













资深全栈工程师撰写 | 第三方真实体验报告,包含实用洞察与团队影响
引言:为何这款工具改变了我们的数据库设计方式
作为一名快速发展的SaaS初创公司的资深全栈开发工程师,我见证了我们的数据库设计流程经历重重考验。从白板上匆忙绘制的草图,到临门一脚的模式重构导致生产环境崩溃,数据库常常是我们的交付流程中的 最薄弱环节交付流程中的薄弱环节。
我们尝试过各种方法:ERD工具、绘图插件,甚至为模式定义自定义DSL。但它们都无法真正弥合 业务意图与 生产就绪的SQL之间的鸿沟——尤其是在引入初级工程师或与非技术产品经理协作时。
直到 DBModeler AI由Visual Paradigm推出的。
在与团队试用两周后,我可以毫不夸张地说: 这是我十年来使用过的最具变革性的数据库设计工具。
这不仅仅是一款普通的AI驱动的图表生成工具。它是一个 协作式设计引擎能够将自然语言转化为完全规范化、可测试且有文档记录的数据库模式——全部在浏览器中完成,无需任何配置。

在这份指南中,我将带您了解我们使用DBModeler AI在三大核心功能上的真实体验:用户认证、课程注册和订单管理。我将分享哪些方法有效、哪些无效,以及我们如何将其融入敏捷工作流程——包含截图、团队反馈和可立即应用的实用建议。
开发团队的关键概念 (结合真实场景重新审视)
🎯 AI作为协作设计师,而非替代者
我们的体验:
我们最初担心AI会“覆盖”我们精心设计的模型。但在测试后,我们意识到AI并不会 取代判断力——它反而 放大了判断力.
例如,当我们描述“一个学生可以注册多门课程”时,AI 正确地推断出多对多关系,并建议创建一个关联表。但我们可以 直接编辑 PlantUML 代码 来添加软删除标志和审计时间戳——这是 AI 没有自动生成的,但我们需要它来满足合规要求。
✅ 结论: AI 是一名副驾驶,而不是替代品。你始终掌握控制权。
🔁 设计中的迭代优化
我们的经验:
在开发课程注册功能时,我们从一个简单的模型开始: 学生 → 课程。在 AI 生成实体关系图后,我们意识到需要追踪 注册状态 (已注册、已退课、已失败)。我们回到第二步,编辑了 PlantUML 中的 注册 类,并在不到 30 秒内重新生成了数据模型。
✅ 结论: 这种循环工作流并非理论上的设想——它是切实可行的。我们现在将数据模型设计视为一个冲刺周期,而非一次性任务。
🧪 部署前先测试——沙盒环境彻底改变了我们的工作方式
我们的经验:
我们过去是在数据模型部署后才编写集成测试。现在,我们 在编写任何代码之前就验证行为 验证行为,而无需编写任何代码.
在沙盒环境中,我们生成了 500 名示例学生并将其注册到课程中。我们运行了如下复杂查询:
SELECT s.name, COUNT(e.id) AS course_count
FROM students s
JOIN enrollments e ON s.id = e.student_id
WHERE e.status = 'active'
GROUP BY s.name
ORDER BY course_count DESC;
该查询立即返回结果——无需启动本地数据库。我们甚至测试了边界情况:如果一个学生退掉所有课程会发生什么?AI 的约束逻辑防止了孤立记录的产生,我们还提前发现了潜在的竞态条件。
✅ 结论:游乐场消除了我们部署后80%的模式错误。
📐 规范化作为一级功能
我们的经验:
我们的初级开发人员困惑于为什么AI将它拆分课程为课程和课程讲师。但在走完1NF → 2NF → 3NF的步骤后,他们理解了其中的逻辑——尤其是当AI展示了如何消除重复组时。
我们现在将这一步作为培训模块用于新员工。这就像一本关于数据库理论的活教材。
✅ 结论:规范化不再只是一个复选框——它是一个可教学、可见的过程。
🌐 浏览器原生,无需安装开销
我们的经验:
我们团队中的一位成员使用的是公司锁定的笔记本电脑,没有管理员权限。他们无法安装Docker或PostgreSQL。但他们通过网页应用加入了项目,创建了模式,并在不到10分钟内参与了设计。
✅ 结论:这是我用过的最具包容性的数据库工具。入职现在毫无障碍。
七步AI工作流:开发者的深入探讨——我们团队的旅程
步骤1:问题输入(概念性输入)
我们的提示:
“构建一个用于管理大学课程、学生和选课的系统。学生可以选修多门课程。每门课程有一位授课教师。选课记录需包含成绩、时间戳和状态(已注册、退课、失败)。所有数据表必须包含
created_at和updated_at.”
