













Diseñar un proceso de negocio robusto requiere más que simplemente mapear el escenario ideal. Mientras que la “ruta feliz” muestra cómo funciona un proceso cuando todo sale bien, la verdadera prueba de un sistema radica en cómo maneja lo inesperado. En el contexto de Modelo y notación de procesos de negocio (BPMN), gestionar los flujos de excepción es fundamental para mantener la integridad, el cumplimiento y la continuidad operativa. Esta guía explora la mecánica de la gestión de errores dentro de las normas BPMN 2.0, asegurando que sus diagramas de procesos permanezcan limpios, lógicos y resilientes.
🧩 Comprender los flujos de excepción en BPMN
Los flujos de excepción representan las rutas alternativas que sigue un proceso cuando una condición específica se desvía de lo normal. Estos no son meros mensajes de error; son decisiones estructuradas que determinan el estado futuro de una transacción comercial. Sin una definición adecuada, un diagrama de proceso se vuelve frágil, colapsando ante el primer signo de fricción. Un flujo de excepción bien arquitectado garantiza que:
- Consistencia de estado: El proceso no deja los datos en un estado ambiguo.
- Visibilidad: Los interesados pueden ver exactamente dónde y por qué un proceso se desvió.
- Recuperación: Existen mecanismos para corregir el error o finalizar el proceso de forma ordenada.
Al modelar excepciones, el objetivo es la claridad. Un diagrama debe responder a la pregunta: “¿Qué sucede a continuación?” incluso cuando las cosas salen mal. Esto requiere un profundo conocimiento de elementos específicos de BPMN diseñados para capturar interrupciones.
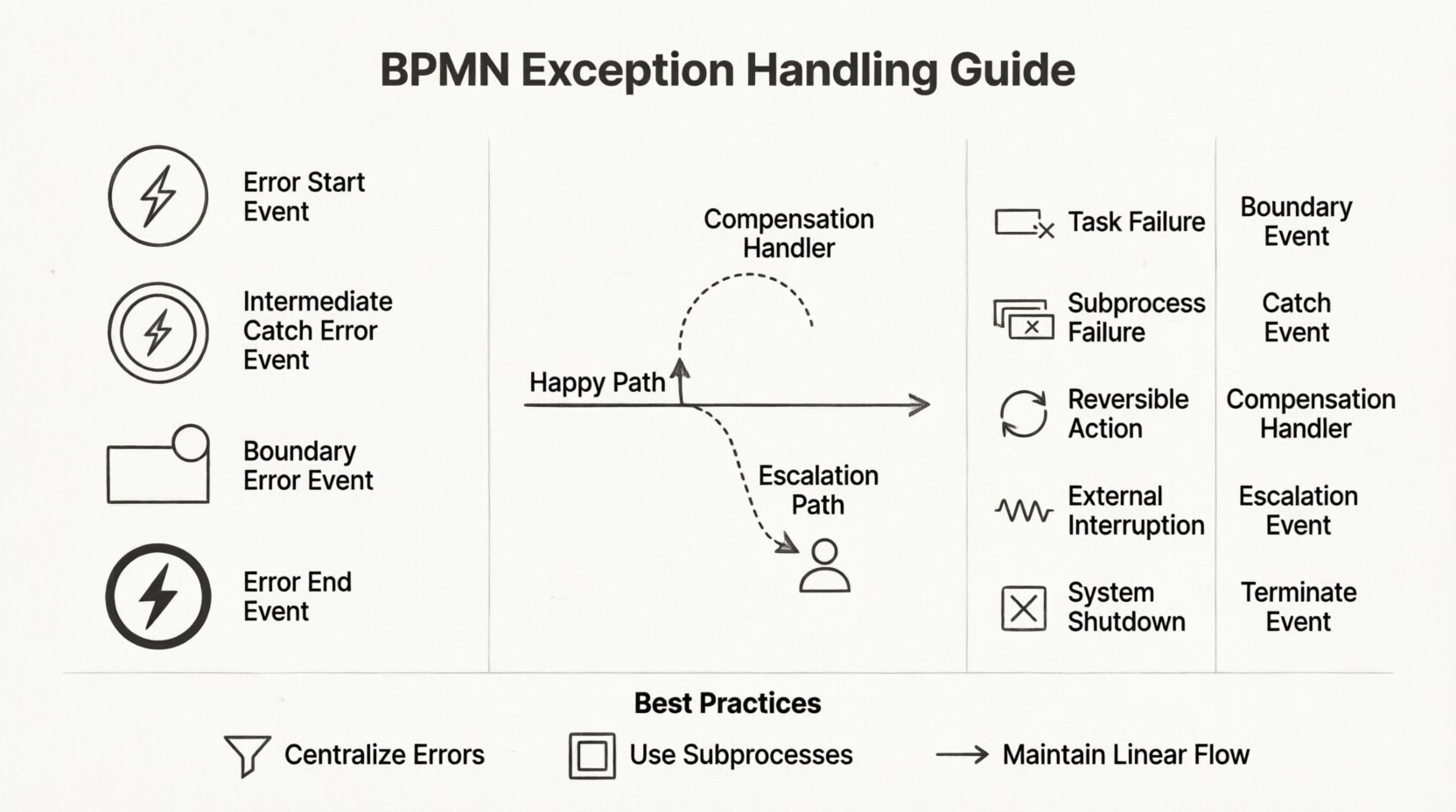
⚠️ La anatomía de un evento de error
Los errores en BPMN son distintos de los mensajes o señales generales. Están específicamente diseñados para manejar fallas del sistema, fallas de validación o perturbaciones externas. BPMN define tres formas principales de incorporar estos errores en un flujo:
1. Eventos de inicio de error
Un evento de inicio de error inicia un proceso desencadenado por un fallo en otra parte. Esto es útil para sistemas de monitoreo. Por ejemplo, si una pasarela de pagos falla, un evento de inicio de error puede desencadenar un flujo de trabajo de notificación para alertar al equipo de finanzas. Permite que el sistema responda de forma asíncrona a los fallos sin bloquear el flujo principal de la transacción.
