













توسط یک مهندس پیشرفته فولاستک | گزارش تجربه سومی با بینشهای عملی و تأثیر بر تیم
مقدمه: چرا این ابزار نحوه طراحی پایگاه دادههای ما را تغییر داد
به عنوان یک مهندس پیشرفته فولاستک در یک استارتآپ سریعالحرکت SaaS، فرآیند طراحی پایگاه داده ما را از بین بردهام. از طرحهای عجلهای روی تختهسیاه تا بازطراحیهای آخرین لحظهای طرح که تولید را خراب کرد، پایگاه داده اغلب نقطه ضعف در خط لوله تحویل ما بوده است.ضعیفترین اتصالدر خط لوله تحویل ما.
همه چیز را امتحان کردهایم: ابزارهای ERD، پلاگینهای نمودارسازی، حتی زبانهای سفارشی (DSL) برای تعریف طرح. اما هیچکدام واقعاً فاصله بین قصد کسبوکارو SQL آماده تولید—به ویژه هنگام آموزش مهندسان جوان یا همکاری با مدیران محصول غیرفنی.
سپس آمد DBModeler AI توسط Visual Paradigm.
پس از آزمایش دو هفتهای با تیم من، میتوانم بدون اغراق بگویم: این بیشترین ابزار تغییردهنده در طراحی پایگاه دادهای است که در بیش از ده سال استفاده کردهام.
این فقط یک تولیدکننده نمودار پشتیبانیشده از هوش مصنوعی دیگر نیست. این یک موتور طراحی همکاریایاست که زبان طبیعی را به یک طرح پایگاه داده کاملاً نرمالشده، قابل آزمون و مستند شده تبدیل میکند—همه در مرورگر، بدون نیاز به تنظیم اولیه.

در این راهنما، تجربه واقعی ما با استفاده از DBModeler AI در سه ویژگی اصلی—احراز هویت کاربر، ثبتنام در دورهها و مدیریت سفارشات—را به شما نشان میدهم. چیزهایی که کار کردند، چیزهایی که کار نکردند و نحوه ادغام آن در فرآیند آگیل ما را به اشتراک میگذارم—همراه با تصاویر اسکرینشات، بازخوردهای تیم و نکات عملی که میتوانید فوراً به کار بگیرید.
مفاهیم کلیدی برای تیمهای توسعه (بازبینی شده با زمینه واقعی دنیا)
🎯 هوش مصنوعی به عنوان یک طراح همکار، نه جایگزین
تجربه ما:
ما ابتدا نگران بودیم که هوش مصنوعی مدلهای دستساز دقیق ما را «جایگزین» کند. اما پس از آزمون، متوجه شدیم که هوش مصنوعی نمیتواند جایگزین کند قضاوت کند—بلکه آن را تقویت میکند.
به عنوان مثال، هنگامی که ما یک «دانشجو میتواند در چندین درس ثبتنام کند» توصیف کردیم، هوش مصنوعی به درستی رابطه چند به چند را استنتاج کرد و یک جدول واسطه پیشنهاد داد. اما ما توانستیمکد PlantUML را به صورت مستقیم ویرایش کنیمتا پرچم حذف نرم و زمانهای بازرسی را اضافه کنیم—چیزی که هوش مصنوعی به طور خودکار تولید نکرد اما ما برای رعایت مقررات به آن نیاز داشتیم.
✅ نتیجهگیری:هوش مصنوعی یک همکار پرواز است، نه جایگزین. شما همیشه کنترل را در دست دارید.
🔁 بهبود تدریجی به صورت طراحی شده
تجربه ما:
در طول ویژگی ثبتنام درس، ما با یک مدل ساده شروع کردیم:دانشجو → درس. پس از اینکه هوش مصنوعی ERD را تولید کرد، متوجه شدیم که باید وضعیت ثبتنام را ردیابی کنیموضعیت ثبتنام (فعال، لغو شده، شکست خورده). ما به مرحله دوم بازگشتیم، کلاسثبتنام را در PlantUML ویرایش کردیم و در کمتر از ۳۰ ثانیه مدل را دوباره تولید کردیم.
