













Diseñar flujos de trabajo transaccionales robustos requiere más que modelado estándar. Cuando los sistemas procesan miles de operaciones por segundo, los matices del Modelo y Notación de Procesos de Negocio (BPMN) se vuelven críticos. Esta guía explora patrones avanzados específicamente adaptados para entornos de alto volumen. Nos enfocamos en la integridad estructural, la gestión de concurrencia y la optimización del rendimiento sin depender de herramientas específicas de proveedores.
📊 La Arquitectura del Volumen
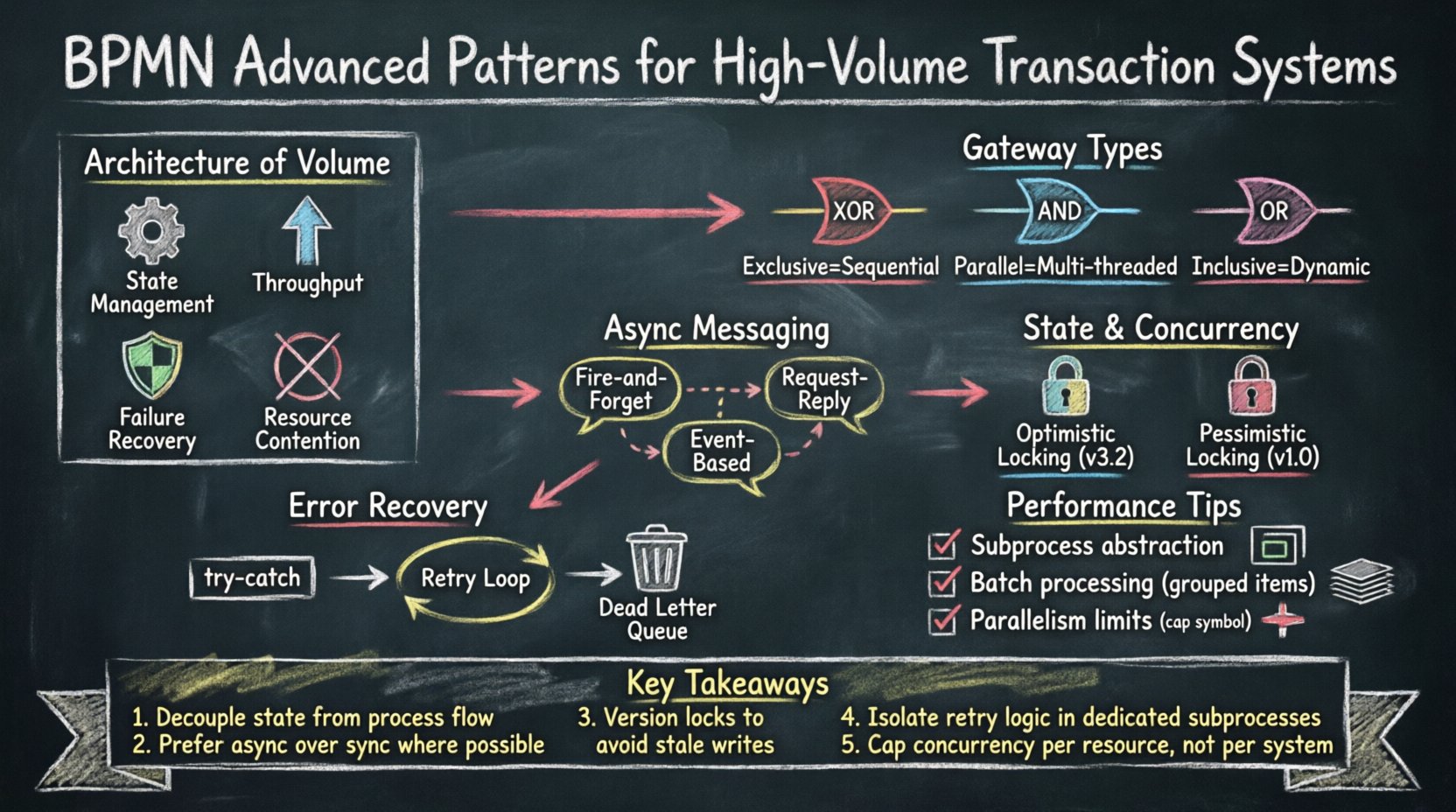
Los sistemas de transacciones de alto volumen difieren fundamentalmente de los flujos de trabajo operativos estándar. En un proceso de negocio típico, la latencia es aceptable y la intervención humana es común. En un motor transaccional, los milisegundos importan y la automatización debe ser absoluta. El modelo de proceso actúa como el plano maestro para el control de concurrencia y la asignación de recursos.
