













Le développement logiciel repose fortement sur une communication claire entre les parties prenantes, les analystes métiers et les équipes d’ingénierie. La norme Business Process Model and Notation (BPMN) sert de langue universelle pour décrire les flux de travail. Toutefois, même lorsque les équipes adoptent le BPMN, des erreurs dans la modélisation entraînent souvent des frictions importantes lors de la phase de mise en œuvre. Ces erreurs ne sont pas seulement esthétiques ; elles créent une ambiguïté qui se propage à travers l’architecture, les tests et le déploiement.
Ce guide examine cinq erreurs spécifiques de modélisation qui perturbent fréquemment les délais des projets. En comprenant les implications techniques de ces pièges, les équipes peuvent s’assurer que leurs diagrammes de processus reflètent fidèlement le comportement souhaité du système, sans avoir à effectuer de reprises constantes.
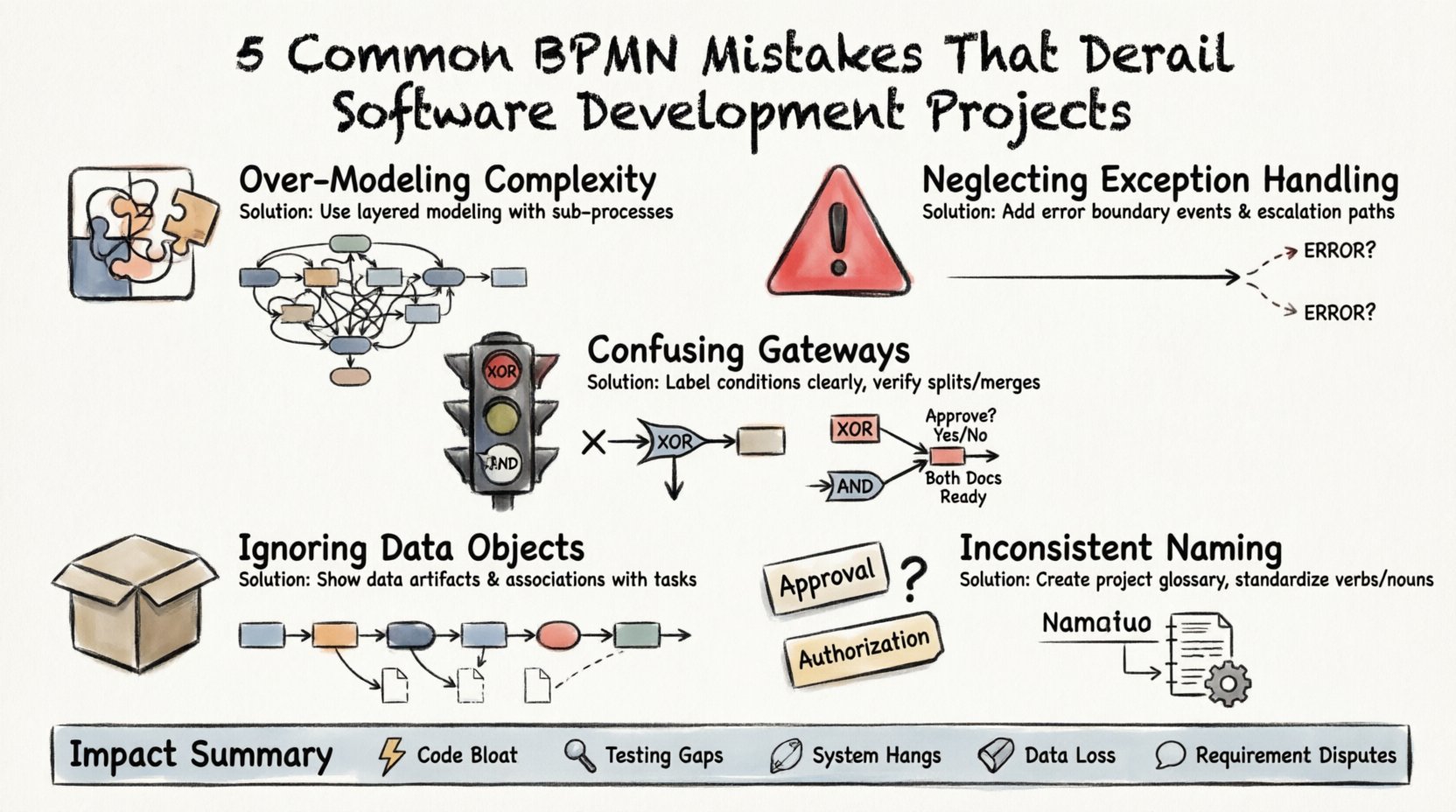
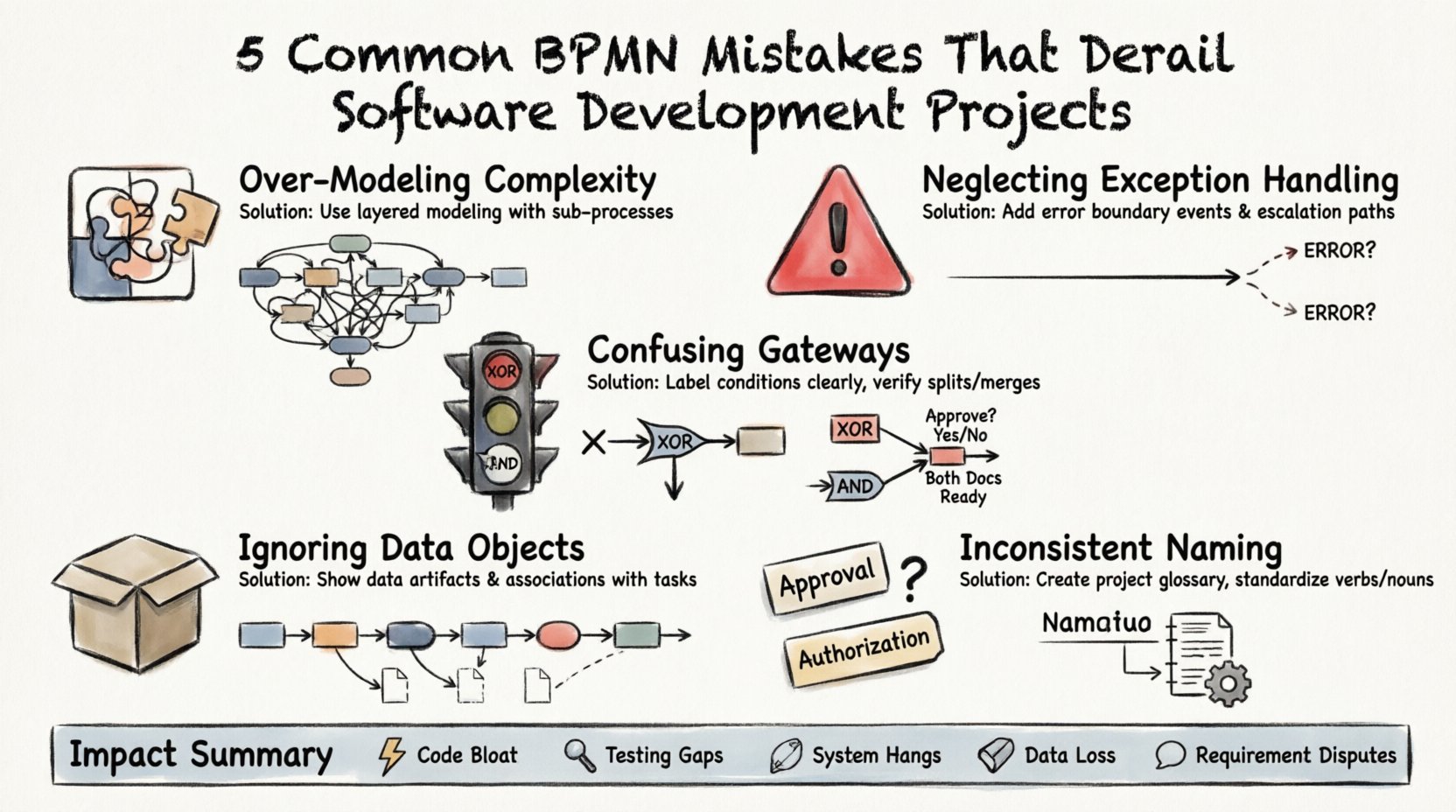
1. Sur-modélisation de la complexité par un détail excessif 🧩
L’un des problèmes les plus fréquents dans la modélisation BPMN est l’effort pour capturer chaque micro-interaction au sein d’un diagramme de processus. Bien que la rigueur soit une vertu, une granularité excessive obscurcit souvent le véritable déroulement logique. Lorsqu’un diagramme devient trop dense, il perd sa valeur comme outil de communication.
