













シニアフルスタックエンジニアによる | 実際の体験レポートと実践的インサイト、チームへの影響
はじめに:なぜこのツールがデータベース設計の方法を変えることになったのか
急速に進展するSaaSスタートアップのシニアフルスタックエンジニアとして、データベース設計プロセスがいかに苦難の連続だったかを目の当たりにしてきました。ホワイトボード上の急ごしらえのスケッチから、本番環境を破壊する最終調整のスキーマ再設計まで、データベースはしばしば最も弱いリンク私たちのデリバリー・パイプラインにおける
私たちが試したことはすべて:ERDツール、図式化プラグイン、スキーマ定義用のカスタムDSLまで。しかし、どれも「ビジネスの意図」と「本番環境対応SQL」の間にあるギャップを本質的に埋めることはできませんでした。ビジネスの意図と本番環境対応SQL特に新人エンジニアのオンボーディング時や、非技術的なプロダクトマネージャーと協業する際には。
そして登場したのがDBModeler AIVisual Paradigm社の製品です。
チームで2週間の試用を行った後、過剰な表現を避けずに言えるのは:これは10年以上使ってきた中で、最も変革的なデータベース設計ツールです。
これは単なるAI駆動の図面生成ツールではありません。それは共同設計エンジン自然言語を完全正規化され、テスト可能で文書化されたデータベーススキーマに変換するものであり、すべてブラウザ上で、セットアップゼロで実行可能。

このガイドでは、ユーザー認証、コース登録、注文管理の3つの主要機能において、DBModeler AIを実際にどのように使用したかをご紹介します。何がうまくいったか、何がうまくいかなかったか、そしてアジャイルワークフローにどのように統合したかを、スクリーンショット、チームのフィードバック、即座に実行可能なアドバイスとともに共有します。
開発チームのためのキーポイント (実際の現場での状況を踏まえて再検討)
🎯 AIは代替ではなく、共同デザイナーとしての役割
私たちの体験:
当初、AIが私たちが丁寧に設計したモデルを「上書き」してしまうのではないかと心配していました。しかしテストを経て、AIが「置き換える」のではなく置き換える判断力を強化するものだと気づきました.
例えば、「学生は複数の授業に登録できる」と説明した際、AIは正しく多対多の関係を推論し、中間テーブルの提案を行いました。しかし、私たちは PlantUMLコードを直接編集するソフトデリートフラグや監査タイムスタンプを追加することができました——AIは自動生成しなかったものの、コンプライアンスのために必要だったものです。
✅ 結論: AIは補助者であり、代替品ではない。常にあなたがコントロールしている。
🔁 設計による反復的改善
私たちの経験:
授業登録機能の開発中に、私たちはシンプルなモデルからスタートしました: 学生 → 授業。AIがERDを生成した後、私たちは登録状態を追跡する必要があることに気づきました 登録状態 (有効、退学、失敗)。ステップ2に戻り、PlantUMLの 登録 クラスを編集し、30秒未満でスキーマを再生成しました。
✅ 結論: 循環的なワークフローは理論的なものではなく、実用的です。今では、スキーマ設計を一度限りの作業ではなく、スプリントのように扱っています。
🧪 デプロイする前にテストする——プレイグラウンドがすべてを変えました
私たちの経験:
以前は、スキーマをデプロイした後に統合テストを書くことが普通でした。今では、 デプロイした後に スキーマをデプロイする前に、 1行のコードを書く前から動作を検証する.
