













Von einem Senior Full-Stack Engineer | Bericht einer Drittpartei mit praktischen Erkenntnissen und Einfluss auf das Team
Einführung: Warum dieses Werkzeug unsere Datenbankgestaltung verändert hat
Als Senior Full-Stack-Entwickler bei einem dynamischen SaaS-Startup habe ich unseren Datenbankentwurfsprozess durchgemacht. Von hastigen Skizzen an Whiteboards bis hin zu letzter Minute durchgeführten Schema-Refaktorisierungen, die die Produktion störten, war die Datenbank oft die schwächste Stelle in unserer Lieferkette.
Wir haben alles ausprobiert: ERD-Tools, Diagrammier-Plugins, sogar benutzerdefinierte DSLs zur Schema-Definition. Doch keines davon hat wirklich die Kluft zwischen geschäftlicher Absicht und produktionsfertigem SQL—insbesondere bei der Einarbeitung junger Entwickler oder der Zusammenarbeit mit nicht-technischen Produktmanagern.
Dann kam DBModeler AI von Visual Paradigm.
Nach einer zweiwöchigen Testphase mit meinem Team kann ich ohne Übertreibung sagen: dies ist das bahnbrechendste Werkzeug für die Datenbankgestaltung, das ich in über einem Jahrzehnt genutzt habe.
Dies ist kein weiteres AI-gesteuertes Diagramm-Generierungswerkzeug. Es ist ein kollaborativer Gestaltungsmotor der natürliche Sprache in eine vollständig normalisierte, testbare und dokumentierte Datenbankschema umwandelt – alles im Browser, ohne jegliche Einrichtung.

In diesem Leitfaden führe ich Sie durch unsere praktische Erfahrung mit DBModeler AI bei drei zentralen Funktionen: Benutzer-Authentifizierung, Kursanmeldung und Bestellverwaltung. Ich teile, was funktioniert hat, was nicht, und wie wir es in unseren agilen Arbeitsablauf integriert haben – inklusive Screenshots, Teamfeedback und praktikablen Tipps, die Sie sofort umsetzen können.
Wichtige Konzepte für Entwicklungsteams (Neu betrachtet im Kontext der Praxis)
🎯 KI als kollaborativen Gestalter, nicht als Ersatz
Unsere Erfahrung:
Anfangs fürchteten wir, die KI würde unsere sorgfältig gestalteten Modelle „überschreiben“. Doch nach dem Testen erkannten wir, dass die KI nicht ersetzen Urteilsvermögen ersetzt – sie es verstärkt.
Zum Beispiel, als wir beschrieben haben, dass ein „Student an mehreren Kursen teilnehmen kann“, erkannte die KI korrekterweise eine Many-to-Many-Beziehung und schlug eine Verbindungstabelle vor. Aber wir konnten den PlantUML-Code direkt bearbeiten weitere Soft-Delete-Flags und Audit-Timestamps hinzuzufügen – etwas, das die KI nicht automatisch generiert hat, aber das wir für die Einhaltung von Vorgaben benötigten.
✅ Urteil: Die KI ist ein Co-Pilot, kein Ersatz. Sie ist immer in Ihrer Kontrolle.
🔁 Iterative Verfeinerung durch Design
Unsere Erfahrung:
Während der Funktion zur Kursanmeldung starteten wir mit einem einfachen Modell: Student → Kurs. Nachdem die KI das ERD generiert hatte, erkannten wir, dass wir die Anmeldestatus (aktiv, abgemeldet, gescheitert). Wir gingen zurück zu Schritt 2, bearbeiteten die Anmeldung Klasse in PlantUML und generierten das Schema in weniger als 30 Sekunden neu.
✅ Urteil: Der zyklische Arbeitsablauf ist keine Theorie – er ist praktikabel. Wir behandeln die Schema-Design-Aufgabe nun wie einen Sprint, nicht wie eine einmalige Aufgabe.
🧪 Testen Sie vor der Bereitstellung – Der Playground hat alles verändert
Unsere Erfahrung:
Früher schrieben wir Integrationstests nachdem das Schema bereitgestellt war. Jetzt verifizieren wir das Verhalten, bevor wir eine einzige Codezeile schreiben.