2. Eventos intermedios de captura de error
Estos eventos detienen un proceso para esperar una condición de error. A diferencia de un evento intermedio de mensaje estándar, que espera comunicación, este espera una señal de error específica. Se utiliza comúnmente para:
- Capturar errores que suben desde subprocesos.
- Implementar lógica de reintento volviendo al paso anterior.
- Dirigir el proceso a un subproceso especializado de manejo de errores.
3. Eventos de borde de error
Este es quizás el método más común para manejar excepciones dentro de una tarea. Un evento de borde de error se adjunta al borde de una tarea o subproceso. Si ocurre un error mientras se ejecuta esa actividad específica, el flujo se desvía inmediatamente hacia la ruta conectada al evento de borde. Esto mantiene el flujo principal limpio porque la lógica normal permanece sin alterar hasta que realmente ocurre un error.
4. Eventos de finalización de error
Cuando un error no puede recuperarse, un evento de finalización de error termina la instancia del proceso. Es fundamental definir qué información se captura en esta etapa. Los metadatos sobre el código de error o el mensaje deben registrarse antes de que se cierre la instancia. Esto garantiza que los registros de auditoría permanezcan intactos incluso después de un fallo del proceso.
🔄 Compensación: Deshacer acciones
No todas las excepciones requieren terminación. A veces, un proceso debe revertirse a un estado anterior. Aquí es donde entran en juegoManejadores de compensación entran en juego. En BPMN, la compensación es la acción de revertir una actividad completada. Esto es vital para transacciones que implican liquidaciones financieras, actualizaciones de inventario o entrada de datos.
Cuando un proceso alcanza un punto en el que debe deshacerse un paso anterior, el modelo debe definir un límite de compensación. Esto implica:
- Definir la actividad específica que requiere un deshacerse.
- Especificar el flujo de compensación que ejecuta la acción inversa.
- Asegurarse de que el flujo de compensación sea idempotente (seguro para ejecutarse múltiples veces).
Considere un proceso de aprobación de préstamos. Si una solicitud de cliente se aprueba pero falla la generación del contrato posterior, el estado de aprobación debe revocarse. Un manejador de compensación asegura que el estado «Aprobado» se revertirá a «Pendiente» sin intervención manual.
