













Concevoir des flux de travail transactionnels robustes exige plus que la modélisation standard. Lorsque les systèmes traitent des milliers d’opérations par seconde, les subtilités du modèle et de la notation des processus métiers (BPMN) deviennent critiques. Ce guide explore des modèles avancés spécifiquement adaptés aux environnements à haut volume. Nous nous concentrons sur l’intégrité structurelle, la gestion de la concurrence et l’optimisation des performances sans dépendre d’outils spécifiques aux fournisseurs.
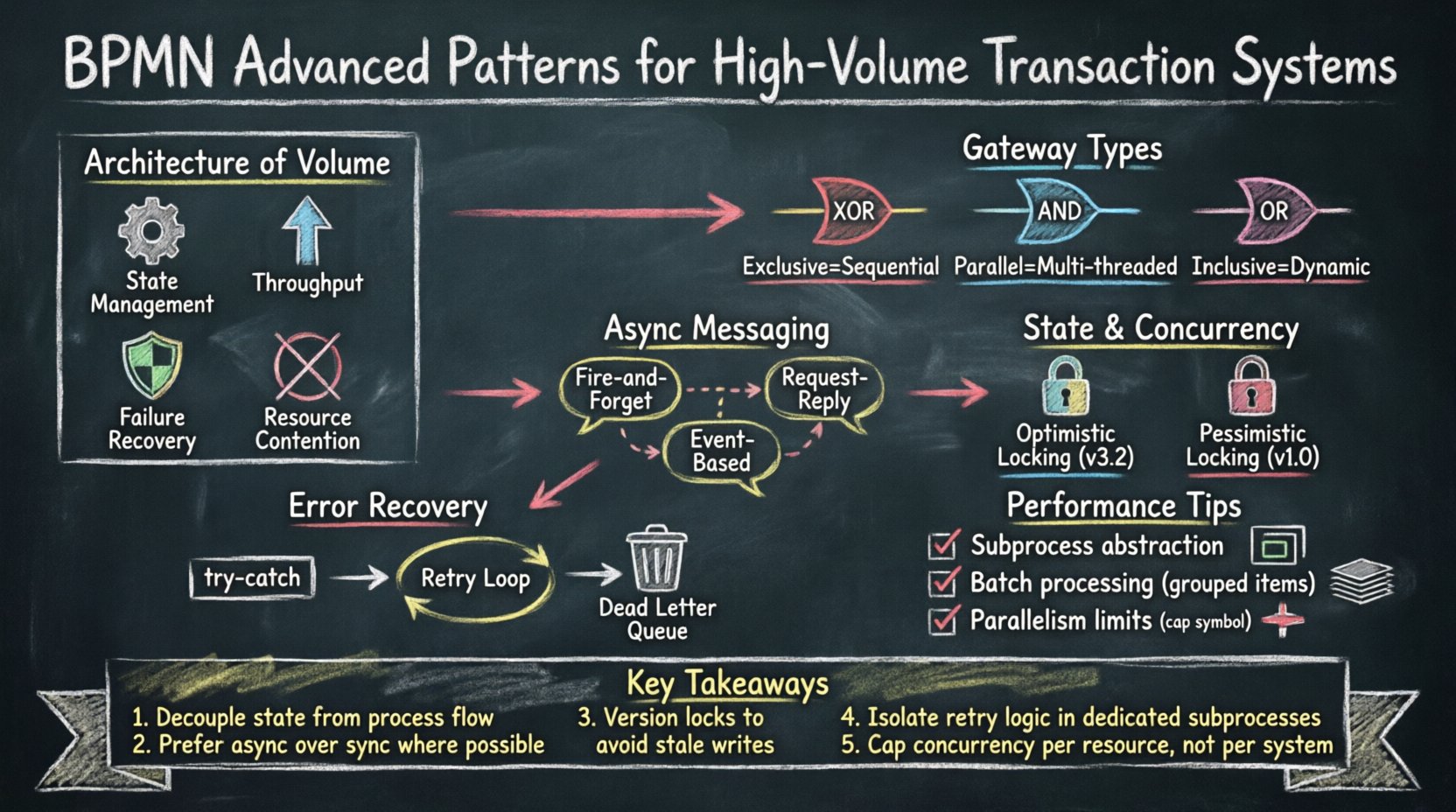
📊 L’architecture du volume
Les systèmes de transactions à haut volume diffèrent fondamentalement des flux opérationnels standards. Dans un processus métier typique, une latence acceptable est tolérée, et l’intervention humaine est fréquente. Dans un moteur transactionnel, chaque milliseconde compte, et l’automatisation doit être absolue. Le modèle de processus agit comme le plan directeur pour le contrôle de concurrence et l’allocation des ressources.