Cuando se escala a millones de registros, varios factores cambian la prioridad del diseño:
- Gestión de estado:Cada paso en el proceso debe mantener la integridad de los datos.
- Rendimiento:El modelo debe permitir la ejecución paralela allí donde sea lógicamente seguro.
- Recuperación ante fallos:Los mecanismos de reintegro deben ser explícitos y recuperables.
- Contención de recursos:Las estrategias de bloqueo afectan cuántos procesos pueden ejecutarse simultáneamente.
Modelar estas restricciones requiere un cambio de pensamiento lineal hacia lógica distribuida. Los elementos estándar de BPMN funcionan de manera diferente bajo carga. Comprender estos comportamientos permite a los arquitectos construir sistemas que permanecen estables durante los picos de demanda.
🔀 Mecanismos de puerta de enlace a escala
Las puertas de enlace dictan el flujo de control. En sistemas de alto volumen, la elección de la puerta de enlace impacta significativamente el rendimiento. Su uso incorrecto puede crear cuellos de botella donde todos los hilos deben esperar a una sola condición, anulando la paralelización.
Tres tipos principales de puertas de enlace requieren una selección cuidadosa:
- Puertas de enlace exclusivas:Dirigen a una única ruta según los datos. Bajo costo de procesamiento, pero toma de decisiones secuenciales.
- Puertas de enlace paralelas:Generan múltiples rutas simultáneamente. Alto rendimiento, pero requiere sincronización.
- Puertas de enlace inclusivas:Dirigen a múltiples rutas según condiciones. Se requiere seguimiento de estado complejo.
| Tipo de puerta de enlace | Impacto en concurrencia | Mejor caso de uso |
|---|---|---|
| Puerta de enlace exclusiva | Bajo (secuencial) | Lógica de decisión simple |
| Puerta de enlace paralela | Alto (multihilo) | Pasos de validación independientes |
| Puerta de inclusión | Medio (dinámico) | Banderas de características condicionales |
Para sistemas transaccionales, con frecuencia se prefieren las puertas paralelas para dividir el trabajo, siempre que los procesos posteriores sean independientes. Si los procesos posteriores comparten un recurso, como un registro de base de datos, el modelo debe incluir lógica de sincronización. Sin esto, ocurren condiciones de carrera, lo que conduce a corrupción de datos.
📨 Patrones de mensajería asíncrona
Las operaciones bloqueantes reducen el rendimiento. Si un proceso espera una respuesta de un sistema externo, todo el hilo de transacción queda ocupado. La mensajería asíncrona desacopla el proceso del tiempo de respuesta de los servicios dependientes.
Este patrón utiliza eventos de mensaje intermedios. En lugar de esperar una respuesta antes de continuar, el proceso envía una señal y pasa a un estado de espera. Esto permite que el motor procese otras transacciones mientras la original espera confirmación.
- Lanzar y olvidar: Enviar datos sin esperar una respuesta inmediata. Usar cuando la acción no sea crítica.
- Solicitud-respuesta: Enviar un mensaje y esperar un ID de correlación específico. Usar cuando se requiera consistencia de datos.
- Basado en eventos: Escuchar eventos externos para desencadenar el siguiente paso. Usar para microservicios desacoplados.
Implementar esto requiere un broker de mensajes confiable. El modelo de proceso debe manejar casos en los que los mensajes se pierdan o se retrasen. Los eventos de temporizador a menudo acompañan a los eventos de mensaje para evitar esperas indefinidas. Si un mensaje no llega dentro de un marco de tiempo establecido, el proceso debe activar un mecanismo de reintento o alerta.
