













设计稳健的事务工作流需要超越标准建模。当系统每秒处理数千次操作时,业务流程模型与符号(BPMN)的细微差别变得至关重要。本指南探讨了专为高吞吐量环境设计的高级模式。我们重点关注结构完整性、并发管理以及性能优化,而不依赖特定厂商工具。
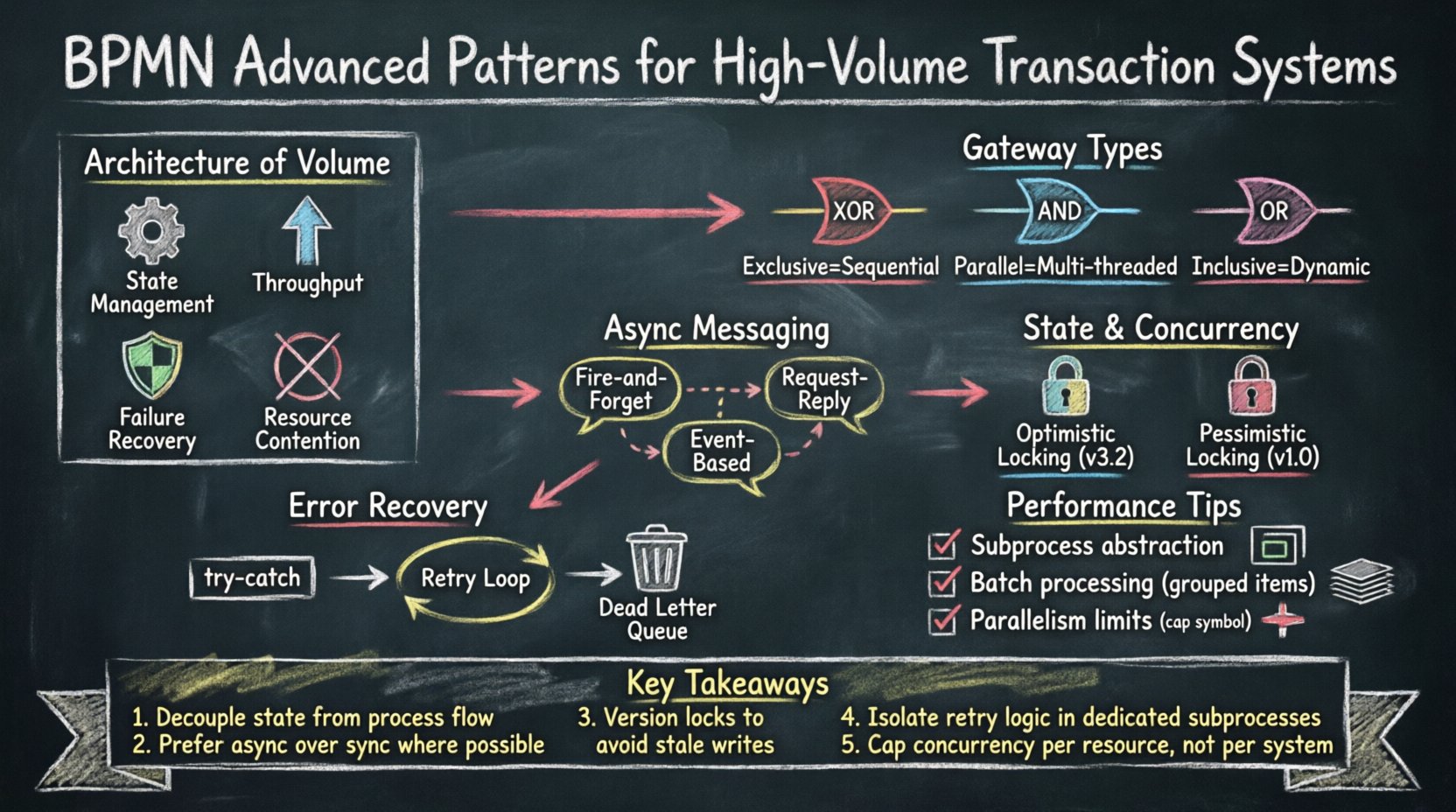
📊 规模的架构
高吞吐量交易系统与标准运营工作流在本质上截然不同。在典型业务流程中,延迟是可以接受的,人工干预也很常见。而在交易引擎中,毫秒级的延迟至关重要,自动化必须绝对可靠。流程模型充当并发控制和资源分配的蓝图。
当扩展到数百万条记录时,多个因素会改变设计的优先级:
- 状态管理:流程中的每一步都必须保持数据完整性。
- 吞吐量:模型必须在逻辑安全的前提下允许并行执行。
- 故障恢复:回滚机制必须明确且可恢复。
- 资源争用:锁定策略会影响可以同时运行的进程数量。
建模这些约束需要从线性思维转向分布式逻辑。标准BPMN元素在负载下表现不同。理解这些行为使架构师能够构建在高峰需求期间仍保持稳定的系统。
🔀 规模化中的网关机制
网关决定了控制流。在高吞吐量系统中,网关的选择会显著影响性能。错误的使用可能导致瓶颈,所有线程都必须等待单一条件,从而抵消并行性。
三种主要的网关类型需要谨慎选择:
- 独占网关:根据数据路由到单一路径。开销低,但决策是顺序进行的。
- 并行网关:同时生成多个路径。吞吐量高,但需要同步。
- 包含网关:根据条件路由到多个路径。需要复杂的状体跟踪。
| 网关类型 | 并发影响 | 最佳使用场景 |
|---|---|---|
| 独占网关 | 低(顺序) | 简单决策逻辑 |
| 并行网关 | 高(多线程) | 独立的验证步骤 |
| 包含网关 | 中等(动态) | 条件性功能标志 |
对于事务性系统,只要下游流程相互独立,通常更倾向于使用并行网关来拆分工作。如果下游流程共享资源(例如数据库记录),模型必须包含同步逻辑。否则将出现竞争条件,导致数据损坏。
📨 异步消息传递模式
阻塞操作会降低吞吐量。如果一个流程在等待外部系统响应,整个事务线程都会被占用。异步消息传递将流程与依赖服务的响应时间解耦。
该模式利用中间消息事件。流程在继续之前不会等待回复,而是发送一个信号并进入等待状态。这使得引擎可以在原始流程等待确认时处理其他事务。
- 发后不管: 发送数据而不期望立即响应。在操作非关键时使用。
- 请求-回复: 发送消息并等待特定的相关ID。在需要数据一致性时使用。
- 基于事件: 监听外部事件以触发下一步。适用于解耦的微服务。
