













Диаграммы потоков данных (DFDS) представляют поток информации через систему. DFD быстро стали популярным способом визуализации основных шагов и данных, связанных с процессами программных систем.
Диаграмма потока данных (DFD) — это способ представления потока данных процесса или системы (обычно информационной системы), например:
- Откуда берутся данные?
- Куда это идет?
- Как это хранится?
Другими словами, он показывает, как данные обрабатываются системой с точки зрения входных и выходных данных с использованием методов нисходящей декомпозиции (или известной как пошаговое уточнение).
Что такое пошаговое уточнение?
Один из эффективных способов решения сложной проблемы — разбить ее на более простые подзадачи. Вы начинаете с того, что разбиваете всю задачу на более простые части.
Пошаговое уточнение, по сути, представляет собой декомпозицию системы для получения представления о подсистемах, составляющих систему, известный как метод декомпозиции сверху вниз.
Например, обзор системы разрабатывается как диаграмма контекста системы, которая определяет, но не определяет какой-либо уровень подсистемы. Затем каждая из этих подсистем уточняется до более подробной информации (например, уровни 0, 1, 2 и т. д. в DFD), иногда на многих дополнительных уровнях подсистемы, пока вся спецификация не сводится к базовым элементам.
Как это обычно бывает, результатом мозгового штурма стали идеи (на самом деле, пункты нашего списка дел), которые находятся на разных уровнях «детализации» — некоторые из них «ниже», чем другие, или, можно сказать, некоторые содержат другие.
Давайте расположим их иерархически. Другими словами, давайте определим, какие шаги являются частью другого шага. Один из способов сделать это — думать о каждом действии как о наборе действий.
Пример пошагового уточнения
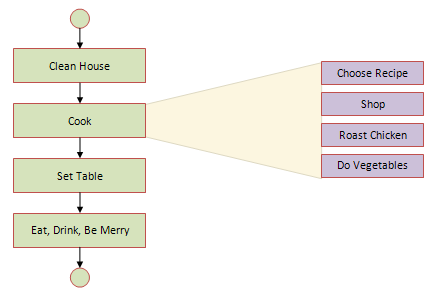
Чистый дом
{Пропылесосить столовую, Прибраться в гостиной}
повар
{Выберите рецепт, Магазин ингредиентов, Жареная курица. Делайте овощи}
Накрыть стол
{ Найдите скатерть , Достаньте тарелки , Выложите стеклянную посуду , Выложите столовое серебро , Салфетки }
Жареный цыпленок
{ Предварительно разогрейте духовку до 400 , положите курицу на сковороду , оставьте курицу в духовке 400 на 90 минут }
Вегетарианский
{ Нарезать овощи , Приготовить овощи }
(*Источник: Дизайн сверху вниз и пошаговая доработка — Викикниги )
Как только эти основные элементы определены, мы можем встроить их в компьютерные модули. Как только они будут построены, мы сможем собрать их вместе и сделать целую систему из этих отдельных компонентов.
Метод нисходящей декомпозиции в DFD
В DFD декомпозиция сверху вниз (также называемая выравниванием или пошаговым уточнением) — это метод, используемый для отображения более подробной информации в DFD более низкого уровня. Выравнивание выполняется путем рисования серии все более подробных диаграмм, пока не будет достигнута желаемая степень детализации. Как показано на рисунке, выравнивание DFD сначала отображает целевую систему как отдельный процесс, а затем показывает более подробную информацию, пока все процессы не станут функциональными примитивами.
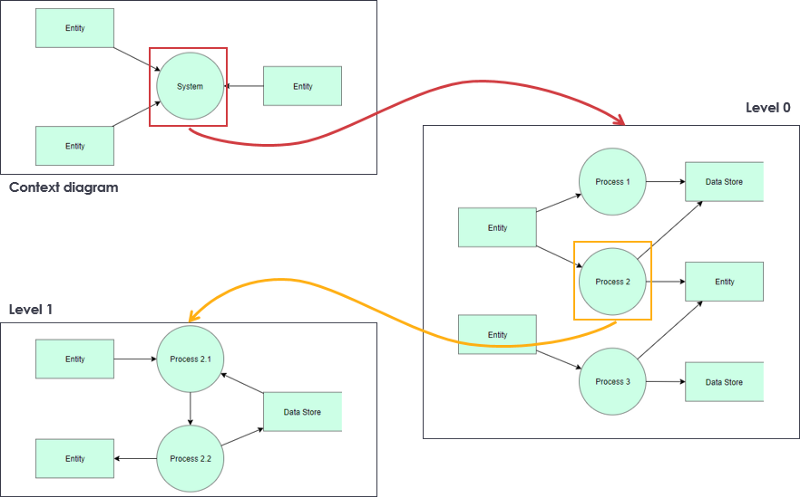
- DFD более высокого уровня менее детализированы
- DFD высокого уровня должны быть разложены на более подробные DFD более низких уровней
- Диаграмма контекста является самой высокой в иерархии (см. Правила создания DFD). За так называемым нулевым уровнем следует DFD 0, начиная с нумерации процессов (например, процесс 1, процесс 2).
