













Oleh Seorang Insinyur Full-Stack Senior | Laporan Pengalaman Pihak Ketiga dengan Wawasan Praktis & Dampak terhadap Tim
Pendahuluan: Mengapa Alat Ini Mengubah Cara Kami Merancang Basis Data
Sebagai seorang pengembang full-stack senior di startup SaaS yang bergerak cepat, saya telah menyaksikan proses perancangan basis data kami mengalami ujian berat. Dari sketsa terburu-buru di papan tulis hingga refaktor skema menit terakhir yang merusak produksi, basis data sering kali menjadi keterbatasan terbesar dalam alur pengiriman kami.
Kami telah mencoba segalanya: alat ERD, plugin diagram, bahkan DSL khusus untuk definisi skema. Namun tidak satupun dari mereka benar-benar menutup kesenjangan antara tujuan bisnis dan SQL siap produksi—terutama saat onboarding insinyur pemula atau bekerja dengan manajer produk yang tidak teknis.
Kemudian muncul DBModeler AI oleh Visual Paradigm.
Setelah uji coba selama dua minggu bersama tim saya, saya dapat mengatakan tanpa berlebihan: ini adalah alat perancangan basis data yang paling mengubah cara kerja yang pernah saya gunakan dalam lebih dari satu dekade terakhir.
Ini bukan sekadar generator diagram berbasis AI lainnya. Ini adalah mesin desain kolaboratif yang mengubah bahasa alami menjadi skema basis data yang sepenuhnya dinormalisasi, dapat diuji, dan terdokumentasi—semuanya dalam peramban, tanpa konfigurasi awal.

Dalam panduan ini, saya akan membimbing Anda melalui pengalaman nyata kami menggunakan DBModeler AI pada tiga fitur utama: otentikasi pengguna, pendaftaran kursus, dan manajemen pesanan. Saya akan berbagi apa yang berhasil, apa yang tidak, serta bagaimana kami mengintegrasikannya ke dalam alur kerja agile—lengkap dengan tangkapan layar, masukan tim, dan tips yang bisa Anda terapkan segera.
Konsep Kunci bagi Tim Pengembangan (Dilihat Ulang dengan Konteks Nyata)
🎯 AI sebagai Desainer Kolaboratif, Bukan Pengganti
Pengalaman Kami:
Awalnya kami khawatir AI akan “menimpa” model yang dirancang dengan cermat oleh kami. Namun setelah diuji, kami menyadari bahwa AI tidak menggantikan penilaian—melainkan memperkuatnya.
Sebagai contoh, ketika kami menjelaskan ‘seorang siswa dapat mendaftar di beberapa kursus’, AI dengan benar menyimpulkan hubungan banyak-ke-banyak dan menyarankan tabel perantara. Namun kami mampu mengedit kode PlantUML secara langsung untuk menambahkan flag soft-delete dan timestamp audit—sesuatu yang tidak dihasilkan otomatis oleh AI tetapi yang kami butuhkan untuk kepatuhan.
✅ Kesimpulan: AI adalah co-pilot, bukan pengganti. Anda selalu dalam kendali.
🔁 Penyempurnaan Iteratif Berbasis Desain
Pengalaman Kami:
Selama fitur pendaftaran kursus, kami memulai dengan model sederhana: Siswa → Kursus. Setelah AI menghasilkan ERD, kami menyadari bahwa kami perlu melacak status pendaftaran (aktif, dihentikan, gagal). Kami kembali ke Langkah 2, mengedit kelas Pendaftaran di PlantUML, dan meregenerasi skema dalam waktu kurang dari 30 detik.
✅ Kesimpulan: Alur kerja siklik bukan teoritis—ini praktis. Sekarang kami menganggap desain skema seperti sprint, bukan tugas satu kali.
🧪 Uji Sebelum Anda Deploy – Playground Mengubah Semuanya
Pengalaman Kami:
Dulu kami menulis tes integrasi setelah skema di-deploy. Sekarang, kami memvalidasi perilaku sebelum menulis satu baris kode pun.