✅ نتیجهگیری:جریان چرخهای نظری نیست—کاربردی است. اکنون طراحی مدل را مانند یک اسپرینت، نه یک کار یکباره در نظر میگیریم.
🧪 قبل از انتشار تست کنید – فضای بازی تغییر کلی ایجاد کرد
تجربه ما:
ما قبلاً تستهای ادغامی مینوشتیمپس ازمدل اجرا شد. اکنون مارفتار را قبل از نوشتن هر خط کدی اعتبارسنجی میکنیم.
در فضای بازی، ۵۰۰ دانشجوی نمونه تولید کردیم و آنها را در دروس ثبتنام کردیم. ما پرسوجوهای پیچیدهای مانند زیر را اجرا کردیم:
SELECT s.name, COUNT(e.id) AS course_count
FROM students s
JOIN enrollments e ON s.id = e.student_id
WHERE e.status = 'active'
GROUP BY s.name
ORDER BY course_count DESC;
این پرسوجو نتایج را فوراً برگرداند—نیازی به راهاندازی یک پایگاه داده محلی نبود. حتی موارد لبه را تست کردیم: اگر دانشجو تمام دروس را لغو کند چه اتفاقی میافتد؟ منطق محدودیت هوش مصنوعی از ایجاد رکوردهای بیسرپرست جلوگیری کرد و ما یک شرایط احتمالی رقابتی را به موقع شناسایی کردیم.
✅ حكم:حیاط بازی 80 درصد از باگهای ساختاری ما پس از انتشار را حذف کرد.
📐 استانداردسازی به عنوان ویژگی اولیه
تجربه ما:
توسعهدهنده جوان ما از اینکه هوش مصنوعی چرا تقسیم کرد شگفتزده بوددوره به دوره و مربی_دوره. اما پس از گذراندن مراحل 1NF → 2NF → 3NF، آنها درک کردند—به ویژه وقتی هوش مصنوعی نشان داد که گروههای تکراری چگونه حذف شدند.درک کردند دلیل آن را—به ویژه وقتی هوش مصنوعی نشان داد که گروههای تکراری چگونه حذف شدند.
اکنون این مرحله را به عنوان یکماژول آموزشی برای استخدامهای جدید استفاده میکنیم. این مانند یک کتاب درسی زنده در مورد نظریه پایگاه داده است.
✅ حكم:استانداردسازی دیگر یک تیک کردن نیست—این یک فرآیند آموزشپذیر و قابل مشاهده است.
🌐 بومی مرورگر، بدون بار نصب
تجربه ما:
یکی از اعضای تیم ما روی لپتاپ قفل شده شرکت بود که دسترسی مدیریتی نداشت. نتوانست Docker یا PostgreSQL نصب کند. اما آنها از طریق برنامه وب به پروژه پیوستند، یک ساختار ایجاد کردند و در کمتر از 10 دقیقه به طراحی کمک کردند.
✅ حكم:این بیشترین ابزار پایگاه داده شاملگرایانهای است که تا به حال استفاده کردهام. ورود به سیستم اکنون بدون اصطکاک است.
راهنمای 7 مرحلهای هوش مصنوعی: یک نگاه عمیق توسعهدهنده – سفر تیم ما
مرحله 1: ورودی مسئله (ورودی مفهومی)
پرامپت ما:
«سیستمی برای مدیریت دروس دانشگاه، دانشجویان و ثبتنامها بسازید. دانشجویان میتوانند در چندین درس ثبتنام کنند. هر درس دارای یک مدرس است. ثبتنامها نمرات، زمانهای ثبت و وضعیت (فعال، کنسل شده، شکست خورده) را ردیابی میکنند. تمام جداول باید شامل
created_atوupdated_at.”
دیدگاه ما:
تولیدکننده توضیحات هوش مصنوعی به ما کمک کرد تا ورودی خود را بهبود بخشیم. محدودیتها و قوانین کسبوکاری را که در ابتدا نادیده گرفته بودیم، اضافه کردیم.