⚙️ Gestión del estado y concurrencia
La gestión del estado es la base de la consistencia transaccional. En un entorno distribuido, una instancia de proceso representa una unidad específica de trabajo. Gestionar el estado de esta unidad asegura que ningún par de procesos corrompa los mismos datos.
Las consideraciones clave incluyen:
- Bloqueo optimista: Permitir que múltiples procesos lean datos. Actualizar solo si ningún otro proceso modificó los datos desde la lectura.
- Bloqueo pesimista: Bloquear los datos inmediatamente al acceder a ellos. Evita que otros procesos lean o escriban.
- Versionado: Asociar números de versión a los objetos de datos. Verificar la versión antes de confirmar los cambios.
El modelo de proceso debe reflejar estas estrategias de bloqueo. Si una tarea requiere un bloqueo, el diagrama BPMN debe mostrar un nodo de Tarea que realice la operación de bloqueo. Esto hace que la restricción sea visible para desarrolladores y auditores.
Los procesos de larga duración presentan desafíos únicos. Si una transacción tarda horas, el motor debe persistir el estado. Los eventos intermedios y los eventos intermedios de mensaje ayudan a dividir tareas largas en fragmentos manejables. Esto evita el agotamiento de memoria y permite que el sistema se recupere de fallos sin perder progreso.
🛡️ Compensación y recuperación de errores
Los fallos son inevitables en sistemas de alto volumen. El modelo de proceso debe definir explícitamente cómo manejar estos fallos. El manejo estándar de errores implica excepciones. En BPMN, esto implica eventos intermedios de error y eventos de borde.
La compensación es la acción de deshacer trabajo. Si una transacción falla a mitad de camino, el sistema debe revertir los cambios para mantener la integridad de los datos. Esto es distinto del simple rollback. La compensación permite reversas parciales.
Los patrones efectivos de manejo de errores incluyen:
- Bloques Try-Catch:Encapsula una sección del proceso. Si ocurre un error, redirige al manejador de compensación.
- Bucles de reintento:Intenta la acción un número determinado de veces antes de aumentar el nivel de severidad.
- Colas de cartas muertas:Mueve las transacciones fallidas a una cola separada para revisión manual.
| Estrategia | Complejidad | Capacidad de recuperación |
|---|---|---|
| Reintento inmediato | Bajo | Fallos temporales de red |
| Retraso exponencial | Medio | Sobrecarga del sistema |
| Manejador de compensación | Alto | Errores de lógica de negocio |
Al diseñar manejadores de compensación, asegúrate de que sean idempotentes. Ejecutar la lógica de compensación dos veces no debería causar errores adicionales. Esto es crucial porque el evento de error en sí mismo podría activarse múltiples veces si el sistema se reinicia.
📈 Ajuste de rendimiento mediante modelado
La optimización comienza en la fase de diseño. Un modelo bien estructurado reduce la sobrecarga en tiempo de ejecución. Varias técnicas de modelado influyen directamente en las métricas de rendimiento.
Abstracción de subprocesos
El uso de subprocesos ayuda a gestionar la complejidad. Un subproceso colapsado oculta los detalles internos, reduciendo la carga cognitiva sobre el motor al recorrer el diagrama. Sin embargo, los subprocesos expandidos permiten una depuración detallada. En sistemas de alto volumen, mantén la lógica compleja en subprocesos separados. Esto aísla los fallos y permite un ajuste específico de la lógica interna.
Procesamiento por lotes
Procesar registros uno por uno es ineficiente. El procesamiento por lotes agrupa las transacciones. En BPMN, esto se modela utilizando una estructura de bucle. El proceso itera sobre una colección de elementos, procesando un número determinado antes de confirmar en la base de datos. Esto reduce el número de conexiones a la base de datos y de confirmaciones de transacciones.
- Tamaño de lote fijo:Procesa exactamente 100 elementos por confirmación.
- Lote basado en tiempo:Procesa elementos hasta que hayan pasado 5 segundos.