Im Playground haben wir 500 Beispiel-Studenten generiert und sie in Kurse eingeschrieben. Wir führten komplexe Abfragen wie folgt aus:
SELECT s.name, COUNT(e.id) AS kursanzahl
FROM studenten s
JOIN anmeldungen e ON s.id = e.student_id
WHERE e.status = 'aktiv'
GROUP BY s.name
ORDER BY kursanzahl DESC;
Die Abfrage lieferte Ergebnisse sofort – keine Notwendigkeit, eine lokale Datenbank hochzufahren. Wir testeten sogar Grenzfälle: Was passiert, wenn ein Student alle Kurse abbricht? Die Constraint-Logik der KI verhinderte verwaiste Datensätze, und wir erkannten eine potenzielle Race Condition frühzeitig.
✅ Urteil: Das Playground beseitigte 80 % unserer Schema-Fehler nach der Bereitstellung.
📐 Normalisierung als erstklassige Funktion
Unsere Erfahrung:
Unser Junior-Entwickler war verwirrt, warum die KI geteilt hat Kurs in Kurs und KursDozent. Aber nachdem sie die Schritte 1NF → 2NF → 3NF durchgegangen waren, verstanden sie verstanden die Argumentation – insbesondere, als die KI zeigte, wie sich wiederholende Gruppen beseitigen ließen.
Wir verwenden diesen Schritt nun als Ausbildungsmodul für neue Mitarbeiter. Es ist wie ein interaktives Lehrbuch zur Datenbanktheorie.
✅ Urteil: Normalisierung ist kein Haken mehr – es ist ein lehrbares, sichtbares Verfahren.
🌐 Browser-nativ, keine Installationskosten
Unsere Erfahrung:
Einer unserer Teammitglieder war auf einem firmenverschlüsselten Laptop ohne Administratorrechte. Sie konnten Docker oder PostgreSQL nicht installieren. Aber sie traten über die Webanwendung dem Projekt bei, erstellten ein Schema und trugen innerhalb von unter zehn Minuten zur Gestaltung bei.
✅ Urteil: Das ist das inklusivste Datenbankwerkzeug, das ich je verwendet habe. Die Einarbeitung ist nun reibungslos.
Der 7-Schritte-AI-Workflow: Eine tiefgehende Betrachtung für Entwickler – Unsere Reise als Team
Schritt 1: Problem-Eingabe (konzeptionelle Eingabe)
Unser Prompt:
„Entwickeln Sie ein System zur Verwaltung von Hochschulkursen, Studierenden und Anmeldungen. Studierende können sich in mehreren Kursen anmelden. Jeder Kurs hat einen Dozenten. Anmeldungen verfolgen Noten, Zeitstempel und Status (aktiv, abgemeldet, durchgefallen). Alle Tabellen müssen enthalten
erstellt_amundaktualisiert_am.”
Unsere Einschätzung:
Der Beschreibungs-Generator der KI hat uns geholfen, unsere Eingabe zu verfeinern. Wir haben Einschränkungen und Geschäftsregeln hinzugefügt, die wir ursprünglich übersehen hatten.
✅ Tipp: Verwenden Sie Aufzählungspunkte. Die KI verarbeitet sie besser als lange Absätze.