プレイグラウンドでは、500人のサンプル生徒を生成し、授業に登録しました。以下のような複雑なクエリを実行しました:
SELECT s.name, COUNT(e.id) AS course_count
FROM students s
JOIN enrollments e ON s.id = e.student_id
WHERE e.status = 'active'
GROUP BY s.name
ORDER BY course_count DESC;
このクエリは即座に結果を返しました——ローカルDBを起動する必要はありませんでした。さらにエッジケースもテストしました:生徒がすべての授業を退学した場合どうなるか?AIの制約ロジックが孤立レコードの発生を防ぎ、潜在的な競合状態を早期に発見できました。
✅ 結論: プレイスメントは、デプロイ後のスキーマバグの80%を削減しました。
📐 正規化を第一級の機能として
私たちの体験:
私たちの新人開発者は、AIがなぜ分割したのかがわからず混乱していました。コース を コース と コースインストラクター。しかし、1NF → 2NF → 3NFのステップを順に確認した後、彼らはその理由を理解しました。特に、繰り返しグループがどのように排除されたかをAIが示したことで、より明確になりました。理解しました その理由—特にAIが繰り返しグループがどのように排除されたかを示したとき、特に理解が深まりました。
現在、私たちはこのステップを トレーニングモジュール 新人向けに使用しています。データベース理論のライブ教科書のようなものです。
✅ 結論: 正規化はもはやチェックボックスではなく、教えやすく、目に見えるプロセスです。
🌐 ブラウザネイティブ、インストールの負担なし
私たちの体験:
チームの一人が、管理者権限のない会社のロックされたラップトップを使っていました。DockerやPostgreSQLをインストールできませんでした。しかし、彼らは ウェブアプリ経由でプロジェクトに参加、スキーマを作成し、10分未満で設計に貢献しました。
✅ 結論: これは私がこれまで使った中で最も包括的なデータベースツールです。オンボーディングが今やスムーズです。
7段階AIワークフロー:開発者の深掘り – 私たちチームの旅
ステップ1:問題の入力(概念的入力)
私たちのプロンプト:
「大学の授業、学生、登録を管理するシステムを構築してください。学生は複数の授業に登録できます。各授業には1人の教員がいます。登録情報は成績、タイムスタンプ、ステータス(有効、退学、不合格)を記録します。すべてのテーブルには
created_atおよびupdated_at.”
私たちの見解:
AIの説明生成機能が、私たちの入力を洗練するのに役立ちました。当初見落としていた制約やビジネスルールを追加しました。
✅ ヒント: 箇条書きを使用してください。AIは長い段落よりも箇条書きをより良く処理します。
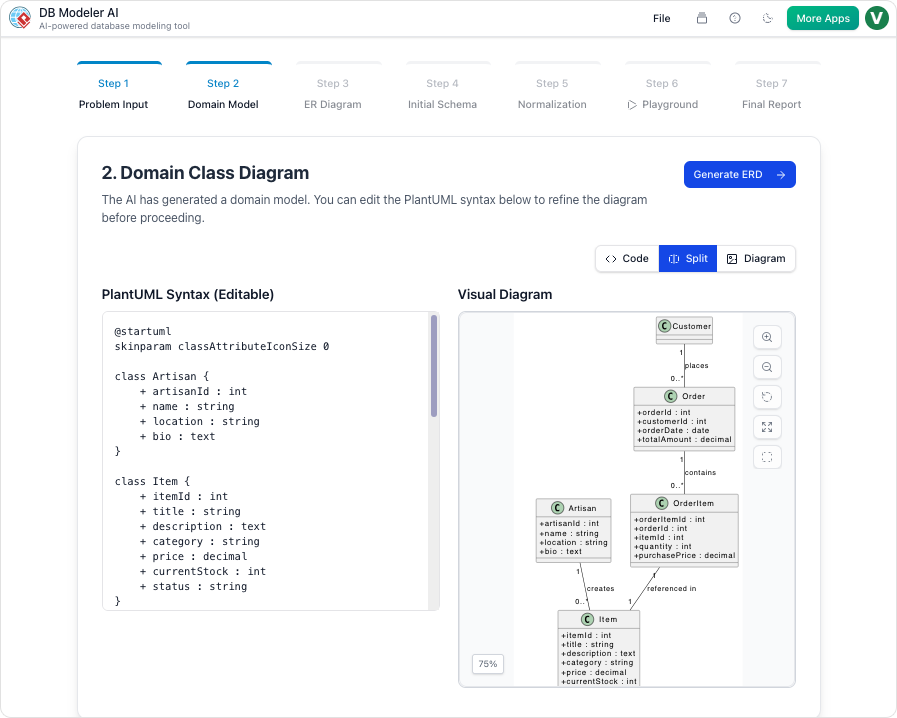
ステップ2:ドメインモデル(概念的モデリング)
私たちの行動:
AIはPlantUMLベースのドメインモデルを生成しました。私たちは Student を User、追加しました email, role、および is_active 属性を追加し、 Enrollment クラスを明確にしました。
私たちの見解:
視覚的なレンダリングは即座に、明快でした。私たちはPlantUMLコードをSlackで共有し、フロントエンドチームはすでに構造を把握できました。
✅ ヒント: 使用する
@notePlantUMLのコメントを使用して仮定を文書化する。
@note right
ソフトデリートを追加する場合、この関係には中間テーブルが必要になる可能性がある
@end note
ステップ3:ER図(論理モデル化)
私たちの行動:
AIが自動生成したPK、FKおよび基数。我々は Course と Instructor—しかし、我々は 1つのコースごとに1人のインストラクターであると考えたため、それを 1:1.
