













Die Gestaltung eines robusten Geschäftsprozesses erfordert mehr als nur die Abbildung des idealen Szenarios. Während der „glückliche Pfad“ zeigt, wie ein Prozess funktioniert, wenn alles reibungslos verläuft, liegt die eigentliche Prüfung eines Systems darin, wie es mit dem Unvorhergesehenen umgeht. Im Kontext von Business Process Model and Notation (BPMN), ist die Behandlung von Ausnahmeabläufen entscheidend, um Integrität, Compliance und betriebliche Kontinuität zu gewährleisten. Dieser Leitfaden untersucht die Mechanismen der Fehlerbehandlung innerhalb der BPMN 2.0-Standards und stellt sicher, dass Ihre Prozessdiagramme sauber, logisch und widerstandsfähig bleiben.
🧩 Verständnis von Ausnahmeabläufen in BPMN
Ausnahmeabläufe stellen die alternativen Pfade dar, die ein Prozess nimmt, wenn eine bestimmte Bedingung von der Norm abweicht. Es handelt sich dabei nicht einfach um Fehlermeldungen, sondern um strukturierte Entscheidungen, die den zukünftigen Zustand einer Geschäftstransaktion bestimmen. Ohne eine korrekte Definition wird ein Prozessdiagramm brüchig und bricht bereits bei der ersten Anzeichen von Störung zusammen. Ein gut architekturierter Ausnahmeablauf stellt sicher, dass:
- Zustandskonsistenz: Der Prozess lässt Daten nicht in einem mehrdeutigen Zustand zurück.
- Sichtbarkeit: Stakeholder können genau sehen, wo und warum ein Prozess abwich.
- Wiederherstellung: Es existieren Mechanismen, um entweder den Fehler zu korrigieren oder den Prozess ordnungsgemäß zu beenden.
Beim Modellieren von Ausnahmen geht es um Klarheit. Ein Diagramm sollte die Frage beantworten können: „Was geschieht als Nächstes?“, selbst wenn Dinge schief laufen. Dazu ist ein tiefes Verständnis der spezifischen BPMN-Elemente erforderlich, die dazu gedacht sind, Unterbrechungen zu erfassen.
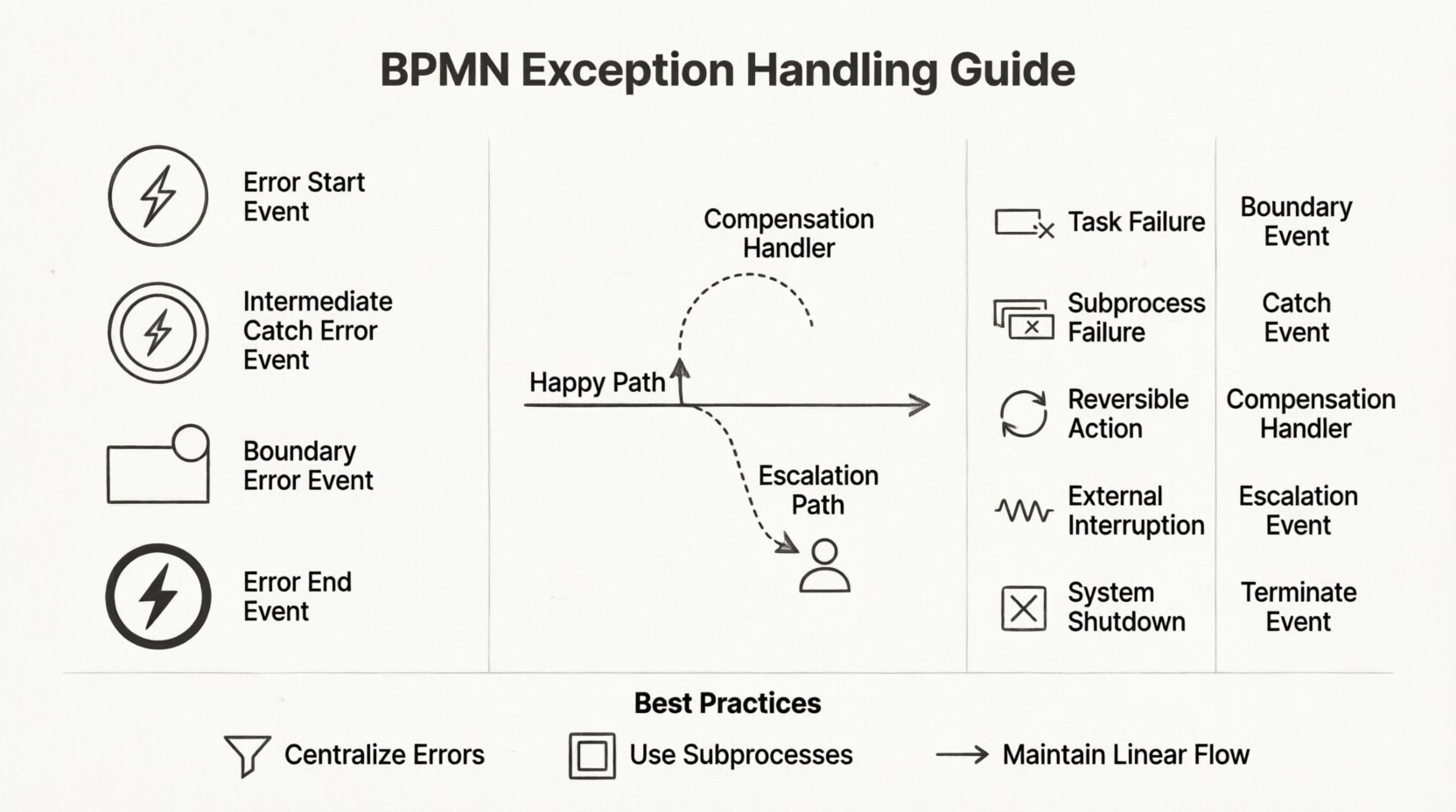
⚠️ Die Anatomie eines Fehlerereignisses
Fehler in BPMN unterscheiden sich von allgemeinen Nachrichten oder Signalen. Sie sind speziell dafür konzipiert, Systemausfälle, Validierungsfehler oder externe Störungen zu behandeln. BPMN definiert drei primäre Wege, um diese Fehler in einen Ablauf einzubinden:
1. Fehler-Start-Ereignisse