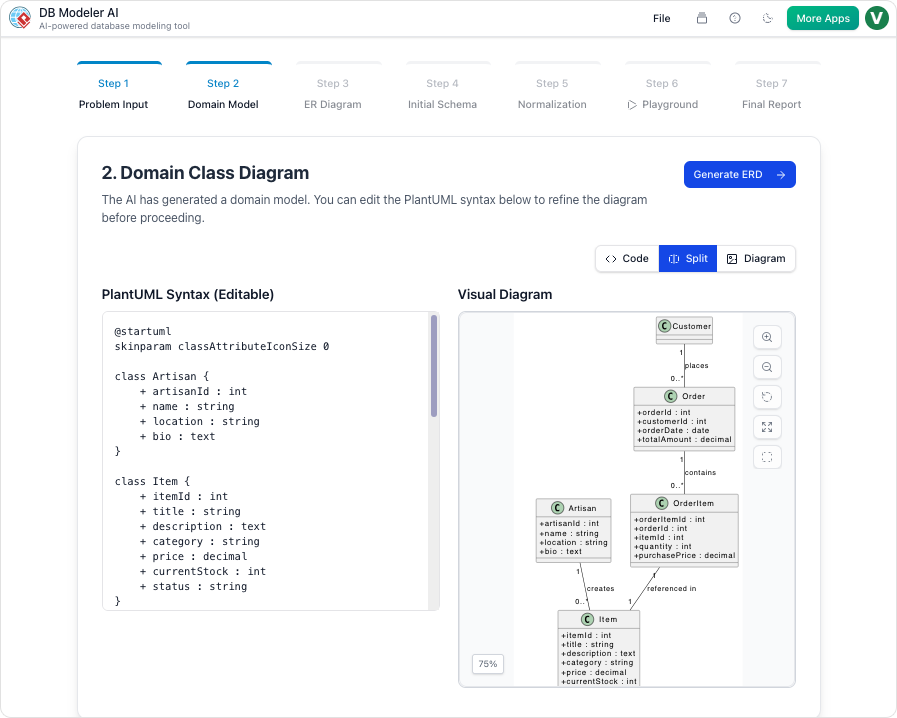
Schritt 2: Domänenmodell (konzeptionelle Modellierung)
Unsere Maßnahme:
Die KI generierte ein PlantUML-basiertes Domänenmodell. Wir umbenannten Student in Benutzer, fügten hinzu E-Mail, Rolle, und ist_aktiv Attribute, und klärten die Anmeldung Klasse.
Unsere Einschätzung:
Die visuelle Darstellung war sofort und übersichtlich. Wir teilten den PlantUML-Code in Slack, und unser Frontend-Team konnte die Struktur bereits sehen.
✅ Tipp: Verwenden
@noteKommentare in PlantUML, um Annahmen zu dokumentieren.
@note rechts
Diese Beziehung könnte eine Verbindungstabelle erfordern, wenn wir weiche Löschungen hinzufügen
@end note
Schritt 3: ER-Diagramm (logische Modellierung)
Unsere Maßnahme:
KI generierte automatisch PKs, FKs und Kardinalitäten. Wir stellten eine 1:N-Beziehung zwischen Kurs und Dozent—aber wir wollten einen Dozenten pro Kurs, daher passten wir es an auf 1:1.
Unsere Einschätzung:
Wir überprüften die Kardinalität erneut mit dem Team. Ein Fehler hier hätte Datenanomalien verursacht.
✅ Tipp: Validieren Sie immer Beziehungen mit den Produktbesitzern, bevor Sie abschließen.
Schritt 4: Anfangsschema (physische Codegenerierung)
Unsere Maßnahme:
Generierte PostgreSQL-DDL mit erstellt_am, aktualisiert_am, und CHECK Einschränkungen.
Unsere Einschätzung:
Wir verwendeten dies als die Basis für Flyway-Migrationen. Keine handgeschriebenen DDL mehr – nur noch versionskontrollierte Skripte.
✅ Tipp: Exportieren Sie DDL früh. Wir halten einen
schema/initialOrdner in Git.
Schritt 5: Normalisierung (Schema-Optimierung)
Unsere Maßnahme:
Wir gingen 1NF → 2NF → 3NF durch. Bei 2NF teilte die KI Einschreibung in Einschreibung und Einschreibungsverlauf auf, um partielle Abhängigkeiten zu beseitigen.
Unsere Einschätzung:
Wir diskutierten, ob wir es beibehalten sollten. Leistungsbezogen war 3NF für Joins langsamer. Daher normalisierten leicht zurück—fügte aktuelle_note zu Einschreibung—und dokumentierten die Abwägung im Endbericht.
✅ Tipp: Akzeptieren Sie 3NF nicht blind. Verwenden Sie es, um verstehendie Kompromisse.
Schritt 6: Playground (Validierung & Testen)
Unsere Maßnahme:
Wir starteten die PostgreSQL-Instanz im Browser. Wir nutzten KI, um 500 Studierende, 100 Kurse und 2.000 Einschreibungen zu generieren.
Unsere Einschätzung:
Wir führten einen Lasttest durch: 100 gleichzeitige Einschreibungen. Das Schema bestand. Außerdem testeten wir:
-
Kann ein Student sich zweimal für denselben Kurs anmelden?