私たちの見解:
チームと相談して基数を再確認した。ここでの誤りはデータの不整合を引き起こしていた可能性がある。
✅ ヒント: 最終決定する前に、必ず製品所有者と関係性を検証する。
ステップ4:初期スキーマ(物理的コード生成)
私たちの行動:
PostgreSQL DDLを生成し、 created_at, updated_at、および CHECK制約。
私たちの見解:
私たちはこれを基準として使用しました。Flywayマイグレーションのベースラインもう手書きのDDLは不要です。バージョン管理されたスクリプトだけです。
✅ ヒント:DDLは早期にエクスポートしましょう。私たちはGitに
schema/initialフォルダを保持しています。
ステップ5:正規化(スキーマ最適化)
私たちの行動:
私たちは1NF → 2NF → 3NFを順に確認しました。2NFでAIはEnrollmentをEnrollmentとEnrollmentHistoryに分割して部分的依存を排除しました。
私たちの見解:
保持するかどうか議論しました。パフォーマンス面では、3NFは結合に対して遅くなりました。そのため私たちはやや非正規化—current_gradeをEnrollmentに追加し、最終報告書にトレードオフを記録しました。
✅ ヒント:3NFを盲目的に受け入れないでください。それを使用して理解するトレードオフを理解する。
ステップ6:プレイグラウンド(検証とテスト)
私たちの行動:
ブラウザ内にPostgreSQLインスタンスを起動しました。AIを活用して、500人の学生、100の授業、2,000件の登録データを生成しました。
私たちの見解:
ストレステストを実施しました:100件の同時登録。スキーマは問題なく維持されました。また、以下の点も検証しました:
-
学生が同じ授業に2回登録することは可能か?
-
講師が同時に2つの授業を担当することは可能か?
制約が無効なデータの登録を防ぎました。論理上のバグを、バックエンドコードを書く前段階で発見できました。前バックエンドコードを書く
✅ ヒント:数百件のレコードを生成する。クエリのパフォーマンスはスケールが大きくなってからしか明らかにならない。
ステップ7:最終レポート(ドキュメント化)
私たちの行動:
AIが以下を含むMarkdownレポートを生成しました:
-
問題の提示
-
図(PNG + PlantUML)
-
最終的なスキーマ
-
サンプル
INSERT文
以下のセクションを追加しました:設計意思決定セクション:
「我々は、リアルタイムの登録クエリでJOINを避けるために、
current_gradeを非正規化しました。これによりパフォーマンスが向上しますが、書き込みの複雑さがわずかに増加します。」
私たちの見解:
このレポートは私たちの オンボーディングドキュメント。新規開発者はこれを読み、15分でスキーマを理解しました。
✅ ヒント: 最終レポートを 引き継ぎアーティファクト としてDevOpsおよびQAに渡す。
ガイドライン&ベストプラクティス:私たちが苦労して学んだこと
| 実践 | 私たちの教訓 |
|---|---|
| 小さな規模から始める | 一度に大学全体のシステムをモデル化しようとしました。失敗しました。今では、モジュールに分割して対応しています: ユーザー, コース, 登録. |
| PlantUMLのバージョン管理 | PlantUMLファイルをGitにコミットしました。差分からスキーマの進化が確認できました。監査において大きな利点です。 |
| 数百件のレコードでテストする | 10件のテストレコードではパフォーマンスの問題が隠れています。500件以上で遅いJOINが明らかになりました。 |
| 前提条件を文書化する | 「ソフトデリートなし」→ 後にバグを引き起こしました。今ではすべての前提条件を文書化しています。 |
| CI/CDに統合する | 私たちは validate-schema.sh スクリプトを追加し、 pglintエクスポートされたDDLの上に。 |
プロユーザー向けのヒントとテクニック (私たちチームの検証済みのショートカット)
🔹 プロンプト工学 = ハイパーカンバージョン
代わりに:
「ブログシステムを構築する」
今では次のように使用しています:
*「マルチテナントブログプラットフォーム用のPostgreSQLスキーマを設計する。条件は以下の通り:」
各テナントは投稿とコメントを独立して持つ
投稿はタグとスケジュール付き公開をサポートする
コメントは最大3段階までネスト可能
すべてのテーブルには含まれる
created_atおよびupdated_at“*
結果:AIはテナント対応のスキーマで適切な分離がなされている—手動で作成する際に見逃していた可能性があるもの。
🔹 チームの調整のためにPlantUMLコメントを使用する
今ではPlantUMLですべての主要な意思決定をコメントで記録しています。例:
' @team: この関係性を確認してください—`soft_deleted`フラグを追加すべきでしょうか?
