













نوشته شده توسط تیم توسعه نرمافزار | مفاهیم کلیدی، دستورالعملها و نکات حرفهای برای طراحی پایگاه داده پشتیبانیشده از هوش مصنوعی
مقدمه: چرا طراحی پایگاه داده پشتیبانیشده از هوش مصنوعی اکنون مهم است
در توسعه نرمافزار مدرن، طراحی پایگاه داده همچنان یکی از مهمترین و بیشترین احتمال خطا را دارا، مراحل چرخه عمر است. طرحبندی ضعیف یک ساختار میتواند منجر به محدودیتهای عملکردی، ناسازگاری دادهها و بازسازی هزینهبر در آینده شود. با این حال، ابزارهای سنتی طراحی پایگاه داده اغلب نیازمند تخصص عمیق، رسم دیاگرام دستی و حدس و گمان تکراری هستند.
ورود DBModeler AI توسط Visual Paradigm: یک جریان کار هوشمند و راهنماییشده که نیازهای زبان طبیعی را به ساختارهای SQL استاندارد و آماده بهرهبرداری تبدیل میکند. این راهنما، از دیدگاه یک تیم توسعه نرمافزار با تجربه نوشته شده است و شما را از طریق قابلیتهای ابزار، بهترین روشها و نکات حرفهای هدایت میکند تا پایگاه دادههای قویتر را سریعتر، با اعتماد بیشتر و کمترین بار دستی بسازید.
چه شما مدیر محصولی باشید که ویژگی جدیدی را طراحی میکنید، یا مهندس بکاندی که معماری داده را بهینه میکنید، یا یک توسعهدهنده پیشبینیکننده مدل اولیه (MVP)، DBModeler AI فاصله بین منطق کسبوکار و پیادهسازی فنی را پر میکند—بدون اینکه کنترل یا دقت را از دست بدهید.
مفاهیم کلیدی برای تیمهای توسعه
🎯 هوش مصنوعی به عنوان یک طراح همکار، نه جایگزین
DBModeler AI تخصص شما را جایگزین نمیکند—بلکه آن را تقویت میکند. هوش مصنوعی وظایف تکراری (استانداردسازی، استنتاج کلیدها، تولید محدودیتها) را انجام میدهد در حالی که شما کنترل کامل ویرایشی بر روی دیاگرامها، کدهای SQL و مستندات را از طریق PlantUML و Markdown قابل ویرایش حفظ میکنید.
🔁 بهبود تکراری از طریق طراحی
جریان کار 7 مرحلهای به صورت قصدمند چرخهای است. شما میتوانید هر مرحلهای را دوباره بازبینی کنید، مدل را تنظیم کنید و داراییهای پاییندست را دوباره تولید کنید. این امر به توسعه آگیل و تغییرات نیازهای در حال تکامل کمک میکند.
🧪 تست کن قبل از انتشار
محیط یکپارچه حیاط بازی مشکل «کار میکند روی ماشین من» را از بین میبرد. رفتار ساختار را با استفاده از پرسوجوهای واقعی و دادههای نمونه تولیدشده توسط هوش مصنوعی، قبل از نوشتن هر خط کد برنامهنویسی، اعتبارسنجی کنید.
📐 استانداردسازی به عنوان ویژگی اولین رده
به جای اینکه استانداردسازی را به عنوان یک ایده پساز انجام در نظر بگیرید، DBModeler AI آن را به یک مرحله تعاملی و آموزشی تبدیل میکند—شما را به چرا و چگونه تکامل ساختار شما از 1NF → 2NF → 3NF را نشان میدهد.
🌐 مبتنی بر مرورگر، بدون بار نصب
همه چیز در مرورگر اجرا میشود. هیچ نمونه محلی PostgreSQL، تنظیم Docker، یا مشکلات وابستگی وجود ندارد. ایدهآل برای پروتوتایپسازی سریع، همکاری از راه دور و آموزش اعضای جدید تیم.