-
Kann ein Dozent zwei Kurse gleichzeitig unterrichten?
Die Einschränkungen verhinderten ungültige Daten. Wir entdeckten einen Fehler in unserer Logikvorder Implementierung des Backend-Codes.
✅ Tipp:Erstelle Hunderte von Datensätzen. Die Abfrageleistung zeigt sich erst im großen Maßstab.
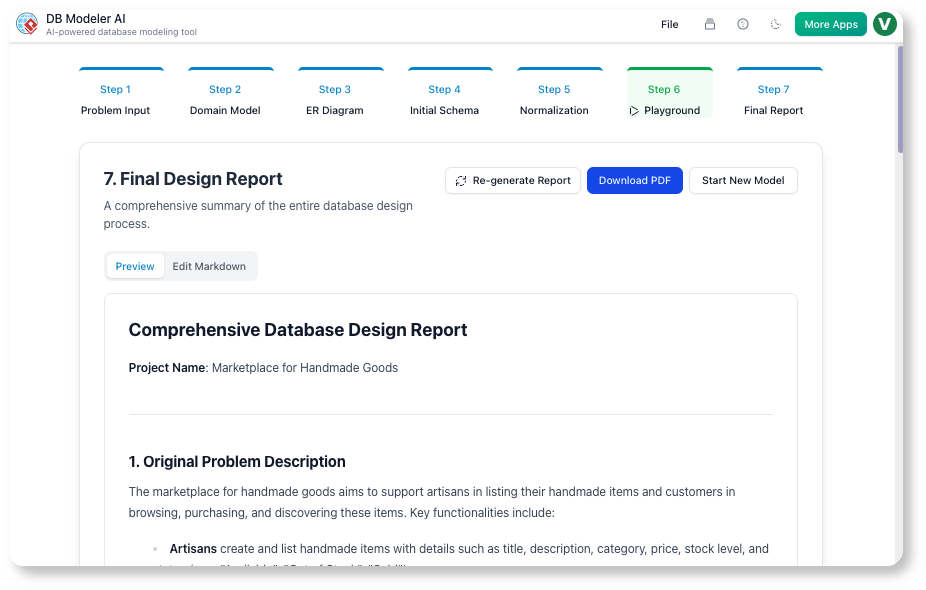
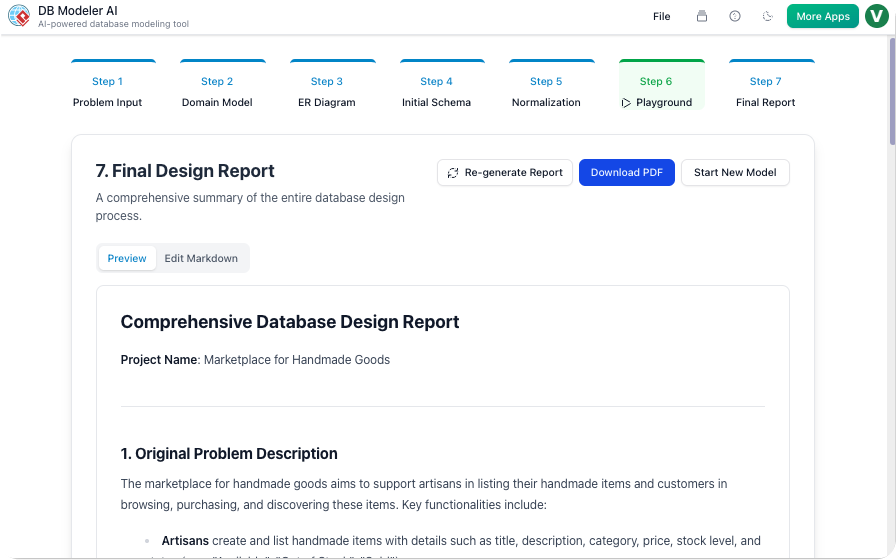
Schritt 7: Endbericht (Dokumentation)
Unsere Maßnahme:
KI generierte einen Markdown-Bericht mit:
-
Problemstellung
-
Diagramme (PNG + PlantUML)
-
Endgültiges Schema
-
Beispiel
INSERTAnweisungen
Wir fügten einen Entwurfsentscheidungen Abschnitt:
„Wir haben die
current_gradeentnormalisiert, um JOINs bei Echtzeit-Einschreibungsabfragen zu vermeiden. Dies verbessert die Leistung, kostet jedoch eine leicht erhöhte Schreibkomplexität.“
Unser Fazit:
Dieser Bericht wurde zu unserer Onboarding-Dokument. Neue Entwickler lesen es und verstehen das Schema in 15 Minuten.