我们的看法:
AI的描述生成器帮助我们优化了输入内容。我们补充了最初被忽略的约束条件和业务规则。
✅ 提示: 使用项目符号。AI对项目符号的解析效果优于长段落。
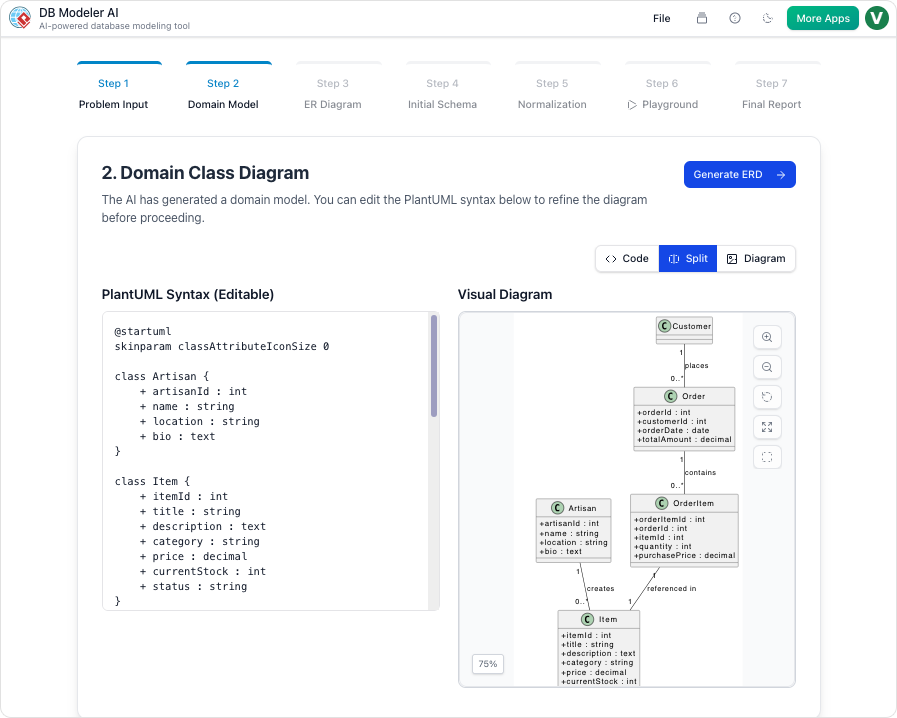
步骤2:领域模型(概念建模)
我们的操作:
AI生成了一个基于PlantUML的领域模型。我们将 Student 改为 User,增加了 email, role,以及 is_active 属性,并明确了 Enrollment 类。
我们的看法:
可视化渲染即时且清晰。我们将在Slack中分享PlantUML代码,前端团队已经可以查看结构了。
✅ 提示:使用
@note在PlantUML中的注释来记录假设。
@note right
如果我们添加软删除功能,此关系可能需要一个连接表
@end note
步骤3:ER图(逻辑建模)
我们的操作:
AI自动生成了主键、外键和基数。我们注意到 课程和讲师——但我们希望每门课程只有一位讲师,因此我们将其调整为1:1.
我们的看法:
我们与团队再次确认了基数。此处的任何错误都可能导致数据异常。
✅ 提示:在最终确定前,务必与产品负责人验证关系。
步骤4:初始模式(物理代码生成)
我们的操作:
使用 created_at, updated_at,以及 CHECK约束。
我们的看法:
我们将其作为Flyway迁移的基准不再需要手动编写DDL——只需版本控制的脚本。
✅ 提示:尽早导出DDL。我们会在Git中保留一个
schema/initial文件夹。
步骤5:规范化(模式优化)
我们的行动:
我们依次经历了1NF → 2NF → 3NF。在2NF阶段,AI将Enrollment拆分为Enrollment和EnrollmentHistory以消除部分依赖。
我们的看法:
我们曾争论是否保留它。从性能角度看,3NF在连接操作上更慢。因此我们适度进行了反规范化——适度进行了反规范化——向current_grade添加了Enrollment——并在最终报告中记录了这一权衡。
✅ 提示:不要盲目接受3NF。应利用它来理解权衡取舍。
步骤6:游乐场(验证与测试)
我们的行动:
我们启动了浏览器中的PostgreSQL实例。使用AI生成了500名学生、100门课程和2,000次注册记录。
我们的看法:
我们进行了压力测试:100个并发注册。数据结构保持稳定。我们还进行了以下测试:
-
学生能否重复注册同一门课程?
-
一名讲师能否同时教授两门课程?
