire des processus capables de gérer efficacement les exceptions est un investissement dans la stabilité opérationnelle. Quand un processus est résilient, il réduit la charge sur les équipes de support. Les erreurs sont détectées automatiquement, enregistrées correctement et acheminées vers les gestionnaires appropriés. Cela conduit à :
- Une satisfaction client plus élevée grâce à des temps de récupération plus rapides.
- Moins d’intervention manuelle pour les échecs courants.
- Une meilleure qualité des données, car les mécanismes d’annulation empêchent les mises à jour partielles.
- Assurance de conformité, car tous les états d’erreur sont suivis et audités.
En traitant les flux d’exception comme une entité de premier plan dans votre conception BPMN, vous créez des systèmes robustes et fiables. L’objectif n’est pas d’éliminer les erreurs, mais de garantir que, lorsqu’elles surviennent, le processus continue de fonctionner ou se termine de manière contrôlée.
🏁 Réflexions finales sur l’intégrité de la logique
Une modélisation BPMN efficace exige un équilibre entre un flux idéal et des échecs réalistes. En utilisant correctement les événements d’erreur, les gestionnaires de compensation et les événements d’escalade, vous pouvez créer des diagrammes qui reflètent la véritable complexité des opérations métiers. Souvenez-vous que la clarté est reine. Un modèle de processus doit être compréhensible même en cas d’échec. Concentrez-vous sur le maintien d’une structure claire, la documentation de votre logique et le test rigoureux de vos chemins de récupération. Cette approche garantit que vos processus métiers restent fonctionnels et adaptables dans tout environnement.
Cette publication est également disponible en Deutsch, English, Español, فارسی, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 : liste des langues séparées par une virgule, 繁體中文 : dernière langue.