' @arch: v1.2で承認。次回スプリントで追加します。
User "1" -- "0..*" Post : writes
🔹 早期にエクスポートし、頻繁にエクスポートする
主要なイテレーションごとにDDLとMarkdownをエクスポートしています。私たちはschema/versions/フォルダにv1.0.sql, v1.1.sqlなど。ロールバックに最適です。
🔹 Visual Paradigm Desktopと連携
複雑なプロジェクトでは、PlantUMLをデスクトップにエクスポートし、既存のデータベースをリバースエンジニアリングして、MySQLまたはSQL Server用のSQLを生成します。
🔹 正規化ステップで学習を指導
若手が次の正規化ステップを予測する「スキーマ・ウォーゲーム」を実施しています。AIの説明が常に勝利します。
アクセス、ライセンスおよび統合に関するメモ (私たちのチームの設定)
| 側面 | 私たちの設定 |
|---|---|
| プラットフォーム | Webベース(経由)Visual Paradigm AIツールボックス |
| ライセンス | Visual Paradigm Online Combo(AI機能に必須) |
| SQL方言 | PostgreSQL(主に);MySQL/SQL Server用デスクトップ版 |
| エクスポート形式 | DDL、Markdown、PDF、JSON、PlantUML |
| チーム協働 | Git + Markdown + 共有されたPlaygroundリンク |
| オフライン使用 | 不要です—Web版は高速かつ信頼性があります |
💡 プロのメモ: 我々はアップグレードしています Teamwork Server 中央集権的なモデルバージョン管理とアクセス制御のためです。企業チームに最適です。
結論:データベース設計の未来は、共同作業可能で、AI駆動型かつ人間中心的です
実際の使用を2か月経過した後、 DBModeler AIは開発ワークフローの中心的な部分となりました.
速いだけでなく、それ以上に 賢い。正規化、制約、エッジケースについて深く考えるよう強制します。役割に関係なくデータベース設計を民主化します。そして、它 高コストなスキーマ再設計のリスクを低減します 問題を早期に発見することで 前 本番環境に到達する前に。
最も価値のある洞察は? AIは専門知識を置き換えるのではなく、それを高めるものです。 コードを書く量は減っていません。むしろ、 より良いコード、より速く、より確信を持って。
ごみだらけで、ドキュメントがなく、壊れたスキーマにうんざりしているなら—もしプロのようにデータベースを設計したいが、急激な学習曲線を避けたいならプロのようにデータベースを設計できるが、急激な学習曲線なしに—それならば DBModeler AIは単なるツールではありません。ゲームチェンジャーです。
データベースワークフローを変革する準備はできていますか?
👉 DBModeler AIで始める
インストール不要。セットアップ不要。アイデアを入力するだけで、数分で本番環境対応のスキーマを構築できます。
参考文献
- DB Modeler AI | Visual ParadigmによるAI駆動型データベース設計ツール:DBModeler AIの機能、使用事例、統合オプションについて詳述した公式機能ページ。
- Visual ParadigmによるDBModeler AIの習得: コミュニティの専門家による詳細なチュートリアルとワークフローの解説で、実践的な実装戦略を網羅しています。
- DBModeler AIツールページ: FAQ、機能のハイライト、AIジェネレーターへの直接アクセスを備えたインタラクティブなツールのランディングページ。
- DBModeler AIリリースノート: Visual Paradigmによる公式の更新ログ、新機能の発表、バージョン履歴。
- DBModeler AIデータベースジェネレーター概要: ツールの価値提案と7ステップのワークフローの簡潔な要約。
- DBModeler AIを活用した病院管理システム: 医療分野におけるエンドツーエンドのデータベース設計を実証する実際のケーススタディ。
- Visual Paradigm AIツールボックス – DBModeler AIアプリ: ウェブベースのDBModeler AIアプリを起動するための直接的なエントリーポイント。
- DBModeler AI動画ガイド: インターフェース、ワークフロー、主要機能の実際の動作を紹介する公式動画チュートリアル。
- 無料AIユースケース図アナライザーのリリース: Visual Paradigmの包括的なAIツールボックスエコシステムに関する背景情報と、Onlineユーザー向けのアクセス手順。
- デスクトップ統合チュートリアル: DBModeler AIの出力結果をVisual Paradigm Desktopと連携し、高度なエクスポートやリバースエンジニアリングワークフローを実現するための動画ガイド。
✅ 最後の考え:
最高のデータベースは、孤立して作られるものではありません。それらは共に創り出される——プロダクト、エンジニアリング、そしてAIによって。
DBModeler AIがあれば、その協働はついにスムーズに実現します。
今日から、より良いデータ基盤を構築し始めましょう。