Ein Fehler-Start-Ereignis initiiert einen Prozess, der durch einen Fehler an einer anderen Stelle ausgelöst wird. Dies ist nützlich für Überwachungssysteme. Wenn beispielsweise ein Zahlungsgateway ausfällt, kann ein Fehler-Start-Ereignis einen Benachrichtigungsablauf auslösen, um das Finanzteam zu informieren. Es ermöglicht dem System, asynchron auf Fehler zu reagieren, ohne den primären Transaktionsablauf zu blockieren.
2. Zwischenzeitliche Fehler-Ereignisse (Fehler-Erfassung)
Diese Ereignisse pausieren einen Prozess, um auf eine Fehlerbedingung zu warten. Im Gegensatz zu einem standardmäßigen Zwischenzeitlichen Nachrichtenereignis, das auf Kommunikation wartet, wartet dieses auf ein spezifisches Fehler-Signal. Es wird häufig verwendet, um:
- Fehler zu erfassen, die aus Unterprozessen aufsteigen.
- Wiederholungslogik zu implementieren, indem man zurück zu einer vorherigen Aufgabe springt.
- Den Prozess zu einem spezialisierten Fehlerbehandlungsunterprozess umzuleiten.
3. Grenz-Fehler-Ereignisse
Dies ist möglicherweise die häufigste Methode zur Behandlung von Ausnahmen innerhalb einer Aufgabe. Ein Grenz-Fehler-Ereignis ist an der Grenze einer Aufgabe oder eines Unterprozesses angebracht. Wenn während der Ausführung einer bestimmten Aktivität ein Fehler auftritt, leitet der Ablauf sofort in den Pfad über, der mit dem Grenz-Fehler-Ereignis verbunden ist. Dadurch bleibt der Hauptablauf sauber, da die normale Logik unberührt bleibt, bis tatsächlich ein Fehler auftritt.
4. Fehler-End-Ereignisse
Wenn ein Fehler nicht wiederhergestellt werden kann, beendet ein Fehler-End-Ereignis die Prozessinstanz. Es ist entscheidend, festzulegen, welche Informationen in diesem Stadium erfasst werden. Metadaten zum Fehlercode oder zur Fehlermeldung sollten vor dem Schließen der Instanz protokolliert werden. Dadurch bleibt die Audit-Spur auch nach einem Prozessfehler intakt.
🔄 Kompensation: Rückgängigmachen von Aktionen
Nicht alle Ausnahmen erfordern die Beendigung. Manchmal muss ein Prozess rückgängig gemacht werden, um einen früheren Zustand wiederherzustellen. Hier kommen Kompensations-Handler ins Spiel. In BPMN ist Kompensation die Handlung, eine abgeschlossene Aktivität rückgängig zu machen. Dies ist entscheidend für Transaktionen, die Zahlungsabwicklungen, Bestandsaktualisierungen oder Dateneingaben betreffen.