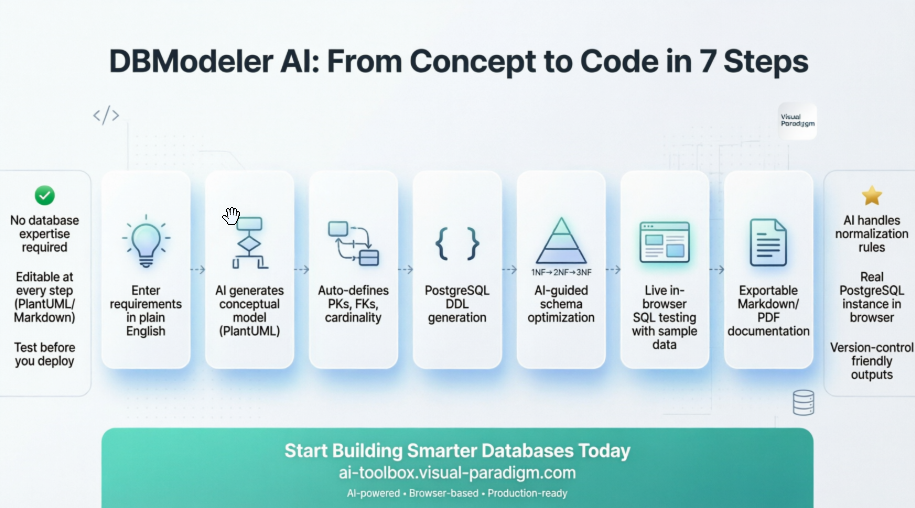
جریان کار هوش مصنوعی 7 مرحلهای: یک نگاه عمیق از دیدگاه توسعهدهنده
مرحله 1: ورودی مسئله (ورودی مفهومی)
هدف: تعیین محدوده پروژه و قوانین کسبوکار به صورت واضح.
-
اقدام:یک وارد کنیدنام پروژهو جزئیاتتوضیح مسئله (مثلاً«سیستمی برای مدیریت دروس دانشگاه، دانشجویان و ثبتنامها»). از تولیدکننده توضیحات هوش مصنوعی استفاده کنیدتولیدکننده توضیحاتبرای تهیه اولیه از یک پیشنهاد کوتاه.
-
نکته توسعهدهنده:از ابتدا به طور دقیق در مورد موجودیتها، روابط و محدودیتها صحبت کنید. مثال:«دانشجویان میتوانند در چندین درس ثبتنام کنند؛ هر درس یک مربی دارد؛ ثبتنامها نمرات و زمانهای ثبت را ردیابی میکنند.»
-
خروجی:زمانبندی ساختاریافته برای اینکه هوش مصنوعی مدلهای حوزهای دقیق تولید کند.
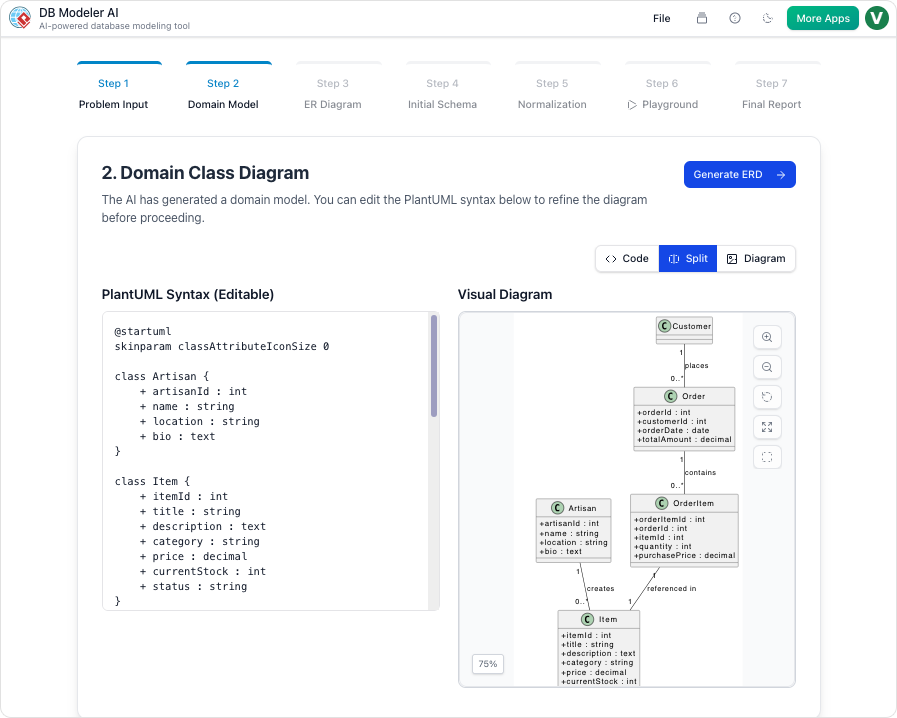
مرحله ۲: مدل حوزهای (مدلسازی مفهومی)
هدف: موجودیتها و روابط کسبوکار سطح بالا را به صورت بصری نمایش دهید.