L’impact technique
- Bloat de code :Les développeurs qui tentent de mapper un diagramme hyper-détaillé peuvent implémenter des logiques pour des cas limites qui n’étaient jamais destinés à être automatisés. Cela entraîne des branches de code inutiles.
- Surcharge de performance :Des arbres de décision complexes modélisés comme des passerelles peuvent entraîner des flux d’exécution inefficaces au sein du moteur d’exécution.
- Charge de maintenance :Modifier une étape mineure dans un modèle très détaillé exige la mise à jour de nombreuses connexions, ce qui augmente le risque de perturber d’autres parties du processus.
Approche correctrice
Adoptez une stratégie de modélisation par couches. Le diagramme de niveau supérieur doit montrer la séquence générale des événements. La logique détaillée doit être encapsulée dans des sous-processus. Cela maintient la vue principale claire tout en permettant aux développeurs d’approfondir les exigences spécifiques uniquement lorsque nécessaire.
- Vue de haut niveau :Concentrez-vous sur les jalons majeurs et les transferts entre départements.
- Vue des sous-processus :Utilisez des sous-processus étendus pour la logique complexe qui nécessite une analyse plus poussée.
- Centré sur les événements :Assurez-vous que le modèle réagit à des événements spécifiques plutôt que de lister chaque action interne du système.
2. Omission des chemins de gestion des exceptions ⛔
Beaucoup de modèles se concentrent exclusivement sur le « chemin heureux » — la séquence d’étapes où tout se déroule comme prévu. En réalité, les systèmes logiciels doivent gérer les échecs, les délais d’attente et les entrées non valides. Omettre ces scénarios lors de la phase de modélisation crée un faux sentiment de sécurité quant à la robustesse du système.
Pourquoi cela sabote les projets
Lorsque les développeurs rencontrent un modèle qui ne prévoit pas de chemins d’exception, ils doivent deviner comment gérer les erreurs. Cela entraîne :
- Gestion des erreurs codée en dur :Les ingénieurs implémentent des blocs try-catch génériques au lieu de flux de récupération structurés définis par les règles métiers.
- Interventions manuelles :Les utilisateurs peuvent constater que le système s’arrête inopinément, nécessitant des corrections manuelles de la base de données ou des interventions administratives.
- Fentes dans les tests :Les équipes de QA manquent de cas de test spécifiques pour les scénarios d’échec, car le modèle ne les a pas définis.
Mise en œuvre de flux d’erreurs robustes
Chaque étape critique dans un processus doit avoir un résultat défini tant pour le succès que pour l’échec. Utilisez des événements d’erreur intermédiaires pour capturer des modes d’échec spécifiques. Assurez-vous que chaque processus dispose d’un point de terminaison clair, qu’il se termine avec succès ou via une frontière d’erreur.
- Événements de frontière :Attachez des événements de frontière d’erreur aux tâches pour capturer les exceptions localement.
- Compensation : Définissez ce qui se produit si une transaction doit être annulée. Qui est informé ?
- Escalade : Précisez les seuils pour escalader les problèmes vers des opérateurs humains lorsque les tentatives automatiques de réessai échouent.
3. Confondre les passerelles exclusives et parallèles 🚦
Les passerelles déterminent la manière dont un processus se divise ou se fusionne. Distinger entre une passerelle exclusive (XOR) et une passerelle parallèle (AND) est fondamental. L’utilisation incorrecte de ces éléments modifie la logique de l’ensemble du flux de travail. Une passerelle XOR implique un choix où une seule voie est suivie. Une passerelle AND implique que toutes les voies doivent être complétées.