约束条件阻止了无效数据的输入。我们在编写后端代码之前发现了逻辑中的一个错误。在编写后端代码之前。
✅ 提示:生成数百条记录。查询性能只有在大规模下才会显现。
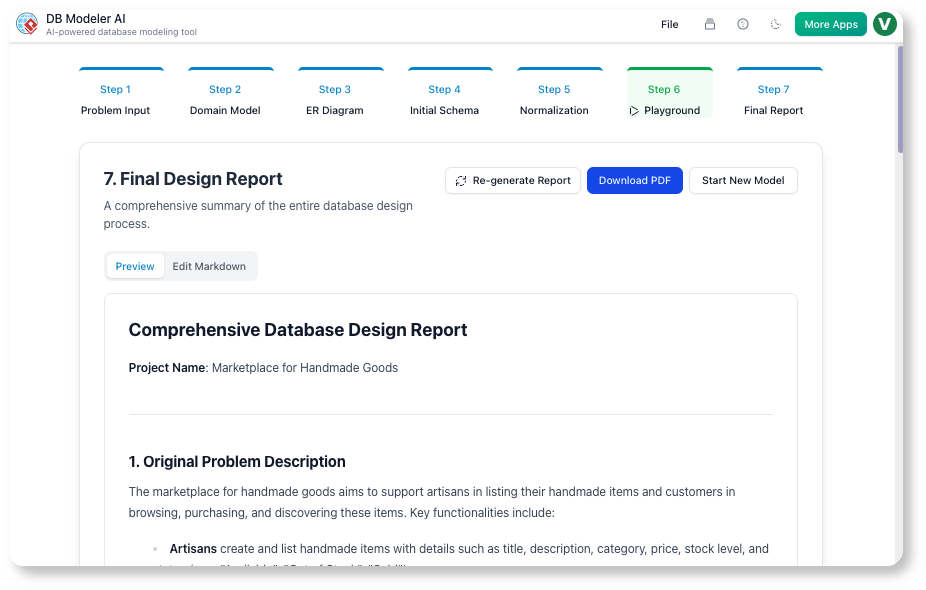
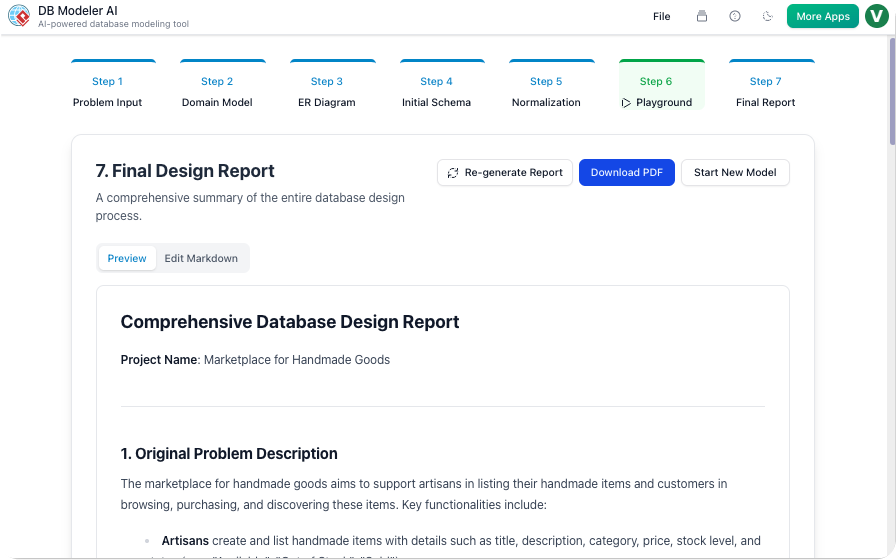
步骤7:最终报告(文档)
我们的行动:
AI生成了一份Markdown报告,内容包括:
-
问题陈述
-
图表(PNG + PlantUML)
-
最终数据结构
-
示例
INSERT语句
我们添加了 设计决策 部分:
“我们将
current_grade去规范化,以避免在实时注册查询中使用JOIN。这提升了性能,但带来了稍高的写入复杂度。”
我们的看法:
这份报告成为了我们的 入职文档。新开发人员阅读后,15分钟内就理解了数据结构。
✅ 提示: 使用最终报告作为 交接文档 提供给运维和质量保证团队。
指南与最佳实践:我们吃尽苦头才学到的经验
| 实践 | 我们的教训 |
|---|---|
| 从小处着手 | 我们试图一次性建模整个大学系统。失败了。现在我们将其拆分为模块: 用户, 课程, 注册. |
| 使用版本控制管理PlantUML | 我们将PlantUML文件提交到Git。差异对比清晰展示了数据结构的演进过程。这对审计工作是巨大优势。 |
| 使用数百条记录进行测试 | 仅10条测试记录会掩盖性能问题。超过500条记录才暴露出缓慢的JOIN操作。 |
| 记录假设条件 | “不使用软删除” → 后来导致了一个bug。现在我们记录下每一个假设条件。 |
| 与CI/CD集成 | 我们添加了一个 validate-schema.sh 脚本,用于运行 pglint在导出的 DDL 上。 |
高级用户的技巧与窍门 (我们团队验证过的快捷方式)
🔹 提示工程 = 改变游戏规则的关键
而不是:
“构建一个博客系统”
我们现在使用:
*”为一个多租户博客平台设计一个 PostgreSQL 模式,要求:
每个租户拥有独立的帖子和评论
帖子支持标签和定时发布
评论最多可嵌套三级
所有表都包含
created_at和updated_at“*
结果: AI 生成了一个 具备租户感知能力且隔离完善的模式——这正是我们手动操作时容易忽略的部分。
🔹 使用 PlantUML 注释进行团队同步
我们现在在 PlantUML 中标注每一个重要决策。示例:
' @team: 审查此关系——我们是否应添加 `soft_deleted` 标志?