- На следующем, так называемом первом уровне — DFD 1 — нумерация продолжается. Процесс EG 1 разделен на первые три уровня DFD, которые пронумерованы 1.1, 1.2 и 1.3.
- Точно так же процессы второго уровня (DFD 2) нумеруются, например, 1.1.1, 1.1.2, 1.1.3 и 1.1.4.
- Количество уровней зависит от размера модельной системы. Каждый из процессов уровня 0 может иметь разное количество уровней декомпозиции.
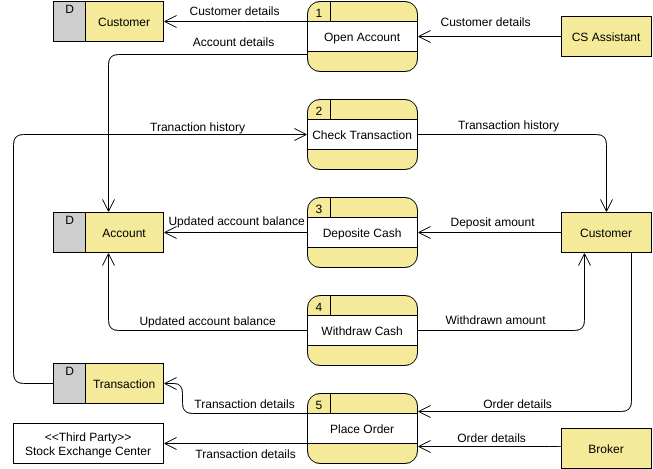
Примеры DFD — Пример системы обслуживания клиентов
Диаграмма потока данных представляет собой иерархию диаграмм, состоящую из:
- Диаграмма контекста (концептуально нулевой уровень)
- DFD уровня 1
- И возможный уровень 2 DFD и дополнительные уровни функциональной декомпозиции в зависимости от сложности вашей системы.
Контекстный DFD
На рисунке ниже показана контекстная диаграмма потоков данных, построенная для системы обслуживания клиентов железнодорожной компании. Он содержит процесс (форму), который представляет систему для моделирования, в данном случае « Система CS ». Он также показывает участников, которые будут взаимодействовать с системой, называемых внешними сущностями. В этом примере CS Assistant и Passenger — это два объекта, которые будут взаимодействовать с системой. Между процессом и внешними сущностями существует поток данных (коннекторы), который указывает на наличие обмена информацией между сущностями и системой.
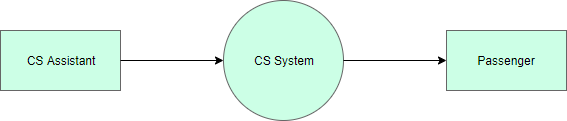
Отредактируйте этот пример Yourdon and Coad DFD
Context DFD — это вход в модель потока данных. Он содержит один и только один процесс и не показывает никакого хранилища данных.
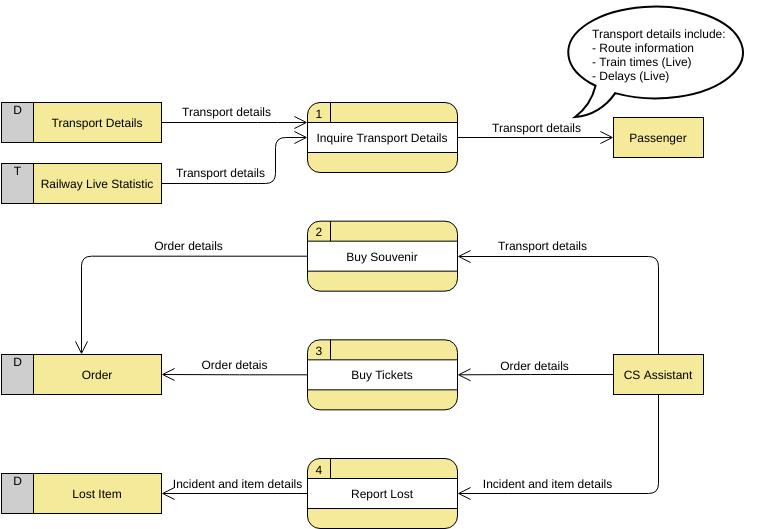
ДФД уровня 1
На рисунке ниже показан DFD уровня 1, который представляет собой декомпозицию (т. е. разбивку) процесса системы CS, показанного в контексте DFD. Прочтите диаграмму, а затем мы представим некоторые ключевые концепции, основанные на этой диаграмме.