-
اقدام:هوش مصنوعی یکنمودار مدل حوزهایبا استفاده ازسینتکس PlantUML، به صورت بصری نمایش داده میشود.
-
اصلاح:مستقیماً کد PlantUML را ویرایش کنید تا کلاسها را تغییر نام دهید، ویژگیها اضافه کنید یا ارتباطات را تنظیم کنید.
-
نکته توسعهدهنده:از قوانین نامگذاری یکدست استفاده کنید (مثلاً
PascalCaseبرای موجودیتها) از ابتدا استفاده کنید تا از بازسازی مجدد در آینده جلوگیری شود.
مرحله ۳: نمودار ER (مدلسازی منطقی)
هدف: مدلهای مفهومی را به ساختارهای آماده پایگاه داده ترجمه کنید.
-
اقدام: هوش مصنوعی مدل حوزه را به یک تبدیل میکندنمودار رابطهی موجودیت (ERD)، به صورت خودکار تعریف میکندکلیدهای اصلی (PKs)، کلیدهای خارجی (FKs)، وکاردینالیته (1:1، 1:N، N:M).
-
بهرهبرداری: کد PlantUML نمودار ERD را ویرایش کنید تا کلیدهای مرکب را اجباری کنید، شاخصها اضافه کنید یا نوع روابط را تنظیم کنید.
-
نکته توسعهدهنده: کاردینالیته را به دقت بررسی کنید—رابطههای به اشتباه تعریف شده منبع رایج پیچیدگی پرسوجوها و ناهنجاریهای دادهای هستند.
مرحله ۴: طرح اولیه (تولید کد فیزیکی)
هدف: کد SQL قابل اجرا و نصبشدن تولید کنید.
-
اقدام: ابزار خروجی کاملDDL PostgreSQL (
CREATE TABLEدستورات، ستونها و محدودیتها) که از نمودار ERD استخراج شدهاند. -
خروجی: اسکریپت طرح آماده اجرا برای تست محلی یا خطوط فرآیند CI/CD.
-
نکته توسعهدهنده: از DDL تولیدشده به عنوان پایهای برای اسکریپتهای مهاجرت (مثلاً با Flyway یا Liquibase) استفاده کنید.
مرحله ۵: استانداردسازی (بهینهسازی طرح)
هدف: حذف اضافهبودن و اجرای یکپارچگی دادهها.
-
اقدام:هوش مصنوعی به طور متوالی قوانین استانداردسازی را اعمال میکند و طرحبندی را از طریق1NF → 2NF → 3NFبا توضیحات تکمیلی.
-
بررسی:تغییرات طرحبندی را در هر مرحله مشاهده کنید؛ درک کنید که چرا جداول تقسیم میشوند یا کلیدها اضافه میشوند.چراجداول تقسیم میشوند یا کلیدها اضافه میشوند.
-
پاداش:هوش مصنوعینمونهای
INSERTدستوراتواسکریپتهای DMLبرای آزمون. -
نکته توسعهدهنده:به طور کورکورانه 3NF را قبول نکنید—گاهی اوقات نااستانداردسازی برای عملکرد توجیهپذیر است. از این مرحله براییادگیریملاحظات متقابل استفاده کنید.
مرحله 6: بازیگاه (اعتبارسنجی و آزمون)
هدف:رفتار طرحبندی را در یک محیط زنده و مستقل آزمایش کنید.
-
اقدام:یک نمونه PostgreSQL در مرورگر را راهاندازی کنیدنمونه PostgreSQL در مرورگربر اساس نسخه طرحبندی انتخابی شما (اولیه، 1NF، 2NF یا 3NF).