' @arch: v1.2 版本已批准。将在下一个冲刺中添加。
User "1" -- "0..*" Post : writes
🔹 尽早导出,频繁导出
在每次主要迭代后,我们都会导出 DDL 和 Markdown。我们有一个 schema/versions/包含文件夹v1.0.sql, v1.1.sql等。非常适合回滚。
🔹 与 Visual Paradigm Desktop 配合使用
对于复杂项目,我们将 PlantUML 导出到桌面版,反向工程现有数据库,并为 MySQL 或 SQL Server 生成 SQL。
🔹 通过规范化步骤进行教学
我们进行一场“模式战争游戏”,初级人员预测下一步的规范化操作。AI 的解释每次都获胜。
访问、许可与集成说明 (我们团队的配置)
| 方面 | 我们的配置 |
|---|---|
| 平台 | 基于网页,通过Visual Paradigm AI 工具箱 |
| 许可 | Visual Paradigm Online 套餐(AI 功能所需) |
| SQL 语法 | PostgreSQL(主要);MySQL/SQL Server 的桌面版 |
| 导出格式 | DDL、Markdown、PDF、JSON、PlantUML |
| 团队协作 | Git + Markdown + 共享的 Playground 链接 |
| 离线使用 | 无需离线使用——网页版快速且可靠 |
💡 专业提示:我们正在升级到协作服务器用于集中化的模型版本控制和访问权限管理。非常适合企业团队。
结论:数据库设计的未来是协作式、AI驱动且以人为本的
经过两个月的实际使用后,DBModeler AI 已成为我们开发工作流程的核心部分.
它不仅更快——而且更智能。它迫使我们深入思考规范化、约束条件和边缘情况。它让不同角色都能参与数据库设计。而且它降低了昂贵的模式重构风险通过在问题进入生产环境前发现它们之前就将其捕获。
最有价值的洞察是什么?AI 并不会取代专业技能,而是提升它。我们并不是编写的代码变少了。我们是在编写更优质的代码,更快,更有信心。
如果你厌倦了混乱、缺乏文档或已损坏的模式——如果你希望像专业人士一样设计数据库,而无需经历陡峭的学习曲线——那么DBModeler AI 不仅仅是一个工具,它是一场变革。
准备好改变你的数据库工作流程了吗?
👉 立即开始使用 DBModeler AI
无需安装,无需配置。只需输入你的想法,几分钟内即可构建出可投入生产的数据库模式。
参考文献
- DB Modeler AI | 由 Visual Paradigm 提供的 AI 驱动数据库设计工具:官方功能页面,详细介绍了 DBModeler AI 的功能、使用场景和集成选项。
- 掌握由 Visual Paradigm 提供的 DBModeler AI: 由社区专家提供的深入教程和工作流程演示,涵盖实用的实施策略。
- DBModeler AI 工具页面: 带有常见问题解答、功能亮点以及直接访问 AI 生成器的交互式工具首页。
- DBModeler AI 发布说明: Visual Paradigm 官方的更新日志、新功能公告及版本历史。
- DBModeler AI 数据库生成器概览: 工具价值主张的简明总结及七步工作流程。
- 使用 DBModeler AI 的医院管理系统: 真实案例研究,展示面向医疗领域的端到端数据库设计。
- Visual Paradigm AI 工具箱 – DBModeler AI 应用: 直接入口,用于启动基于网页的 DBModeler AI 应用程序。
- DBModeler AI 视频导览: 官方视频教程,展示界面、工作流程及关键功能的实际应用。
- 免费 AI 用例图分析器发布: 关于 Visual Paradigm 更广泛 AI 工具箱生态系统的背景信息,以及 Online 用户的访问指南。
- 桌面集成教程: 视频指南,介绍如何将 DBModeler AI 的输出与 Visual Paradigm Desktop 连接,以实现高级导出和逆向工程工作流。
✅ 最后思考:
最好的数据库并非孤立构建。它们是共同创造——由产品、工程与人工智能共同完成。
借助 DBModeler AI,这种协作终于变得无缝顺畅。
立即开始构建更坚实的数据基础——从今天开始。