实现此模式需要一个可靠的消息代理。流程模型必须处理消息丢失或延迟的情况。定时器事件通常与消息事件一起使用,以防止无限期等待。如果消息在设定的时间内未到达,流程应触发重试或警报机制。
⚙️ 管理状态与并发
状态管理是事务一致性的核心。在分布式环境中,一个流程实例代表一个特定的工作单元。管理该单元的状态可确保没有两个流程同时损坏同一份数据。
关键考虑因素包括:
- 乐观锁: 允许多个流程读取数据。仅当自读取以来没有其他流程修改过数据时才更新。
- 悲观锁: 访问数据时立即锁定。阻止其他流程读取或写入。
- 版本控制: 为数据对象附加版本号。在提交更改前验证版本。
流程模型应反映这些锁定策略。如果某项任务需要锁定,BPMN图中应显示一个执行锁定操作的任务节点。这使约束对开发人员和审计人员都可见。
长时间运行的流程带来独特的挑战。如果事务持续数小时,引擎必须持久化状态。中间事件和消息中间事件有助于将长时间任务拆分为可管理的片段。这可防止内存耗尽,并允许系统在崩溃后恢复而不会丢失进度。
🛡️ 补偿与错误恢复
在高吞吐量系统中,故障是不可避免的。流程模型必须明确定义如何处理这些故障。标准的错误处理涉及异常。在BPMN中,这涉及错误中间事件和边界事件。
补偿是撤销工作的行为。如果事务在中途失败,系统必须回滚更改以保持数据完整性。这与简单的回滚不同。补偿允许部分撤销。
有效的错误处理模式包括:
- Try-Catch 块: 封装流程的一部分。如果发生错误,则路由到补偿处理程序。
- 重试循环: 在升级之前尝试执行该操作指定次数。
- 死信队列: 将失败的事务移动到单独的队列中以进行人工审查。
| 策略 | 复杂性 | 恢复能力 |
|---|---|---|
| 立即重试 | 低 | 临时网络故障 |
| 指数退避 | 中等 | 系统过载 |
| 补偿处理程序 | 高 | 业务逻辑错误 |
设计补偿处理程序时,确保其具有幂等性。重复运行补偿逻辑不应导致更多错误。这一点至关重要,因为如果系统重启,错误事件本身可能会被多次触发。
📈 通过建模进行性能调优
优化始于设计阶段。一个结构良好的模型可以减少运行时开销。几种建模技术会直接影响性能指标。
子流程抽象
使用子流程有助于管理复杂性。折叠的子流程隐藏内部细节,减少了引擎遍历流程图时的认知负担。然而,展开的子流程允许进行详细调试。对于高吞吐量系统,应将复杂逻辑保留在独立的子流程中。这可以隔离故障,并允许对内部逻辑进行特定调优。
批处理
逐条处理记录效率低下。批处理将事务分组。在BPMN中,这通过循环结构进行建模。流程遍历一个项目集合,在将一组数据提交到数据库之前进行处理。这减少了数据库连接和事务提交的次数。