-
آزمون:
-
از هوش مصنوعی برایایجاد رکوردهای نمونه استفاده کنید (
"10 دانشجو با ثبت نام اضافه کنید") -
دادهها را به صورت دستی وارد یا فیلتر کنید
-
쿼ههای SQL سفارشی را اجرا کنید تا اتصالات، محدودیتها و عملکرد را اعتبارسنجی کنید
-
-
نکته توسعهدهنده:حالتهای لبه را به زودی آزمایش کنید: وقتی یک دانشجو تمام دروس را ترک کند چه اتفاقی میافتد؟ آیا یک مدرس میتواند همان درس را دو بار تدریس کند؟
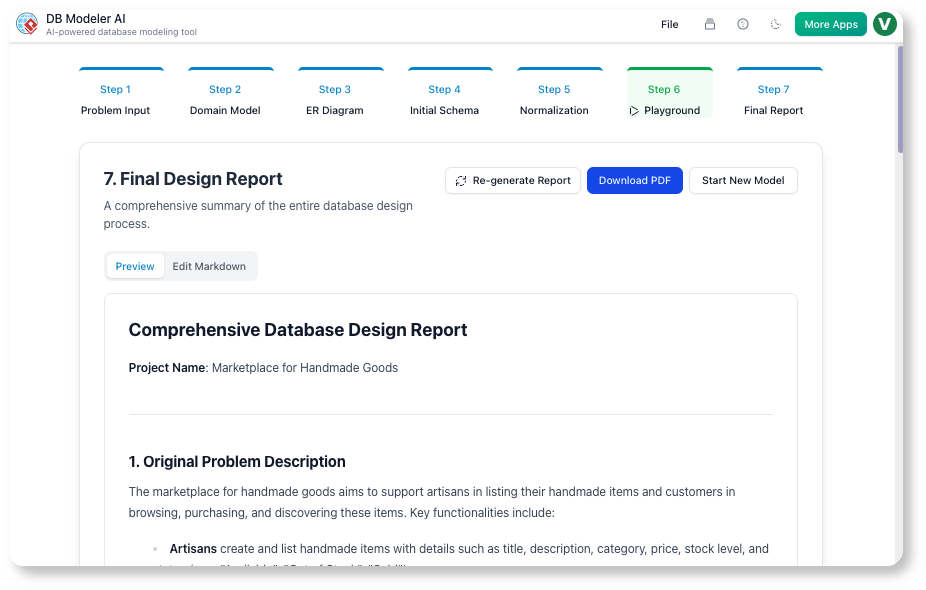
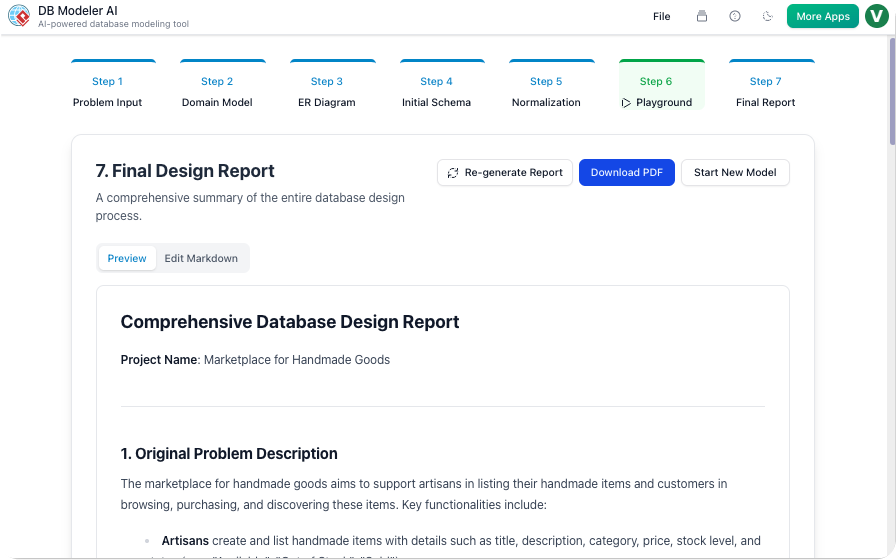
مرحله 7: گزارش نهایی (مستندات)
هدف:مستنداتی تعمیرپذیر و آماده برای تیم تولید کنید.
-
اقدام:ابزار یک گزارش طراحی نهایی در Markdown, شامل:
-
بیان مسئله
-
دیاگرامهای حوزه و ER
-
طرح نهایی 3NF
-
نمونه اسکریپتهای DML
-
-
بهرهبرداری:مستندات Markdown را به صورت مستقیم ویرایش کنید تا یادداشتهای معماری، قراردادهای API یا دستورالعملهای نصب اضافه شود.
-
خروجی:به صورت PDF یا JSON خروجی دهید تا برای ویکیها، Confluence یا انتقال به تیم DevOps استفاده شود.