Di Playground, kami menghasilkan 500 siswa contoh dan mendaftarkannya ke dalam kursus. Kami menjalankan query kompleks seperti:
SELECT s.name, COUNT(e.id) AS jumlah_kursus
FROM siswa s
JOIN pendaftaran e ON s.id = e.id_siswa
WHERE e.status = 'aktif'
GROUP BY s.name
ORDER BY jumlah_kursus DESC;
Query mengembalikan hasil secara instan—tidak perlu menyalakan database lokal. Kami bahkan menguji kasus ekstrem: apa yang terjadi jika seorang siswa menghentikan semua kursus? Logika batasan AI mencegah terbentuknya catatan terlantar, dan kami menemukan kemungkinan kondisi persaingan (race condition) lebih awal.
✅ Putusan: The Playground menghilangkan 80% dari bug skema kami setelah peluncuran.
📐 Normalisasi sebagai Fitur Utama
Pengalaman Kami:
Pengembang pemula kami bingung mengapa AI membagi Kursus menjadi Kursus dan InstrukturKursus. Tapi setelah berjalan melalui langkah-langkah 1NF → 2NF → 3NF, mereka memahami alasan di baliknya—terutama ketika AI menunjukkan bagaimana kelompok berulang dihilangkan.
Kini kami menggunakan langkah ini sebagai modul pelatihan untuk karyawan baru. Ini seperti buku teks hidup tentang teori basis data.
✅ Putusan: Normalisasi kini bukan lagi kotak centang—ini adalah proses yang bisa diajarkan dan terlihat.
🌐 Berdasarkan Browser, Tidak Ada Beban Instalasi
Pengalaman Kami:
Salah satu anggota tim kami menggunakan laptop yang dikunci perusahaan tanpa hak admin. Mereka tidak bisa menginstal Docker atau PostgreSQL. Tapi mereka bergabung dengan proyek melalui aplikasi web, membuat skema, dan berkontribusi dalam desain dalam waktu kurang dari 10 menit.
✅ Putusan: Ini adalah alat basis data yang paling inklusif yang pernah saya gunakan. Onboarding kini menjadi mulus.
Alur Kerja AI 7 Langkah: Penjelajahan Mendalam oleh Seorang Pengembang – Perjalanan Tim Kami
Langkah 1: Masukan Masalah (Masukan Konseptual)
Prompt Kami:
“Bangun sistem untuk mengelola mata kuliah universitas, mahasiswa, dan pendaftaran. Mahasiswa dapat mendaftar di beberapa mata kuliah. Setiap mata kuliah memiliki satu pengajar. Pendaftaran mencatat nilai, waktu pencatatan, dan status (aktif, ditinggalkan, gagal). Semua tabel harus mencakup
created_atdanupdated_at.”
Pendapat Kami:
Generator deskripsi AI membantu kami menyempurnakan masukan kami. Kami menambahkan batasan dan aturan bisnis yang awalnya kami lewatkan.
✅ Kiat: Gunakan poin-poin. AI memprosesnya lebih baik daripada paragraf panjang.
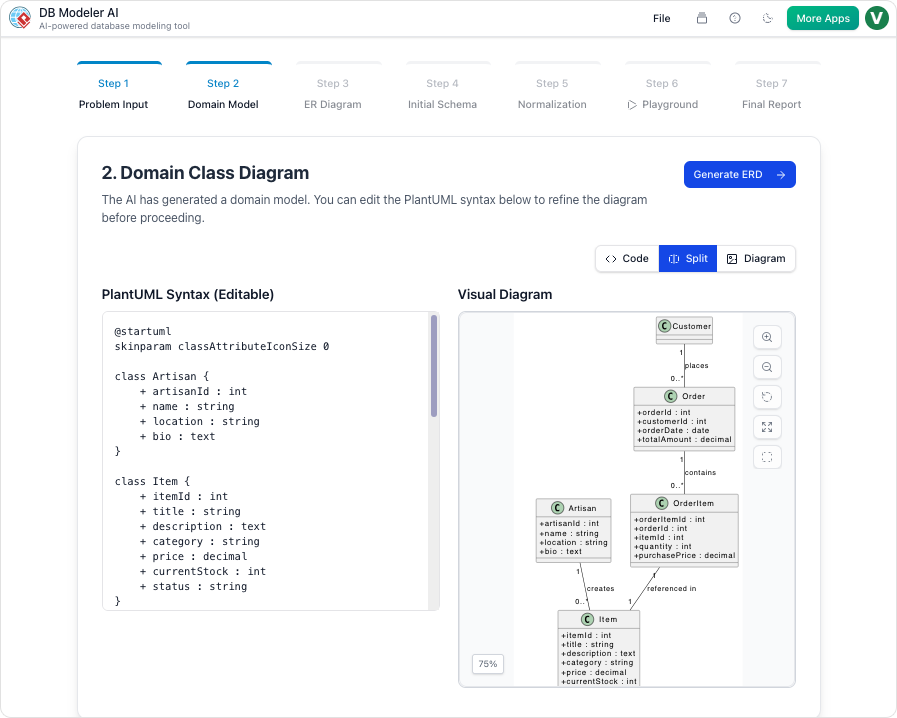
Langkah 2: Model Domain (Pemodelan Konseptual)
Tindakan Kami:
AI menghasilkan model domain berbasis PlantUML. Kami mengganti nama Student menjadi User, menambahkan email, role, dan is_active atribut, dan memperjelas kelas Enrollment kelas.