✅ Tipp: Verwenden Sie den Endbericht als Übergabeprojekt für DevOps und QA.
Richtlinien & Best Practices: Was wir auf die harte Tour gelernt haben
| Praxis | Unsere Lektion |
|---|---|
| Fangen Sie klein an | Wir versuchten, das gesamte Hochschulsystem auf einen Schlag zu modellieren. Scheiterte. Jetzt teilen wir es in Module auf: Benutzer, Kurs, Anmeldung. |
| Versionskontrolle für PlantUML | Wir haben PlantUML-Dateien in Git committet. Diffs zeigten die Entwicklung des Schemas. Großer Vorteil für Audits. |
| Testen Sie mit Hunderten von Datensätzen | 10 Testdatensätze verbergen Leistungsprobleme. 500+ zeigten langsame JOINs auf. |
| Dokumentieren Sie Annahmen | „Keine weichen Löschungen“ → verursachte später einen Fehler. Jetzt dokumentieren wir jede Annahme. |
| Integrieren Sie in CI/CD | Wir haben ein validate-schema.sh Skript, das läuft pglint im exportierten DDL. |
Tipps & Tricks für Power-User (Unsere bewährten Kurzwege)
🔹 Prompt Engineering = Game-Changer
Anstatt:
„Erstelle ein Blog-System“
Wir verwenden nun:
*”Entwerfe eine PostgreSQL-Schema für eine mehrinstanzenfähige Blog-Plattform, bei der:
Jeder Mandant hat isolierte Beiträge und Kommentare
Beiträge unterstützen Tags und geplante Veröffentlichung
Kommentare können bis zu 3 Ebenen tief verschachtelt werden
Alle Tabellen enthalten
erstellt_amundaktualisiert_am“*
Ergebnis: Die KI generierte ein mandantenbewusstes Schema mit korrekter Isolation—etwas, das wir manuell verpasst hätten.
🔹 Verwende PlantUML-Kommentare zur Team-Synchronisation
Wir dokumentieren nun jede wichtige Entscheidung in PlantUML. Beispiel:
' @team: Überprüfe diese Beziehung – sollten wir einen `soft_deleted`-Flag hinzufügen?
' @arch: Genehmigt für v1.2. Wird in nächster Sprint hinzugefügt.
Benutzer "1" -- "0..*" Beitrag : schreibt
🔹 Exportiere früh, exportiere oft
Wir exportieren DDL und Markdown nach jeder wichtigen Iteration. Wir haben ein schema/versions/Ordner mit v1.0.sql, v1.1.sql, usw. Perfekt für Rückgängigmachen.
🔹 Mit Visual Paradigm Desktop verbinden
Für komplexe Projekte exportieren wir das PlantUML in die Desktop-Version, reverse-engineern bestehende Datenbanken und generieren SQL für MySQL oder SQL Server.
🔹 Lehren mit Normalisierungsschritten
Wir veranstalten ein „Schema-Kriegsspiel“, bei dem Junior-Entwickler den nächsten Normalisierungsschritt vorhersagen. Die Erklärung der KI gewinnt jedes Mal.
Zugriff, Lizenzierung und Integrationshinweise (Unsere Team-Einrichtung)
| Aspekt | Unsere Einrichtung |
|---|---|
| Plattform | Webbasiert über Visual Paradigm AI Toolbox |
| Lizenzierung | Visual Paradigm Online Combo (erforderlich für KI-Funktionen) |
| SQL-Dialekt | PostgreSQL (primär); Desktop-Ausgabe für MySQL/SQL Server |
| Exportformate | DDL, Markdown, PDF, JSON, PlantUML |
| Teamzusammenarbeit | Git + Markdown + gemeinsame Playground-Links |
| Verwendung ohne Internetverbindung | Nicht erforderlich – die Webversion ist schnell und zuverlässig |
💡 Pro-Tipp: Wir aktualisieren auf Teamwork Server für zentrale Modellversionierung und Zugriffssteuerung. Perfekt für Unternehmens-Teams.