راهنماییها و بهترین روشها برای استفاده در محیط تولید
✅ با نیازهای شفاف و اتمیک شروع کنید
-
حوزههای پیچیده را به مشکلات فرعی متمرکز تقسیم کنید (مثلاً طراحی «مدیریت کاربران» را قبل از «ارجاع سفارش» انجام دهید).
-
برای شفافیت از نقاط در توضیح مسئله استفاده کنید.
✅ در هر مرحله از ابزارهای ویرایشپذیر استفاده کنید
-
PlantUML و Markdown با کنترل نسخه سازگار هستند. ویرایشهای دیاگرام را همراه با کد به Git ارسال کنید.
-
از تفاوتها (diffs) برای ردیابی تحول ساختار پایگاه داده در طول اسپرینتها استفاده کنید.
✅ اعتبارسنجی با حجمهای واقعی دادهها
-
در محیط آزمایشی، صدها رکورد (نه فقط 10 عدد) تولید کنید تا عملکرد پرسوجوها و کارایی شاخصها را آزمایش کنید.
-
اگر برنامه شما نیاز به عملیات همزمان داشت، آن را شبیهسازی کنید.
✅ فرضیات را به صورت صریح مستندسازی کنید
-
در گزارش نهایی، بخشهایی مانند «تصمیمات طراحی» یا «محدودیتهای شناخته شده» را اضافه کنید تا ساختار پایگاه داده را برای نگهدارندگان آینده مفهومیتر کنید.
✅ ادغام با خط لوله CI/CD شما
-
DDL نهایی را اکспорت کنید و به عنوان پایه انتقال استفاده کنید.
-
برنامهریزی خودکار برای بررسی اعتبار ساختار پایگاه داده (مثلاً با
pglintیا اسکریپتهای سفارشی).
نکات و ترفند برای کاربران حرفهای
🔹 مهندسی پرامپت برای خروجی بهتر هوش مصنوعی
به جای «ساخت یک سیستم بلاگ», این کار را امتحان کنید:
*«طراحی یک ساختار PostgreSQL برای یک پلتفرم بلاگ چندکاربری که در آن:
-
هر کاربر (Tenant) دارای پستها و نظراتی منزوی است
-
پستها از برچسبها و انتشار برنامهریزی شده پشتیبانی میکنند
-
نظرات میتوانند تا سه سطح نهفته باشند
-
تمام جداول شامل
created_at/updated_atزمانهای ثبتشده»*
🔹 از کامنتهای PlantUML برای نظرات تیم استفاده کنید
' @team: این رابطه ممکن است نیاز به یک جدول واسط داشته باشد اگر حذف نرم اضافه کنیم
کاربر "1" -- "0..*" پست : مینویسد
🔹 صادر کردن زود، صادر کردن اغلب
در هر نسخه اصلی DDL و Markdown را دانلود کنید. این کار ردپایی برای بازبینی ایجاد میکند و در صورت نیاز، بازگشت به نسخه قبلی را سادهتر میکند.
🔹 با Visual Paradigm Desktop برای جریانهای کاری پیشرفته ترکیب شود
در حالی که ابزار وب طراحی و آزمون را مدیریت میکند، از Visual Paradigm Desktop برای:
-
معکوسسازی پایگاههای داده موجود
-
ایجاد نمودارهای ERD از نمونههای فعال PostgreSQL
-
صدور به چند دیالکت SQL (MySQL، SQL Server و غیره)
🔹 آموزش توسعهدهندگان جوان با مراحل نرمالسازی
از راهنمای تعاملی 1NF→3NF به عنوان ابزار آموزشی استفاده کنید. اعضای تیم را بخواهید قبل از افشای پیشنهاد هوش مصنوعی، مرحله بعدی نرمالسازی را پیشبینی کنند.