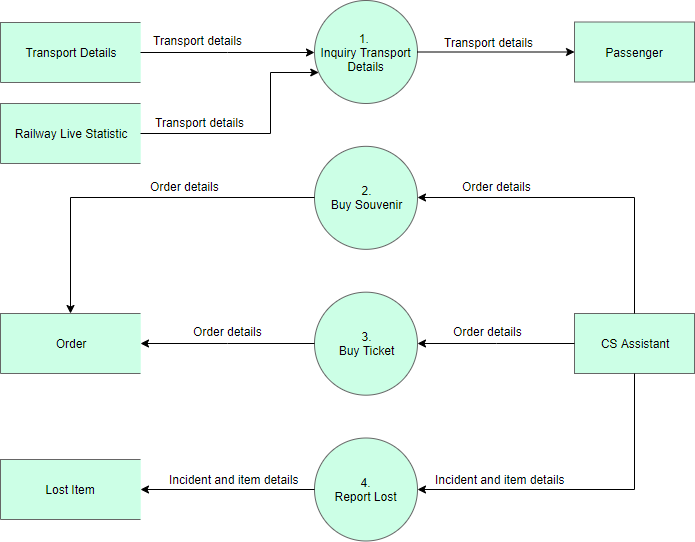
Отредактируйте этот пример диаграммы Yourdon и Coad
Пример блок-схемы системных данных CS содержит четыре процесса, два внешних объекта и четыре хранилища данных. Несмотря на отсутствие рекомендаций по проектированию, регулирующих расположение фигур на диаграмме потока данных, мы склонны размещать процессы посередине, а хранилища данных и внешние объекты — по бокам, чтобы упростить понимание.
Основываясь на диаграмме, мы знаем, что Passenger может получить сведения о транспорте из процесса « Запрос сведений о транспорте », а сведения предоставляются хранилищами данных « Сведения о транспорте » и « Железная дорога в реальном времени» . В то время как данные, хранящиеся в Сведениях о транспорте , являются постоянными данными (обозначаются меткой «D»), данные, хранящиеся в « Железной дороге в реальном времени» , представляют собой временные данные, которые хранятся в течение короткого времени (обозначается меткой «Т»). Форма выноски используется для перечисления деталей, которые могут быть запрошены пассажиром.
CS Assistant может инициировать процесс покупки сувенира , в результате чего детали заказа будут сохранены в хранилище данных заказов . Хотя покупатель является реальным лицом, покупающим сувениры, именно CS Assistant получает доступ к системе для хранения деталей заказа. Поэтому мы делаем поток данных из CS Assistant в процесс Buy Souvenir .
CS Assistant также может инициировать процесс покупки билета , предоставив детали заказа , и эти детали будут снова сохранены в хранилище данных заказов . Диаграмма потоков данных — это высокоуровневая диаграмма, нарисованная с высокой степенью абстракции. Хранилище данных Order, которое нарисовано здесь, не обязательно подразумевает реальную базу данных заказов или таблицу заказов в базе данных. Способ физического хранения сведений о заказе будет определен позже при внедрении системы.
Наконец, CS Assistant может инициировать процесс « Сообщить о потере », предоставив сведения об инциденте и предмете, и эта информация будет сохранена в базе данных потерянных предметов .
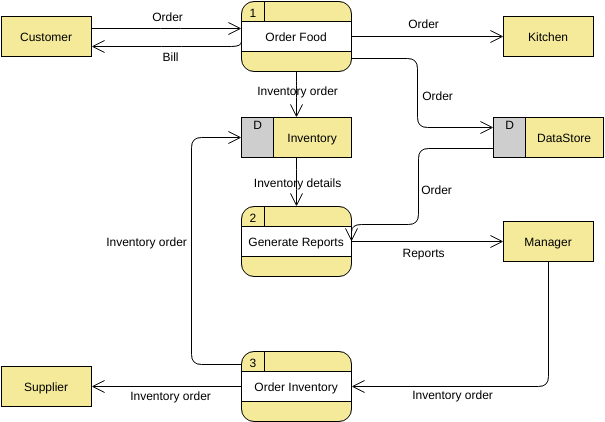
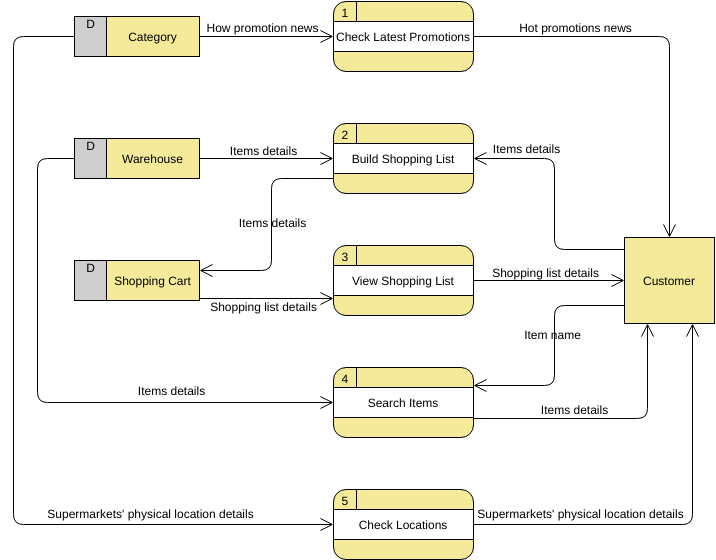
Узнайте больше о DFD на примерах
Эта статья также доступна на Deutsch, English, Español, فارسی, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Việt Nam, 简体中文 and 繁體中文