Le piège logique
Utiliser une passerelle AND là où une passerelle XOR est requise peut entraîner l’exécution de tâches en double ou un blocage indéfini en attendant une branche qui ne sera jamais complétée. À l’inverse, utiliser une passerelle XOR là où une passerelle AND est nécessaire peut entraîner une perte de données si plusieurs branches doivent s’exécuter simultanément.
Scénarios courants de confusion
| Type de passerelle | Fonction | Utilisation courante incorrecte |
|---|---|---|
| Exclusif (XOR) | Une seule voie parmi plusieurs | Utilisé lorsque plusieurs sous-tâches doivent s’exécuter simultanément |
| Parallèle (AND) | Toutes les voies doivent être complétées | Utilisé lorsque seulement une branche conditionnelle est valide |
| Inclusif (OU) | Une ou plusieurs voies | Souvent confondu avec l’exclusif en ce qui concerne les dépendances de données |
Assurer la cohérence logique
Avant de finaliser le diagramme, examinez chaque passerelle pour vous assurer que les conditions correspondent à l’intention d’exécution. Si une tâche nécessite qu’une condition spécifique soit remplie avant de continuer, utilisez une passerelle exclusive avec des étiquettes claires. Si une tâche déclenche des actions indépendantes qui s’exécutent en parallèle, utilisez une passerelle parallèle.
- Étiqueter les conditions : Ne laissez jamais les conditions des passerelles vides. Indiquez explicitement la logique booléenne.
- Vérifier les fusions : Assurez-vous qu’il existe une fusion correspondante pour chaque séparation. Les chemins orphelins indiquent une modélisation incomplète.
- Logique de test : Parcourez le diagramme comme si vous étiez le moteur l’exécutant. Le flux correspond-il aux exigences ?
4. Ignorer les objets de données et le flux d’information 📦
Un modèle de processus ne concerne pas seulement les actions ; il concerne la transformation des données. De nombreux diagrammes se concentrent entièrement sur le flux de contrôle (la séquence des activités) tout en négligeant le flux de données (les objets créés, lus ou mis à jour). Sans ce contexte, les développeurs ne peuvent pas concevoir le schéma de base de données ou les contrats d’API appropriés.
Le fossé du développement
Lorsque le flux de données est omis, l’équipe de développement doit déduire les structures de données à partir des noms des activités. Cela entraîne :
- Requêtes inefficaces :Les développeurs peuvent récupérer des données inutilement, car le modèle n’a pas indiqué où les données sont consommées.
- Problèmes d’intégrité des données :Si le modèle ne montre pas où les données sont validées, cette validation pourrait être oubliée dans le code.
- Mauvaises correspondances d’interfaces :Le frontend peut attendre des champs que le processus backend ne génère pas.
Intégrer les données dans le modèle
Utilisez des objets de données pour représenter les artefacts d’information utilisés ou produits par les tâches. Utilisez des associations de données pour montrer comment l’information circule entre les tâches, les passerelles et les artefacts.
- Définir les artefacts :Marquez clairement les documents d’entrée et les rapports de sortie.
- Montrer les transitions :Tracez des lignes reliant les objets de données aux tâches qui les modifient.
- Préciser les types :Indiquez si un objet de données est une variable temporaire ou un enregistrement persistant.
5. Conventions de nommage incohérentes 📝
La clarté est la monnaie de la modélisation. Si le diagramme utilise « Approbation » dans une section et « Autorisation » dans une autre pour le même concept, la confusion est inévitable. Une terminologie incohérente rend difficile la confiance du modèle par les parties prenantes et la traduction du modèle en code par les développeurs.
Le coût de l’ambiguïté
Lorsque les termes sont utilisés de manière interchangeable, les sessions de collecte de besoins deviennent des débats sur les définitions plutôt que sur la fonctionnalité. Cela freine l’avancement et augmente la probabilité de dérive de périmètre, au fur et à mesure que les équipes tentent de couvrir toutes les interprétations possibles.
Établir un glossaire
Créez un glossaire partagé pour le projet. Ce document définit exactement ce que signifie chaque terme dans le contexte du système. Assurez-vous que le modèle BPMN s’aligne strictement sur ce glossaire.