Pendapat Kami:
Hasil visualisasi langsung dan bersih. Kami berbagi kode PlantUML di Slack, dan tim frontend sudah bisa melihat strukturnya.
✅ Kiat: Gunakan
@catatankomentar dalam PlantUML untuk mendokumentasikan asumsi.
@note kanan
Hubungan ini mungkin memerlukan tabel sambungan jika kita menambahkan penghapusan lunak
@end note
Langkah 3: Diagram ER (Pemodelan Logis)
Tindakan Kami:
AI menghasilkan PK, FK, dan kardinalitas secara otomatis. Kami memperhatikan hubungan 1:N antara Kursus dan Instruktur—tetapi kami menginginkan satu instruktur per kursus, sehingga kami menyesuaikannya menjadi 1:1.
Pendapat Kami:
Kami memeriksa kembali kardinalitas bersama tim. Kesalahan di sini akan menyebabkan anomali data.
✅ Kiat: Selalu validasi hubungan dengan pemilik produk sebelum menyelesaikannya.
Langkah 4: Skema Awal (Generasi Kode Fisik)
Tindakan Kami:
Menghasilkan DDL PostgreSQL dengan created_at, updated_at, dan CHECK kendala.
Pendapat Kami:
Kami menggunakan ini sebagai dasar untuk migrasi Flyway. Tidak lagi ada DDL yang ditulis secara manual—hanya skrip yang dikendalikan versi.
✅ Kiat: Ekspor DDL sejak awal. Kami menyimpan folder
schema/initialdi Git.
Langkah 5: Normalisasi (Optimasi Skema)
Tindakan Kami:
Kami membahas 1NF → 2NF → 3NF. Pada 2NF, AI membagi Pendaftaran menjadi Pendaftaran dan RiwayatPendaftaran untuk menghilangkan ketergantungan parsial.
Pendapat Kami:
Kami berdebat apakah harus mempertahankannya. Dari segi kinerja, 3NF lebih lambat untuk penggabungan. Jadi kami mendekati denormalisasi sedikit—menambahkan nilai_saat_ini ke Pendaftaran—dan mendokumentasikan pertukaran tersebut dalam Laporan Akhir.
✅ Kiat: Jangan menerima 3NF secara buta. Gunakan untuk memahami pertukaran yang terjadi.
Langkah 6: Tempat Bermain (Validasi & Pengujian)
Tindakan Kami:
Kami meluncurkan instance PostgreSQL di browser. Menggunakan AI untuk menghasilkan 500 siswa, 100 kursus, dan 2.000 pendaftaran.
Pendapat Kami:
Kami melakukan uji coba beban: 100 pendaftaran bersamaan. Skema tetap bertahan. Kami juga menguji:
-
Bisakah seorang siswa mendaftar di kursus yang sama dua kali?
-
Bisakah seorang instruktur mengajar dua kursus sekaligus?
Kendala-kendala mencegah data yang tidak valid. Kami menemukan bug dalam logika kami sebelum menulis kode backend.