📊 Comparación de estrategias de manejo de excepciones
La selección del mecanismo adecuado depende de la naturaleza del fallo. La tabla a continuación indica cuándo utilizar constructos específicos de BPMN para el manejo de excepciones.
| Tipo de excepción | Elemento BPMN | Mejor caso de uso |
|---|---|---|
| Fallo de tarea | Evento de error en el límite | Falla una tarea específica, se necesita reintento local o alerta. |
| Fallo del subproceso | Evento de captura intermedio (global) | Falla todo el subproceso, se necesita una respuesta de alto nivel. |
| Acción reversible | Manejador de compensación | Necesidad de deshacer pasos completados tras un fallo posterior. |
| Interrupción externa | Evento de escalada | Requiere gestión humana o cambio en la política externa. |
| Apagado del sistema | Evento de terminación | El proceso debe finalizar inmediatamente debido a un error crítico. |
🚨 Escaladas frente a errores
Es importante distinguir entre un Error y una Escalada. Aunque ambos representan desviaciones, tienen propósitos semánticos diferentes.
- Errores:Fallas técnicas o lógicas. El sistema no puede continuar debido a una condición rota (por ejemplo, formato de datos inválido, recurso faltante).
- Escaladas: Fallos procedimentales o de gestión. El proceso no puede continuar porque una condición requiere atención humana o una anulación de política (por ejemplo, límite de aprobación excedido, incumplimiento de SLA).
El uso de eventos de escalada te permite modelar el aspecto humano de las excepciones. Cuando ocurre una escalada, el proceso puede redirigirse a una tarea manual para su revisión. Esto mantiene la lógica automatizada separada de la lógica de toma de decisiones, preservando la claridad del diagrama.
🕸️ Evitando la trampa del «espagueti»
Uno de los desafíos más comunes en BPMN es el desorden visual que ocurre al agregar flujos de excepción. Si cada tarea tiene un evento de borde que conduce a un punto final diferente, el diagrama se vuelve ilegible. Para mantener la integridad lógica sin comprometer la claridad visual, sigue estos principios estructurales:
1. Centralizar el manejo de errores
En lugar de crear rutas únicas para cada error menor, agrupa los errores similares. Por ejemplo, si tres tareas diferentes pueden fallar debido a un tiempo de espera de la base de datos, redirige los tres eventos de borde a un único subproceso de «Manejo de errores del sistema». Esto reduce el número de líneas que cruzan el diagrama.
2. Usar subprocesos para la complejidad
Si un flujo de excepción implica múltiples pasos (por ejemplo, registro, notificación, reintento, deshacer), encapsúlalo en un subproceso. No ensucies el diagrama principal con los detalles de la lógica de recuperación. Esto mantiene la vista de alto nivel limpia y te permite profundizar en el manejo de excepciones solo cuando sea necesario.
3. Mantener un flujo lineal cuando sea posible
Incluso con excepciones, el proceso debería sentirse idealmente lineal. Evita crear bucles que retrocedan demasiado en el proceso. Si es necesario un bucle de reintento, limita el número de iteraciones o un intervalo de tiempo específico. Los bucles infinitos pueden hacer que el motor del proceso se bloquee o genere registros excesivos.
🛡️ Garantizando la integridad de los datos
Cuando ocurre una excepción, el estado de los datos suele ser el mayor riesgo. Un proceso podría haber actualizado un registro de la base de datos en el Paso 1, pero fallar en el Paso 2. Si el proceso termina, ese registro queda en un estado incompleto. Para manejar esto:
- Define los límites de transacción:Asegúrate de que las tareas que actualizan datos compartidos estén agrupadas lógicamente. Si una tarea falla, el sistema debe saber si debe deshacer los cambios de datos asociados a esa tarea.
- Registra el contexto de la excepción:Cuando se activa un evento final de error, asegúrate de que las variables del proceso que contienen los detalles del error se guarden en un registro persistente antes de que finalice la instancia. Esto es vital para depurar más adelante.
- Usa la correlación de mensajes:Si el proceso implica sistemas externos, usa claves de correlación para asegurarte de que el mensaje de error se asocie con la instancia de proceso correcta.