✅ نکته: از نقاط فهرست استفاده کنید. هوش مصنوعی آنها را بهتر از پاراگرافهای طولانی تحلیل میکند.
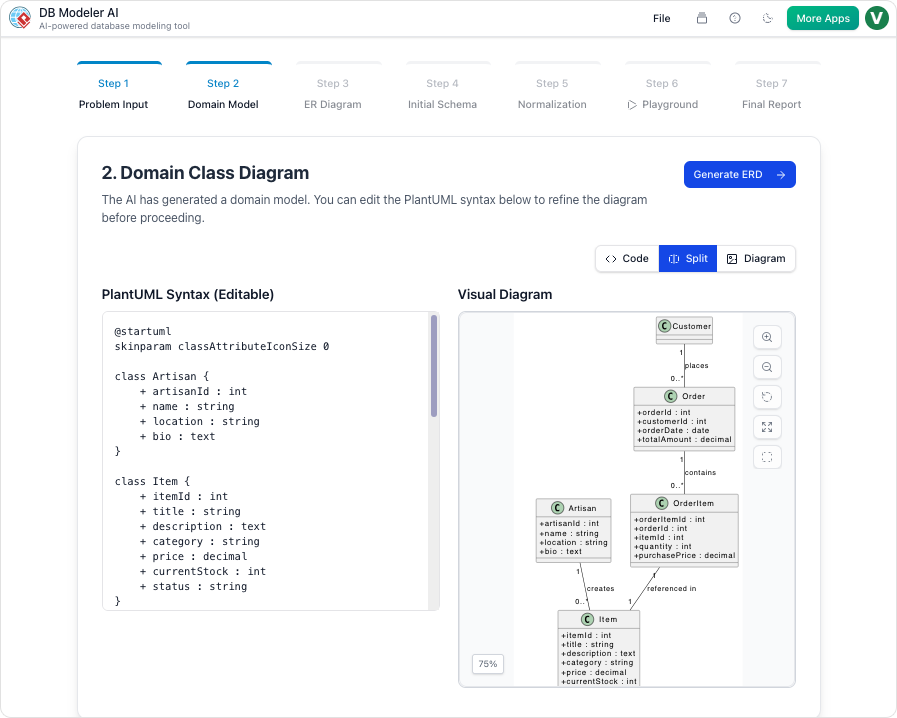
مرحله 2: مدل دامنه (مدلسازی مفهومی)
اقدام ما:
هوش مصنوعی یک مدل دامنه مبتنی بر PlantUML تولید کرد. ما Student را به Userتغییر دادیم، و email, role، و is_active ویژگیها را اضافه کردیم و کلاس Enrollment را روشنتر کردیم.
دیدگاه ما:
نمایش بصری فوری و تمیز بود. کد PlantUML را در Slack به اشتراک گذاشتیم و تیم فرانتاند ما از همان ابتدا ساختار را میتوانستند ببینند.
✅ نکته: از
@نکتهکامنتهای در PlantUML برای مستندسازی فرضیات.
@نکته راست
این رابطه ممکن است نیاز به جدول اتصال داشته باشد اگر حذف نرم اضافه کنیم
@end note
مرحله ۳: نمودار ER (مدلسازی منطقی)
اقدام ما:
هوش مصنوعی PKs، FKs و قابلیتهای کاردینالیتی را خودکار تولید کرد. متوجه شدیم که رابطهای ۱:N بین دوره و مربی—اما ما میخواستیم یک مربی برای هر دوره, بنابراین آن را به 1:1.
دیدگاه ما:
ما دوباره کاردینالیتی را با تیم بررسی کردیم. اشتباه در اینجا باعث بروز ناهماهنگیهای دادهای میشد.
✅ نکته: همیشه روابط را قبل از نهایی کردن با صاحب محصول تأیید کنید.
مرحله ۴: طرح اولیه (تولید کد فیزیکی)
اقدام ما:
DDL پستگرس را با ایجاد_شده_در, بهروزرسانی_شده_در، و بررسیمحدودیتها.