✅ Kiat: Hasilkan ratusan catatan. Kinerja kueri baru terungkap saat berada dalam skala besar.
Langkah 7: Laporan Akhir (Dokumentasi)
Tindakan Kami:
AI menghasilkan laporan Markdown dengan:
-
Pernyataan masalah
-
Diagram (PNG + PlantUML)
-
Skema akhir
-
Contoh
INSERTpernyataan
Kami menambahkan bagian Keputusan Desain bagian:
“Kami melakukan denormalisasi
current_gradeuntuk menghindari JOIN dalam kueri pendaftaran waktu nyata. Ini meningkatkan kinerja dengan biaya kompleksitas tulis yang sedikit meningkat.”
Pendapat Kami:
Laporan ini menjadi dokumen onboarding kami dokumen onboarding. Developer baru membacanya dan memahami skema dalam 15 menit.
✅ Kiat: Gunakan Laporan Akhir sebagai benda serah terima ke DevOps dan QA.
Pedoman & Praktik Terbaik: Apa yang Kami Pelajari dengan Susah Payah
| Praktik | Pelajaran Kami |
|---|---|
| Mulai kecil | Kami mencoba memodelkan seluruh sistem universitas sekaligus. Gagal. Sekarang kami membaginya menjadi modul: Pengguna, Kursus, Pendaftaran. |
| Kontrol versi PlantUML | Kami menyetujui file PlantUML ke Git. Perbedaan menunjukkan evolusi skema. Kemenangan besar untuk audit. |
| Uji dengan ratusan catatan | 10 catatan uji menyembunyikan masalah kinerja. 500+ mengungkapkan JOIN yang lambat. |
| Dokumentasikan asumsi | “Tidak ada penghapusan lunak” → kemudian menyebabkan bug. Sekarang kami mendokumentasikan setiap asumsi. |
| Terintegrasi dengan CI/CD | Kami menambahkan skrip validate-schema.sh skrip yang dijalankan pglint pada DDL yang diekspor. |
Kiat & Trik untuk Pengguna Lanjutan (Pintasan Terbukti Tim Kami)
🔹 Insinyur Prompt = Perubahan Besar
Alih-alih:
“Bangun sistem blog”
Kini kita gunakan:
*”Rancang skema PostgreSQL untuk platform blog multi-tenant di mana:
Setiap tenant memiliki pos dan komentar yang terpisah
Pos mendukung tag dan penerbitan yang dijadwalkan
Komentar dapat bersarang hingga 3 tingkat
Semua tabel mencakup
created_atdanupdated_at“*
Hasil: AI menghasilkan skema yang menyadari tenant dengan isolasi yang tepat—sesuatu yang akan kita lewatkan secara manual.
🔹 Gunakan Komentar PlantUML untuk Sinkronisasi Tim
Kini kita memberi keterangan setiap keputusan utama di PlantUML. Contoh:
' @tim: Tinjau hubungan ini—apakah kita harus menambahkan flag `soft_deleted`?
' @arsitek: Disetujui untuk v1.2. Akan ditambahkan di sprint berikutnya.
User "1" -- "0..*" Post : menulis
🔹 Ekspor Awal, Ekspor Sering
Kami mengekspor DDL dan Markdown setelah setiap iterasi utama. Kami memiliki schema/versi/folder dengan v1.0.sql, v1.1.sql, dll. Sempurna untuk rollback.
🔹 Pasangkan dengan Visual Paradigm Desktop
Untuk proyek-proyek kompleks, kami mengekspor PlantUML ke Desktop, melakukan reverse-engineering basis data yang sudah ada, dan menghasilkan SQL untuk MySQL atau SQL Server.
🔹 Ajarkan dengan Langkah-Langkah Normalisasi
Kami menjalankan ‘Permainan Perang Skema’ di mana junior memprediksi langkah normalisasi berikutnya. Penjelasan AI selalu menang setiap kali.