دسترسی، مجوزدهی و نکات ادغام
| جنبه | جزئیات |
|---|---|
| پلتفرم | بر پایه وب از طریق ابزارک Visual Paradigm AI |
| مجوزدهی | نیاز به Visual Paradigm Online Combo (یا بالاتر) یا Desktop Professional (یا بالاتر) با نگهداری فعال دارد |
| دیالکت SQL | خروجی اصلی: PostgreSQL; دیالکتهای دیگر ممکن است نیاز به نسخه دسکتاپ داشته باشند |
| فرمتهای صدور | SQL DDL، گزارش Markdown، PDF، JSON، منبع PlantUML |
| همکاری تیمی | فایلهای قابل ویرایش Markdown/PlantUML را از طریق Git به اشتراک بگذارید؛ از گزارش نهایی برای مستندات تحویل استفاده کنید |
| استفاده غیرفعال | نسخه وب نیازمند اینترنت است؛ نسخه دسکتاپ از مدلسازی آفلاین پشتیبانی میکند |
💡 نکته حرفهای: برای تیمهای سازمانی، در نظر داشته باشید که DBModeler AI را با Visual Paradigm’s سرور همکاری برای مدیریت نسخههای متمرکز مدل و کنترل دسترسی.
نتیجهگیری: توانمندسازی تیمها برای ایجاد پایههای داده بهتر
DBModeler AI تحولی در روش تیمهای توسعهدهنده در مواجهه با طراحی پایگاه داده ایجاد میکند. با ترکیب خودکارسازی پایهای هوش مصنوعی و کنترل متمرکز بر کاربر، زمان تولید اسکیما را کاهش میدهد، خطاهای طراحی را به حداقل میرساند و مدلسازی داده را در سطح تمام نقشها دسترسیپذیر میکند.
برای تیمهای نرمافزاری، ارزش آن فقط در پروتوتایپسازی سریعتر نیست—بلکه در ساخت معماریهای داده قابل نگهداری، بهخوبی مستند و قابل آزمون از اولین روز. راهبرد هفت مرحلهای راهنما مطمئن میشود که موارد حیاتی مانند استانداردسازی و اعتبارسنجی تحت فشار زمانی از دست نرود.
با ادامه تحول ابزارهای هوش مصنوعی، تیمهای موفقتر کسانی خواهند بود که از آنها به عنوان جعبههای سیاه استفاده نمیکنند، بلکه به عنوان شریکان همکار—توانمندسازی تخصص، شتاب بخشیدن به تکرار و ارتقای کیفیت کد. DBModeler AI Schritt قدرتمند در این جهت است.
آماده تبدیل پروژه پایگاه داده بعدی خود هستید؟
شروع به کار با DBModeler AI
منابع
- DB Modeler AI | ابزار طراحی پایگاه داده پایهای هوش مصنوعی توسط Visual Paradigm: صفحه رسمی ویژگیها که قابلیتها، موارد استفاده و گزینههای ادغام برای DBModeler AI را توضیح میدهد.
- تسلط به DBModeler AI توسط Visual Paradigm: آموزش جامع و گام به گام توسط یک خبره جامعه، که استراتژیهای اجرای عملی را پوشش میدهد.
- صفحه ابزار DBModeler AI: صفحه ورودی ابزار تعاملی با سوالات متداول، برجستهسازی ویژگیها و دسترسی مستقیم به تولیدکننده هوش مصنوعی.
- یادداشتهای انتشار DBModeler AI: یادداشتهای رسمی بهروزرسانی، اعلان ویژگیهای جدید و تاریخچه نسخهها از Visual Paradigm.
- مرور کلی تولیدکننده پایگاه داده DBModeler AI: خلاصهای مختصر از ارزش اصلی ابزار و راهبرد هفت مرحلهای آن.
- سیستم مدیریت بیمارستان با DBModeler AI: مطالعه موردی واقعی که طراحی پایگاه داده از ابتدا تا انتها در حوزه بهداشت و درمان را نشان میدهد.
- جعبه ابزار هوش مصنوعی Visual Paradigm – اپلیکیشن DBModeler AI: نقطه ورود مستقیم برای راهاندازی اپلیکیشن DBModeler AI مبتنی بر وب.
- راهنمای ویدیویی DBModeler AI: آموزش ویدیویی رسمی که رابط، جریان کار و ویژگیهای کلیدی را در عمل نشان میدهد.
- رها کردن تحلیلگر نمودار مورد استفاده هوش مصنوعی رایگان: زمینهای درباره اکوسیستم گسترده ابزارکاری هوش مصنوعی Visual Paradigm و دستورالعملهای دسترسی برای کاربران آنلاین.
- آموزش ادغام دسکتاپ: راهنمای ویدیویی درباره اتصال خروجیهای DBModeler هوش مصنوعی با دسکتاپ Visual Paradigm برای جریانهای پیشرفته صادرات و بازسازی معکوس.
This post is also available in Deutsch, English, Español, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 and 繁體中文.