Fazit: Die Zukunft der Datenbankgestaltung ist kooperativ, künstlich-intelligent und menschenzentriert
Nach zwei Monaten praktischer Nutzung in der Realität, DBModeler AI ist zu einem zentralen Bestandteil unserer Entwicklungsarbeit geworden.
Es ist nicht nur schneller—es ist intelligenter. Es zwingt uns, kritisch über Normalisierung, Einschränkungen und Randfälle nachzudenken. Es demokratisiert die Datenbankgestaltung über alle Rollen hinweg. Und es reduziert das Risiko kostspieliger Schema-Neustrukturen indem es Probleme erkennt vor dass sie die Produktion erreichen.
Der wertvollste Erkenntnis? KI ersetzt Fachwissen nicht—sie hebt es hervor. Wir schreiben nicht weniger Code. Wir schreiben besseren Code, schneller, mit größerer Sicherheit.
Wenn Sie es leid sind, unübersichtliche, unzureichend dokumentierte oder defekte Schemata zu haben—wenn Sie Datenbanken wie ein Profi gestalten, ohne die steile Lernkurve—dann ist DBModeler AI ist nicht nur ein Werkzeug. Es ist ein Game-Changer.
Bereit, Ihre Datenbank-Arbeitsweise zu verändern?
👉 Loslegen mit DBModeler AI
Keine Installation. Keine Einrichtung. Geben Sie einfach Ihre Idee ein und erstellen Sie innerhalb weniger Minuten ein produktionsfertiges Schema.
Referenzen
- DB Modeler AI | KI-gestütztes Werkzeug zur Datenbankgestaltung von Visual Paradigm: Offizielle Funktionsseite, die Fähigkeiten, Einsatzszenarien und Integrationsmöglichkeiten für DBModeler AI beschreibt.
- Die Beherrschung von DBModeler AI von Visual Paradigm: Detaillierter Tutorial und Workflow-Überblick durch einen Experten aus der Community, der praktische Umsetzungsstrategien abdeckt.
- DBModeler AI Werkzeugseite: Interaktive Werkzeug-Startseite mit FAQs, Merkmals-Highlights und direktem Zugriff auf den KI-Generator.
- DBModeler AI Versionshinweise: Offizielle Aktualisierungsprotokolle, Ankündigungen neuer Funktionen und Versionsgeschichte von Visual Paradigm.
- Übersicht über den DBModeler AI Datenbank-Generator: Kurze Zusammenfassung des Wertversprechens des Tools und des 7-Schritte-Workflows.
- Krankenhaus-Verwaltungssystem mit DBModeler AI: Fallstudie aus der Praxis, die die vollständige Datenbankgestaltung für einen Gesundheitsbereich demonstriert.
- Visual Paradigm AI-Toolbox – DBModeler AI-App: Direkter Einstiegspunkt, um die webbasierte DBModeler AI-Anwendung zu starten.
- DBModeler AI Video-Tutorial: Offizielles Video-Tutorial, das die Benutzeroberfläche, den Workflow und die wichtigsten Funktionen in Aktion zeigt.
- Kostenlose Freigabe des AI-Nutzungsfalldiagramm-Analyse-Tools: Hintergrundinformationen zum umfassenderen AI-Toolbox-Ökosystem von Visual Paradigm und Zugriffsanweisungen für Online-Nutzer.
- Tutorial zur Desktop-Integration: Videoführer zur Verbindung der DBModeler AI-Ausgaben mit Visual Paradigm Desktop für erweiterte Export- und Reverse-Engineering-Workflows.
✅ Letzter Gedanke:
Die besten Datenbanken werden nicht isoliert erstellt. Sie werden gemeinsam erstellt—von Produkt, Engineering und KI gemeinsam.
Mit DBModeler AI ist diese Zusammenarbeit endlich nahtlos.
Beginnen Sie heute, bessere Datengrundlagen zu schaffen.
Der Artikel ist auch in English, Español, فارسی, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 and 繁體中文 verfügbar.