Catatan Akses, Lisensi & Integrasi (Pengaturan Tim Kami)
| Aspek | Pengaturan Kami |
|---|---|
| Platform | Berdasarkan web melalui Visual Paradigm AI Toolbox |
| Lisensi | Visual Paradigm Online Combo (diperlukan untuk fitur AI) |
| Dialek SQL | PostgreSQL (utama); edisi Desktop untuk MySQL/SQL Server |
| Format Ekspor | DDL, Markdown, PDF, JSON, PlantUML |
| Kolaborasi Tim | Git + Markdown + tautan Playground bersama |
| Penggunaan Offline | Tidak diperlukan—versi web cepat dan andal |
💡 Catatan Pro: Kami sedang meningkatkan ke Server Kolaborasi untuk pengelolaan versi model terpusat dan kontrol akses. Sempurna untuk tim perusahaan.
Kesimpulan: Masa Depan Desain Basis Data Adalah Kolaboratif, Didukung AI, dan Berpusat pada Manusia
Setelah dua bulan penggunaan di dunia nyata, DBModeler AI telah menjadi bagian inti dari alur kerja pengembangan kami.
Ini bukan hanya lebih cepat—ini lebih cerdas. Ini mendorong kami untuk berpikir kritis tentang normalisasi, batasan, dan kasus-kasus ekstrem. Ini mendemokratisasi desain basis data di berbagai peran. Dan ini mengurangi risiko refaktor skema yang mahal dengan menangkap masalah sebelum mencapai produksi.
Wawasan paling berharga? AI tidak menggantikan keahlian—ia meningkatkannya. Kami tidak menulis kode yang lebih sedikit. Kami menulis kode yang lebih baik, lebih cepat, dengan kepercayaan diri yang lebih tinggi.
Jika Anda lelah dengan skema yang berantakan, tidak terdokumentasi, atau rusak—jika Anda ingin merancang basis data seperti ahli, tanpa kurva pembelajaran yang curam—maka DBModeler AI bukan hanya alat. Ini adalah perubahan besar.
Siap Mengubah Alur Kerja Basis Data Anda?
👉 Mulai dengan DBModeler AI
Tanpa instalasi. Tanpa pengaturan. Cukup ketik ide Anda dan bangun skema siap produksi dalam hitungan menit.
Referensi
- DB Modeler AI | Alat Desain Basis Data Berbasis AI oleh Visual Paradigm: Halaman fitur resmi yang menjelaskan kemampuan, kasus penggunaan, dan opsi integrasi untuk DBModeler AI.
- Menguasai DBModeler AI oleh Visual Paradigm: Tutorial mendalam dan panduan alur kerja oleh ahli komunitas, mencakup strategi implementasi praktis.
- Halaman Alat DBModeler AI: Halaman beranda alat interaktif dengan pertanyaan umum, sorotan fitur, dan akses langsung ke generator AI.
- Catatan Rilis DBModeler AI: Log pembaruan resmi, pengumuman fitur baru, dan riwayat versi dari Visual Paradigm.
- Ikhtisar Pembuat Basis Data DBModeler AI: Ringkasan singkat tentang proposisi nilai alat ini dan alur kerja 7 langkah.
- Sistem Manajemen Rumah Sakit dengan DBModeler AI: Studi kasus dunia nyata yang menunjukkan desain basis data dari awal hingga akhir untuk domain kesehatan.
- Kotak Alat AI Visual Paradigm – Aplikasi DBModeler AI: Titik masuk langsung untuk menjalankan aplikasi DBModeler AI berbasis web.
- Panduan Video DBModeler AI: Tutorial video resmi yang menunjukkan antarmuka, alur kerja, dan fitur utama dalam aksi.
- Rilis Analyzer Diagram Kasus Penggunaan AI Gratis: Konteks mengenai ekosistem kotak alat AI yang lebih luas dari Visual Paradigm dan petunjuk akses untuk pengguna Online.
- Tutorial Integrasi Desktop: Panduan video tentang menghubungkan output DBModeler AI dengan Visual Paradigm Desktop untuk alur kerja ekspor lanjutan dan reverse-engineering.
✅ Pikiran Terakhir:
Basis data terbaik tidak dibangun secara terpisah. Mereka adalah dibuat bersama—oleh produk, rekayasa, dan kecerdasan buatan.
Dengan DBModeler AI, kolaborasi ini akhirnya menjadi mulus.
Mulailah membangun fondasi data yang lebih baik—hari ini.
This post is also available in Deutsch, English, Español, فارسی, Français, English, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 and 繁體中文.