دیدگاه ما:
ما از این به عنوان اساس استفاده کردیمپایهای برای مهاجرتهای فلایوی. دیگر نیازی به نوشتن دستی DDL نیست—فقط اسکریپتهای کنترل نسخه.
✅ نکته:DDL را به زودی خروجی بگیرید. ما یک پوشهی
schema/initialدر گیت نگه میداریم.
مرحله ۵: نرمالسازی (بهینهسازی شکلگیری)
اقدام ما:
ما از 1NF به 2NF و سپس به 3NF را بررسی کردیم. در 2NF، هوش مصنوعی جدولEnrollmentرا به دو بخشEnrollmentوEnrollmentHistoryتقسیم کرد تا وابستگیهای جزئی حذف شوند.
دیدگاه ما:
ما در مورد اینکه آیا باید آن را حفظ کنیم، بحث کردیم. از نظر عملکرد، 3NF برای اتصالها کندتر بود. بنابراین ما کمی از نرمالسازی خارج شدیمکمی نرمالسازی را لغو کردیم—فیلدcurrent_gradeرا بهEnrollmentافزودیم—و این تلفیق را در گزارش نهایی مستند کردیم.
✅ نکته:به طور کورکورانه 3NF را قبول نکنید. از آن برایدرک کردن ملاحظات و تناقضات را.
مرحله ۶: فضای بازی (اعتبارسنجی و آزمون)
اقدام ما:
ما نمونه PostgreSQL در مرورگر را راهاندازی کردیم. از هوش مصنوعی برای تولید ۵۰۰ دانشجو، ۱۰۰ دوره و ۲۰۰۰ ثبتنام استفاده کردیم.
نگاه ما به این موضوع:
ما آزمون بار سنگین انجام دادیم: ۱۰۰ ثبتنام همزمان. ساختار دادهها مقاومت کرد. همچنین آزمونهای زیر را انجام دادیم:
-
آیا دانشجو میتواند در یک دوره یکبار دیگر ثبتنام کند؟
-
آیا یک مربی میتواند دو دوره را همزمان تدریس کند؟
محدودیتها از ورود دادههای نامعتبر جلوگیری کردند. ما یک اشکال منطقی را پیش از نوشتن کد سمت پشتیابانی شناسایی کردیمپیش از نوشتن کد سمت پشتیابانی.
✅ نکته: صدها رکورد تولید کنید. عملکرد پرسوجوها فقط در مقیاس بزرگ نمایان میشود.
مرحله ۷: گزارش نهایی (مستندسازی)
اقدام ما:
هوش مصنوعی گزارش Markdown را با موارد زیر تولید کرد:
-
بیان مسئله
-
نمودارها (PNG + PlantUML)
-
ساختار نهایی
-
نمونه
INSERTدستورات
ما بخشی به نام تصمیمات طراحی بخش:
«ما از نرمالسازی خارج شدیم
current_gradeتا از JOINها در پرسوجوهای ثبتنام بلادرنگ جلوگیری کنیم. این کار عملکرد را بهبود میبخشد، اما پیچیدگی کمی در نوشتن دادهها را افزایش میدهد.»
نگاه ما به این موضوع:
این گزارش به یکی از مدارک ورودی ما تبدیل شدمستندات ورودی. توسعهدهندگان جدید آن را خواندند و در 15 دقیقه ساختار دادهها را درک کردند.
✅ نکته:از گزارش نهایی به عنوان یکمحل تحویلبرای تیمهای DevOps و QA استفاده کنید.