🧪 Prueba de rutas de excepción
Un modelo de proceso solo es tan bueno como su capacidad para manejar la realidad. Probar flujos de excepción requiere una mentalidad diferente a la de probar caminos felices. Debes simular condiciones de fallo.
Los escenarios clave de prueba incluyen:
- Condiciones de borde:¿Qué ocurre si un campo está vacío? ¿Y si un número es negativo?
- Escenarios de tiempo de espera:¿Qué ocurre si un sistema se queda colgado durante 30 segundos?
- Fallos concurrentes:¿Qué ocurre si dos instancias del proceso intentan actualizar el mismo registro simultáneamente?
- Éxito en la recuperación:Si el sistema reintenta después de un fallo, ¿el proceso se completa con éxito, o entra en un bucle infinito?
📝 Mejores prácticas para el mantenimiento
Con el tiempo, los procesos evolucionan. Los requisitos de manejo de excepciones cambian conforme las reglas de negocio se modifican. Para mantener sus modelos BPMN mantenibles:
- Control de versiones:Siempre rastree los cambios en la lógica de excepciones. Un cambio en el manejo de errores puede afectar los informes de cumplimiento.
- Documentación:Agregue comentarios a los eventos de borde complejos. Expliquepor quéexiste una ruta de error específica. Los analistas futuros podrían no entender el contexto empresarial sin ello.
- Estandarización:Establezca convenciones de nomenclatura para los eventos de error. Utilice códigos (por ejemplo, “ERR_001”) de forma consistente en todos los procesos para simplificar la depuración.
- Ciclos de revisión:Revise periódicamente las rutas de excepción. ¿Existen rutas que nunca se toman? ¿Existen rutas que son demasiado complejas? Simplifique cuando sea posible.
🔍 Errores comunes que deben evitarse
Incluso modeladores experimentados pueden caer en trampas al diseñar flujos de excepción. Esté atento a estos errores comunes:
- Ignorar fallas silenciosas:Solo porque una tarea no lance una excepción no significa que haya tenido éxito. Asegúrese de que la lógica de validación sea explícita.
- Sobrecargar los puertas de enlace:No utilice puertas de enlace X para manejar errores. Utilice en su lugar eventos de error. Las puertas de enlace son para ramificaciones lógicas, no para capturar excepciones.
- Rutas huérfanas:Asegúrese de que cada evento de borde tenga un destino claro. Un error que se captura pero no conduce a ningún lado es un callejón sin salida.
- Mezclar tipos de lógica:No mezcle eventos de mensaje y eventos de error en el mismo borde. Tienen propósitos diferentes y pueden confundir al motor de ejecución.
🚀 El impacto de procesos resilientes
Construir procesos que manejen eficazmente las excepciones es una inversión en estabilidad operativa. Cuando un proceso es resiliente, reduce la carga sobre los equipos de soporte. Los errores se capturan automáticamente, se registran correctamente y se redirigen a los manejadores adecuados. Esto conduce a:
- Mayor satisfacción del cliente debido a tiempos de recuperación más rápidos.
- Reducción de la intervención manual para fallas rutinarias.
- Mejor calidad de los datos, ya que los mecanismos de reintegro evitan actualizaciones parciales.
- Garantía de cumplimiento, ya que todos los estados de error se rastrean y auditan.
Al tratar los flujos de excepción como un elemento de primera clase en su diseño BPMN, crea sistemas que son robustos y confiables. El objetivo no es eliminar errores, sino asegurarse de que, cuando ocurran, el proceso continúe funcionando o se detenga de manera controlada.
🏁 Reflexiones finales sobre la integridad de la lógica
Una modelización BPMN efectiva requiere un equilibrio entre el flujo ideal y los fallos reales. Al utilizar correctamente los eventos de error, los manejadores de compensación y los eventos de escalada, puede crear diagramas que reflejen la verdadera complejidad de las operaciones empresariales. Recuerde que la claridad es reina. Un modelo de proceso debe ser comprensible incluso cuando falla. Enfóquese en mantener una estructura limpia, documentar su lógica y probar rigurosamente sus rutas de recuperación. Este enfoque garantiza que sus procesos empresariales permanezcan funcionales y adaptables en cualquier entorno.