Lorsqu’on évolue vers des millions d’enregistrements, plusieurs facteurs modifient la priorité de la conception :
- Gestion d’état : Chaque étape du processus doit préserver l’intégrité des données.
- Débit : Le modèle doit permettre l’exécution parallèle là où cela est logiquement sûr.
- Récupération après erreur : Les mécanismes d’annulation doivent être explicites et récupérables.
- Contestation des ressources : Les stratégies de verrouillage affectent le nombre de processus pouvant s’exécuter simultanément.
Modéliser ces contraintes exige un changement de pensée linéaire vers une logique distribuée. Les éléments standards du BPMN fonctionnent différemment sous charge. Comprendre ces comportements permet aux architectes de concevoir des systèmes stables même en période de pointe.
🔀 Mécanismes de passerelle à grande échelle
Les passerelles déterminent le flux de contrôle. Dans les systèmes à haut volume, le choix de la passerelle a un impact significatif sur les performances. Une utilisation incorrecte peut créer des goulets d’étranglement où tous les threads doivent attendre une seule condition, annulant ainsi la parallélisation.
Trois types principaux de passerelles nécessitent un choix soigneux :
- Passerelles exclusives : Dirige vers un seul chemin en fonction des données. Faible surcharge, mais prise de décision séquentielle.
- Passerelles parallèles : Lance plusieurs chemins simultanément. Haut débit, mais nécessite une synchronisation.
- Passerelles inclusives : Dirige vers plusieurs chemins en fonction de conditions. Suivi d’état complexe requis.
| Type de passerelle | Impact sur la concurrence | Meilleur cas d’utilisation |
|---|---|---|
| Passerelle exclusive | Faible (séquentiel) | Logique de décision simple |
| Passerelle parallèle | Élevé (multithreadé) | Étapes d’validation indépendantes |
| Passerelle inclusive | Moyen (dynamique) | Drapeaux de fonctionnalité conditionnels |
Pour les systèmes transactionnels, les passerelles parallèles sont souvent préférées pour diviser le travail, à condition que les processus en aval soient indépendants. Si les processus en aval partagent une ressource, telle qu’un enregistrement de base de données, le modèle doit inclure une logique de synchronisation. Sans cela, des conditions de course surviennent, entraînant une corruption des données.
📨 Modèles de messagerie asynchrone
Les opérations bloquantes réduisent le débit. Si un processus attend une réponse d’un système externe, tout le thread de transaction est occupé. La messagerie asynchrone déconnecte le processus du temps de réponse des services dépendants.
Ce modèle utilise des événements intermédiaires de message. Au lieu d’attendre une réponse avant de continuer, le processus envoie un signal et passe à un état d’attente. Cela permet au moteur de traiter d’autres transactions pendant que l’original attend une confirmation.
- Envoyer et oublier : Envoyer des données sans attendre de réponse immédiate. Utiliser lorsque l’action n’est pas critique.
- Demande-réponse : Envoyer un message et attendre un ID de corrélation spécifique. Utiliser lorsque la cohérence des données est requise.
- Basé sur les événements : Écouter des événements externes pour déclencher l’étape suivante. Utiliser pour des microservices déconnectés.
Mettre en œuvre cela nécessite un broker de messages fiable. Le modèle de processus doit gérer les cas où les messages sont perdus ou retardés. Des événements temporisés accompagnent souvent les événements de message pour éviter une attente indéfinie. Si un message n’arrive pas dans un délai défini, le processus doit déclencher un mécanisme de réessai ou d’alerte.