دستورالعملها و بهترین روشها: آنچه به سختی یاد گرفتیم
| تمرین | درسی که یاد گرفتیم |
|---|---|
| از کوچک شروع کنید | سعی کردیم کل سیستم دانشگاه را در یک مرحله مدلسازی کنیم. شکست خوردیم. اکنون آن را به ماژولهای کوچکتر تقسیم میکنیم:کاربر, درس, ثبتنام. |
| کنترل نسخهی PlantUML | فایلهای PlantUML را به Git ارسال کردیم. تفاوتهای بین نسخهها، تحول ساختار دادهها را نشان داد. این امر به ویژه در بازبینیها بسیار مفید بود. |
| با صدها رکورد تست کنید | 10 رکورد تستی ممکن است مشکلات عملکردی را پنهان کنند. اما بیش از 500 رکورد، JOINهای کند را آشکار کرد. |
| فرضیات را مستند کنید | «حذف نرم وجود ندارد» → در مراحل بعدی باعث بروز اشکال شد. اکنون هر فرضیهای را مستند میکنیم. |
| با CI/CD یکپارچه شوید | ما یک اسکریپت اضافه کردیم:validate-schema.shاسکریپتی که اجرا میشودpglintدر DDL صادر شده. |
نکات و ترفندهای کاربران حرفهای (کلیدواژههای اثبات شده تیم ما)
🔹 مهندسی پرامپت = تغییر دهنده بازی
به جای:
«ساخت یک سیستم بلاگ»
اکنون از این استفاده میکنیم:
*«طراحی یک طرح PostgreSQL برای یک پلتفرم بلاگ چندکاربره به گونهای که:
هر کاربر دسترسی جداگانه به پستها و نظرات دارد
پستها از برچسبها و انتشار برنامهریزی شده پشتیبانی میکنند
نظرات میتوانند تا سه سطح درونیابی شوند
تمام جداول شامل
created_atوupdated_at“*
نتیجه:هوش مصنوعی یک طرحی با آگاهی از کاربر و جداسازی مناسب—چیزی که به طور دستی از دست داده بودیم.
🔹 از کامنتهای PlantUML برای همسازی تیم استفاده کنید
اکنون هر تصمیم مهم را در PlantUML توضیح میدهیم. مثال:
' @تیم: این رابطه را بررسی کنید—آیا باید یک پرچم `soft_deleted` اضافه کنیم؟
' @معمار: برای نسخه 1.2 تأیید شد. در اسپرینت بعدی اضافه خواهد شد.
کاربر "1" -- "0..*" پست : مینویسد
🔹 صادر کردن زودهنگام، صادر کردن مکرر
پس از هر تکمیل اصلی، DDL و Markdown را صادر میکنیم. ما یک schema/versions/پوشه باv1.0.sql, v1.1.sql, و غیره. عالی برای بازگشت به حالت قبل.
🔹 با Visual Paradigm Desktop همپیمان شوید
برای پروژههای پیچیده، ما PlantUML را به دسکتاپ صادر میکنیم، پایگاه دادههای موجود را معکوس مهندسی میکنیم و SQL برای MySQL یا SQL Server تولید میکنیم.
🔹 با مراحل نرمالسازی آموزش دهید
ما یک «بازی جنگ طرح» انجام میدهیم که در آن جوانان مرحله بعدی نرمالسازی را پیشبینی میکنند. توضیحات هوش مصنوعی هر بار برنده میشود.
نکات دسترسی، مجوزدهی و ادغام (تنظیمات تیم ما)
| جنبه | تنظیمات ما |
|---|---|
| پلتفرم | بر پایه وب از طریقجعبه ابزار هوش مصنوعی Visual Paradigm |
| مجوزدهی | ترکیب آنلاین Visual Paradigm (ضروری برای ویژگیهای هوش مصنوعی) |
| گونه SQL | PostgreSQL (اصلی); نسخه دسکتاپ برای MySQL/SQL Server |
| فرمتهای صادراتی | DDL، Markdown، PDF، JSON، PlantUML |
| همکاری تیمی | Git + Markdown + لینکهای اشتراکی Playground |
| استفاده آفلاین | نیازی نیست—نسخه وب سریع و قابل اعتماد است |
💡 نکته حرفهای:در حال بهروزرسانی به سرور همکاریبرای مدیریت نسخههای متمرکز مدل و کنترل دسترسی. عالی برای تیمهای سازمانی.