- 固定批处理大小: 每次提交处理 exactly 100 个项。
- 基于时间的批处理: 处理项目,直到经过5秒钟。
- 基于数量的批次: 处理项目,直到总大小达到阈值。
并行度限制
无限的并行度可能会耗尽系统资源。模型应定义并发限制。这通常由执行引擎处理,但流程设计应尊重这些限制。使用网关阈值来限制并行路径的数量。例如,限制同时运行的验证任务数量,以防止CPU过载。
🔍 监控与优化
系统上线后,监控至关重要。流程模型应包含关键指标的标记。这些标记有助于识别实际执行中的瓶颈。
需要跟踪的关键指标包括:
- 持续时间: 每个任务耗时多久。
- 吞吐量: 每小时完成的实例数量。
- 错误率: 失败实例所占的百分比。
- 队列深度: 等待资源的实例数量。
通过将这些指标与流程图相关联,团队可以准确地定位延迟发生的位置。是数据库写入?还是外部API调用?该模型为这些诊断提供了地图。
🔒 安全与合规
高吞吐量系统通常处理敏感数据。安全控制必须嵌入流程中。身份验证和授权任务应在图中作为明确的节点。
- 访问控制: 确保只有授权用户才能触发特定任务。
- 数据脱敏: 在数据传递给外部服务之前应用脱敏规则。
- 审计日志: 为合规目的记录每一次状态变更。
合规要求通常规定操作的特定顺序。例如,数据加密必须在存储之前进行。BPMN允许将这些约束可视化。这确保了监管要求得以满足,而无需依赖开发人员的记忆。
🔄 持续改进
流程模型并非一成不变。随着业务规则的变化,模型必须随之演进。对流程定义进行版本控制至关重要。这使得系统可以在部署新版本的同时运行旧版本。
- 迁移: 定义在版本1下创建的实例在版本2下的行为。
- A/B测试: 在流量的子集上运行不同的流程版本,以比较性能。
- 反馈回路: 使用生产环境中的数据来优化模型。
定期审查流程模型,确保其与系统能力保持一致。如果发现瓶颈,可以调整模型以更均衡地分配负载。这种迭代方法能够长期保持系统的健康状态。
📋 高级技术概要
在高吞吐量交易系统中实施BPMN需要思维模式的转变。这不仅仅是画方框和箭头。而是关于对并发、状态和故障进行建模。这里讨论的模式为构建弹性系统提供了框架。
主要收获包括:
- 在存在独立性的地方,使用并行网关以最大化吞吐量。
- 使用异步消息事件解耦外部依赖。
- 为复杂的错误恢复实现补偿处理程序。
- 批量操作以减少数据库开销。
- 根据模型监控指标,以识别瓶颈。
通过遵循这些模式,架构师可以创建可扩展的流程模型。该模型成为执行引擎的可靠规范,确保高吞吐量交易能够以精确性和稳定性处理。