⚙️ Gestion de l’état et de la concurrence
La gestion d’état est le pilier de la cohérence transactionnelle. Dans un environnement distribué, une instance de processus représente une unité de travail spécifique. Gérer l’état de cette unité garantit qu’aucun processus ne corrompt les mêmes données.
Les points clés à considérer incluent :
- Verrouillage optimiste : Permettre à plusieurs processus de lire les données. Mettre à jour uniquement si aucun autre processus n’a modifié les données depuis la lecture.
- Verrouillage pessimiste : Verrouiller les données immédiatement à l’accès. Empêche les autres processus de lire ou d’écrire.
- Versioning : Attacher des numéros de version aux objets de données. Vérifier la version avant de valider les modifications.
Le modèle de processus doit refléter ces stratégies de verrouillage. Si une tâche nécessite un verrou, le diagramme BPMN doit afficher un nœud Tâche qui effectue l’opération de verrouillage. Cela rend la contrainte visible pour les développeurs et les auditeurs.
Les processus longs posent des défis uniques. Si une transaction dure des heures, le moteur doit persister l’état. Les événements intermédiaires et les événements intermédiaires de message aident à diviser les tâches longues en morceaux gérables. Cela évite l’épuisement de la mémoire et permet au système de se rétablir après un crash sans perdre de progression.
🛡️ Compensation et récupération d’erreurs
Les défaillances sont inévitables dans les systèmes à fort volume. Le modèle de processus doit définir explicitement la manière de gérer ces défaillances. La gestion standard des erreurs implique des exceptions. En BPMN, cela implique des événements intermédiaires d’erreur et des événements limites.
La compensation consiste à annuler un travail. Si une transaction échoue en cours de route, le système doit annuler les modifications pour préserver l’intégrité des données. Cela diffère du simple retour en arrière. La compensation permet des annulations partielles.
Les modèles efficaces de gestion des erreurs incluent :
- Blocs Try-Catch :Encapsulez une section du processus. Si une erreur survient, redirigez vers le gestionnaire de compensation.
- Boucles de réessai :Tentez l’action un nombre défini de fois avant de la faire évoluer.
- Files de lettres mortes :Déplacez les transactions échouées vers une file distincte pour un examen manuel.
| Stratégie | Complexité | Capacité de récupération |
|---|---|---|
| Réessai immédiat | Faible | Pannes réseau temporaires |
| Retard exponentiel | Moyen | Surcharge du système |
| Gestionnaire de compensation | Élevé | Erreurs de logique métier |
Lors de la conception des gestionnaires de compensation, assurez-vous qu’ils sont idempotents. L’exécution de la logique de compensation deux fois ne doit pas entraîner d’erreurs supplémentaires. Cela est crucial car l’événement d’erreur lui-même pourrait être déclenché plusieurs fois si le système redémarre.
📈 Affinement des performances par modélisation
L’optimisation commence à la phase de conception. Un modèle bien structuré réduit la surcharge d’exécution. Plusieurs techniques de modélisation influencent directement les métriques de performance.
Abstraction des sous-processus
Utiliser des sous-processus aide à gérer la complexité. Un sous-processus réduit cache les détails internes, réduisant ainsi la charge cognitive sur le moteur lors du parcours du diagramme. Toutefois, les sous-processus étendus permettent un débogage détaillé. Pour les systèmes à fort volume, conservez la logique complexe dans des sous-processus distincts. Cela isole les défaillances et permet un réglage spécifique de la logique interne.
Traitement par lots
Le traitement des enregistrements un par un est inefficace. Le traitement par lots regroupe les transactions. En BPMN, cela est modélisé à l’aide d’une structure de boucle. Le processus itère sur une collection d’éléments, traitant un certain nombre d’éléments avant de valider dans la base de données. Cela réduit le nombre de connexions à la base de données et de validations de transaction.
- Taille fixe du lot : Traitez exactement 100 éléments par validation.
- Lot basé sur le temps : Traitez les éléments jusqu’à ce que 5 secondes soient écoulées.
- Lot basé sur le volume : Traitez les éléments jusqu’à ce que la taille totale atteigne un seuil.