- Standardiser les verbes :Utilisez des étiquettes orientées action pour les tâches (par exemple, « Traiter la commande » au lieu de « Commande »).
- Standardiser les noms : Assurez-vous que les objets de données utilisent une nomenclature cohérente (par exemple, « Client » vs « Client »).
- Revoyez les étiquettes : Avant de publier un modèle, effectuez une recherche de texte pour trouver des synonymes afin d’assurer la cohérence.
Analyse des impacts des erreurs de modélisation
Comprendre les erreurs théoriques est une chose ; comprendre le coût tangible de ces erreurs en est une autre. Le tableau ci-dessous résume comment des erreurs spécifiques de modélisation se traduisent par des risques pour le projet.
| Erreur de modélisation | Phase affectée | Conséquence potentielle |
|---|---|---|
| Sur-modélisation | Développement | Augmentation de la dette technique et ralentissement des cycles de déploiement |
| Pas de chemins d’exception | Tests et QA | Haut volume d’incidents en production et de réclamations des utilisateurs |
| Confusion sur les passerelles | Architecture | Bloquages du système ou boucles infinies dans le moteur d’exécution |
| Flux de données manquant | Conception de la base de données | Schémas incomplets et perte de données lors des transactions |
| Nomenclature incohérente | Revue par les parties prenantes | Litiges sur les exigences et retard dans l’approbation |
Mise en œuvre stratégique du BPMN
Pour atténuer ces risques, les organisations doivent considérer le BPMN non pas comme une simple activité de documentation, mais comme une spécification de conception. Le modèle doit être traité avec le même rigueur que le code source. Le contrôle de version, les revues par les pairs et la validation par rapport aux règles métier sont essentiels.
Meilleures pratiques pour la validation
- Parcours : Effectuez des parcours formels avec les utilisateurs métiers et les développeurs. Les utilisateurs métiers vérifient la logique ; les développeurs vérifient la faisabilité.
- Modélisation exécutable : Lorsque c’est possible, utilisez des modèles exécutables. Si le moteur de processus peut exécuter le diagramme, cela prouve que la logique est correcte avant qu’une seule ligne de code personnalisé ne soit écrite.
- Traçabilité :Liez les éléments BPMN directement aux historiques d’utilisateurs ou aux documents de spécifications. Cela garantit que chaque étape du diagramme dispose d’une justification métier.
Assurer la maintenabilité à long terme
Les projets logiciels évoluent. Les processus changent. Un modèle qui fonctionne aujourd’hui peut devenir obsolète en six mois. Pour éviter l’accumulation de la dette technique, les normes de modélisation doivent être durables.
- Gardez-le simple :Un diagramme facile à comprendre est plus facile à modifier.
- Modularisez :Divisez les grands processus en sous-processus plus petits et réutilisables.
- Documentez les hypothèses :Si une décision a été prise sur la base d’une contrainte spécifique, documentez-la à côté de la tâche concernée.
- Audits réguliers :Revoyez périodiquement les modèles par rapport à l’état actuel du système pour vous assurer qu’ils n’ont pas dérivé de la réalité.
Conclusion
Adopter le modèle et la notation des processus métiers est un avantage stratégique, mais uniquement lorsqu’il est correctement mis en œuvre. Les cinq erreurs décrites ici — surcomplexité, exceptions manquantes, confusion autour des passerelles, négligence des données et incohérence dans la nomenclature — sont des pièges courants qui peuvent freiner les efforts de développement. En traitant ces aspects avec rigueur et clarté, les équipes peuvent construire un logiciel qui correspond précisément aux besoins métiers.
L’objectif n’est pas seulement de dessiner des diagrammes, mais de créer un plan directeur que les développeurs peuvent faire confiance. Lorsque le modèle est précis, le logiciel résultant est robuste, maintenable et adapté à son usage. Privilégiez la précision plutôt que la vitesse lors de la phase de modélisation afin d’économiser un temps et des ressources considérables lors de la mise en œuvre.
Cette publication est également disponible en Deutsch, English, Español, فارسی, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 : liste des langues séparées par une virgule, 繁體中文 : dernière langue.