- Lote basado en volumen:Procese elementos hasta que el tamaño total alcance un umbral.
Límites de paralelismo
El paralelismo ilimitado puede sobrecargar los recursos del sistema. El modelo debe definir límites de concurrencia. Esto generalmente se maneja mediante el motor de ejecución, pero el diseño del proceso debe respetar estos límites. Utilice umbrales de puerta para limitar el número de caminos paralelos. Por ejemplo, limite el número de tareas de validación que se ejecutan al mismo tiempo para evitar la saturación de la CPU.
🔍 Monitoreo y optimización
Una vez que el sistema está en funcionamiento, el monitoreo es esencial. El modelo de proceso debe incluir marcadores para métricas clave. Estos marcadores ayudan a identificar cuellos de botella en la ejecución real.
Las métricas clave que se deben monitorear incluyen:
- Duración: Cuánto tiempo tarda cada tarea.
- Rendimiento: Cuántas instancias se completan por hora.
- Tasa de errores: El porcentaje de instancias que fallan.
- Profundidad de la cola: Cuántas instancias están esperando recursos.
Al correlacionar estas métricas con el diagrama de proceso, los equipos pueden identificar exactamente dónde ocurren los retrasos. ¿Es la escritura en la base de datos? ¿Es la llamada a la API externa? El modelo sirve como mapa para estas diagnósticos.
🔒 Seguridad y cumplimiento
Los sistemas de alto volumen a menudo manejan datos sensibles. Los controles de seguridad deben integrarse en el flujo del proceso. Las tareas de autenticación y autorización deben ser nodos explícitos en el diagrama.
- Control de acceso: Asegúrese de que solo los usuarios autorizados puedan activar tareas específicas.
- Mascaramiento de datos: Aplicar reglas de mascaramiento antes de que los datos se pasen a servicios externos.
- Registros de auditoría: Registrar cada cambio de estado con fines de cumplimiento.
Los requisitos de cumplimiento a menudo dictan un orden específico de operaciones. Por ejemplo, la cifrado de datos debe ocurrir antes del almacenamiento. BPMN permite visualizar estas restricciones. Esto asegura que se cumplan los requisitos regulatorios sin depender de la memoria del desarrollador.
🔄 Mejora continua
Los modelos de proceso no son estáticos. A medida que cambian las reglas de negocio, el modelo debe evolucionar. Versionar la definición del proceso es fundamental. Esto permite que el sistema ejecute versiones antiguas mientras se despliegan nuevas.
- Migración: Defina cómo se comportan las instancias creadas bajo la versión 1 cuando se ejecutan bajo la versión 2.
- Pruebas A/B: Ejecute diferentes versiones del proceso en subconjuntos de tráfico para comparar el rendimiento.
- Bucles de retroalimentación:Utilice datos de producción para perfeccionar el modelo.
Revisiones regulares del modelo de proceso aseguran que permanezca alineado con las capacidades del sistema. Si se identifica un cuello de botella, el modelo puede ajustarse para distribuir la carga de manera más equilibrada. Este enfoque iterativo mantiene la salud del sistema con el tiempo.
📋 Resumen de técnicas avanzadas
Implementar BPMN en sistemas de transacciones de alto volumen requiere un cambio de mentalidad. No se trata solo de dibujar cuadros y flechas. Se trata de modelar concurrencia, estado y fallos. Los patrones discutidos aquí proporcionan un marco para construir sistemas resilientes.
Los puntos clave incluyen:
- Utilice puertas paralelas para maximizar el rendimiento donde exista independencia.
- Desacople las dependencias externas utilizando eventos de mensaje asíncronos.
- Implemente controladores de compensación para la recuperación de errores complejos.
- Agrupe operaciones para reducir la sobrecarga de la base de datos.
- Monitoree las métricas en comparación con el modelo para identificar cuellos de botella.
Al adherirse a estos patrones, los arquitectos pueden crear modelos de proceso escalables. El modelo se convierte en una especificación confiable para el motor de ejecución, asegurando que las transacciones de alto volumen se manejen con precisión y estabilidad.