نتیجهگیری: آینده طراحی پایگاه داده همکاریمحور، پشتیبانیشده از هوش مصنوعی و متمرکز بر انسان است
پس از دو ماه استفاده در دنیای واقعی، DBModeler AI به بخش اصلی فرآیند توسعه ما تبدیل شده است.
این فقط سریعتر نیست—این هوشمندتر. ما را مجبور به فکر کردن انتقادی درباره نرمالسازی، محدودیتها و موارد لبهای میکند. طراحی پایگاه داده را در بین نقشها دموکراتیک میکند. و این ریسک بازطراحیهای گرانقیمت ساختار پایگاه داده را کاهش میدهدبا شناسایی مشکلات قبل از اینکهبه محیط تولید برسند.
مهمترین بینش؟ هوش مصنوعی تخصص را جایگزین نمیکند—بلکه آن را ارتقا میدهد.ما کمتر کد نمینویسیم. ما کد بهتریسریعتر، با اعتماد بیشتر.
اگر از ساختارهای پیچیده، بدون مستندات یا معیوب خسته شدهاید—اگر میخواهید پایگاه دادهها را مانند حرفهای طراحی کنید، بدون منحنی یادگیری شیبدار—پس DBModeler AI فقط یک ابزار نیست. این یک تحول است.
آماده تبدیل فرآیند پایگاه داده خود هستید؟
👉 شروع کنید با DBModeler AI
نصب نیاز نیست. تنظیم نیاز نیست. فقط ایده خود را تایپ کنید و در عرض چند دقیقه یک ساختار آماده تولید بسازید.
منابع
- DB Modeler AI | ابزار طراحی پایگاه داده پشتیبانیشده از هوش مصنوعی توسط Visual Paradigm: صفحه ویژگی رسمی که قابلیتها، موارد استفاده و گزینههای ادغام برای DBModeler AI را توضیح میدهد.
- تسلط بر DBModeler AI توسط Visual Paradigm: آموزش جامع و مرور کامل فرآیند توسط یک متخصص جامعه، شامل استراتژیهای عملی اجرایی.
- صفحه ابزار DBModeler AI: صفحه ورودی ابزار تعاملی با پرسشهای متداول، ویژگیهای برجسته و دسترسی مستقیم به تولیدکننده هوش مصنوعی.
- یادداشتهای انتشار DBModeler AI: یادداشتهای رسمی بهروزرسانی، اعلان ویژگیهای جدید و تاریخچه نسخهها از Visual Paradigm.
- مرور کلی تولیدکننده پایگاه داده DBModeler AI: خلاصهای فشرده از ارزش ابزار و فرآیند هفت مرحلهای آن.
- سیستم مدیریت بیمارستان با DBModeler AI: مطالعه موردی واقعی که طراحی پایگاه داده از ابتدا تا انتها در حوزه بهداشت و درمان را نشان میدهد.
- جعبه ابزار هوش مصنوعی Visual Paradigm – اپلیکیشن DBModeler AI: نقطه ورود مستقیم برای راهاندازی اپلیکیشن DBModeler AI مبتنی بر وب.
- مرور ویدیویی DBModeler AI: آموزش ویدیویی رسمی که رابط، فرآیند کار و ویژگیهای کلیدی را در عمل نشان میدهد.
- انتشار تحلیلگر نمودار موارد استفاده هوش مصنوعی رایگان: زمینهای درباره اکوسیستم گسترده جعبه ابزار هوش مصنوعی Visual Paradigm و دستورالعملهای دسترسی برای کاربران آنلاین.
- آموزش ادغام دسکتاپ: راهنمای ویدیویی درباره اتصال خروجیهای DBModeler AI با Desktop Visual Paradigm برای جریانهای پیشرفته صادرات و بازسازی معکوس.
✅ نکته نهایی:
بهترین پایگاههای داده به تنهایی ساخته نمیشوند. آنها بههمساخته—توسط محصول، مهندسی و هوش مصنوعی.
با DBModeler AI، این همکاری نهایتاً بدون دردسر است.
شروع به ساخت پایههای بهتر دادهها کنید—امروز.
This post is also available in Deutsch, English, Español, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 and 繁體中文.