Limites de parallélisme
Un parallélisme illimité peut surcharger les ressources du système. Le modèle doit définir des limites de concurrence. Cela est souvent géré par le moteur d’exécution, mais la conception du processus doit respecter ces limites. Utilisez des seuils de passerelle pour limiter le nombre de chemins parallèles. Par exemple, limitez le nombre de tâches de validation en cours d’exécution afin d’éviter la saturation du CPU.
🔍 Surveillance et optimisation
Une fois le système en production, la surveillance est essentielle. Le modèle de processus doit inclure des repères pour les métriques clés. Ces repères aident à identifier les goulets d’étranglement dans l’exécution réelle.
Les métriques clés à suivre incluent :
- Durée : Combien de temps chaque tâche prend.
- Débit : Combien d’instances sont terminées par heure.
- Taux d’erreurs : Le pourcentage d’instances qui échouent.
- Profondeur de la file d’attente : Combien d’instances attendent des ressources.
En corrélant ces métriques avec le diagramme de processus, les équipes peuvent identifier précisément où se produisent les délais. S’agit-il de l’écriture dans la base de données ? S’agit-il de l’appel à une API externe ? Le modèle sert de carte pour ces diagnostics.
🔒 Sécurité et conformité
Les systèmes à haut volume traitent souvent des données sensibles. Les contrôles de sécurité doivent être intégrés au flux du processus. Les tâches d’authentification et d’autorisation doivent être des nœuds explicites dans le diagramme.
- Contrôle d’accès : Assurez-vous que seuls les utilisateurs autorisés peuvent déclencher des tâches spécifiques.
- Masquage des données : Appliquez les règles de masquage avant que les données ne soient transmises aux services externes.
- Traçabilité des audits : Enregistrez chaque changement d’état à des fins de conformité.
Les exigences de conformité imposent souvent un ordre spécifique des opérations. Par exemple, le chiffrement des données doit avoir lieu avant le stockage. BPMN permet de visualiser ces contraintes. Cela garantit que les exigences réglementaires sont respectées sans dépendre de la mémoire des développeurs.
🔄 Amélioration continue
Les modèles de processus ne sont pas statiques. À mesure que les règles métier évoluent, le modèle doit évoluer lui aussi. La versioning de la définition du processus est essentielle. Cela permet au système d’exécuter des versions anciennes tout en déployant de nouvelles versions.
- Migration : Définissez le comportement des instances créées sous la version 1 lorsqu’elles sont exécutées sous la version 2.
- Tests A/B : Exécutez différentes versions de processus sur des sous-ensembles de trafic pour comparer les performances.
- Boucles de rétroaction :Utilisez les données de production pour affiner le modèle.
Des revues régulières du modèle de processus garantissent qu’il reste en accord avec les capacités du système. Si un goulot d’étranglement est identifié, le modèle peut être ajusté pour répartir la charge de manière plus équilibrée. Cette approche itérative maintient la santé du système au fil du temps.
📋 Résumé des techniques avancées
Mettre en œuvre le BPMN pour les systèmes de transactions à fort volume nécessite un changement de mentalité. Ce n’est pas seulement dessiner des boîtes et des flèches. Il s’agit de modéliser la concurrence, l’état et les défaillances. Les modèles abordés ici fournissent un cadre pour construire des systèmes résilients.
Les points clés incluent :
- Utilisez des passerelles parallèles pour maximiser le débit là où l’indépendance existe.
- Découplez les dépendances externes en utilisant des événements de message asynchrones.
- Implémentez des gestionnaires de compensation pour une récupération d’erreurs complexe.
- Regroupez les opérations pour réduire la surcharge de la base de données.
- Surveillez les métriques par rapport au modèle pour identifier les goulets d’étranglement.
En suivant ces modèles, les architectes peuvent créer des modèles de processus évolutifs. Le modèle devient une spécification fiable pour le moteur d’exécution, garantissant que les transactions à fort volume sont traitées avec précision et stabilité.
Cette publication est également disponible en Deutsch, English, Español, فارسی, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 : liste des langues séparées par une virgule, 繁體中文 : dernière langue.