Wenn ein Prozess einen Punkt erreicht, an dem ein vorheriger Schritt rückgängig gemacht werden muss, sollte das Modell eine Kompensationsgrenze definieren. Dazu gehört:
- Die spezifische Aktivität festlegen, die eine Rückgängigmachung erfordert.
- Den Kompensationsablauf festlegen, der die umgekehrte Aktion ausführt.
- Sicherstellen, dass der Kompensationsablauf idempotent ist (sicher, mehrmals ausgeführt zu werden).
Betrachten Sie einen Kreditgenehmigungsprozess. Wenn eine Kundenanfrage genehmigt wird, aber die anschließende Vertragsgenerierung fehlschlägt, muss der Genehmigungsstatus widerrufen werden. Ein Kompensationshandler stellt sicher, dass der Zustand „Genehmigt“ ohne manuelle Intervention auf „Ausstehend“ zurückgesetzt wird.
📊 Vergleich von Ausnahmehandhabungsstrategien
Die Auswahl des richtigen Mechanismus hängt von der Art des Fehlers ab. Die folgende Tabelle zeigt, wann bestimmte BPMN-Elemente zur Ausnahmeverwaltung verwendet werden sollten.
| Ausnahmetyp | BPMN-Element | Beste Anwendungsfalle |
|---|---|---|
| Aufgabenfehler | Grenzfehlerereignis | Bestimmte Aufgabe schlägt fehl, lokaler Neustart oder Warnung erforderlich. |
| Unterprozessfehler | Mittleres Erfassungsereignis (global) | Der gesamte Unterprozess schlägt fehl, eine hochrangige Reaktion ist erforderlich. |
| Rückgängigmachbare Aktion | Kompensationshandler | Müssen abgeschlossene Schritte nach einem späteren Fehler rückgängig machen. |
| Externe Unterbrechung | Eskalationsereignis | Erfordert menschliche Intervention oder Änderung einer externen Richtlinie. |
| System-Down | Beendigungsereignis | Der Prozess muss aufgrund eines kritischen Fehlers sofort beendet werden. |
🚨 Eskalationen im Vergleich zu Fehlern
Es ist wichtig, zwischen einem Fehler und einer Eskalation zu unterscheiden. Obwohl beide Abweichungen darstellen, dienen sie unterschiedlichen semantischen Zwecken.
- Fehler:Technische oder logische Fehler. Das System kann aufgrund einer defekten Bedingung nicht weiterlaufen (z. B. ungültiges Datenformat, fehlende Ressource).
- Eskalationen: Prozedurale oder managementbedingte Ausfälle. Der Prozess kann nicht fortgesetzt werden, da eine Bedingung menschliche Aufmerksamkeit oder eine Richtlinienüberschreitung erfordert (z. B. Genehmigungslimit überschritten, SLA-Verletzung).
Durch die Verwendung von Eskalationsereignissen können Sie den menschlichen Aspekt von Ausnahmen modellieren. Wenn eine Eskalation eintritt, kann der Prozess zu einer manuellen Aufgabe zur Überprüfung weitergeleitet werden. Dadurch bleibt die automatisierte Logik von der Entscheidungslogik getrennt und die Übersichtlichkeit des Diagramms wird erhalten.
🕸️ Vermeidung der „Spaghetti“-Falle
Eine der häufigsten Herausforderungen bei BPMN ist die visuelle Überlastung, die entsteht, wenn Ausnahmeströme hinzugefügt werden. Wenn jedes Task ein Grenzereignis hat, das zu einem anderen Endpunkt führt, wird das Diagramm unlesbar. Um die logische Integrität zu bewahren, ohne die visuelle Klarheit zu beeinträchtigen, beachten Sie diese strukturellen Prinzipien:
1. Zentralisierung der Fehlerbehandlung
Ersetzen Sie statt einzigartiger Pfade für jeden kleinen Fehler die Gruppierung ähnlicher Fehler. Wenn beispielsweise drei verschiedene Tasks alle aufgrund eines Datenbank-Timeouts fehlschlagen können, leiten Sie alle drei Grenzereignisse an einen einzigen „System-Fehlerbehandlungs“-Unterprozess weiter. Dadurch verringert sich die Anzahl der Linien, die das Diagramm kreuzen.
2. Verwenden Sie Unterprozesse für Komplexität
Wenn ein Ausnahmestrom mehrere Schritte umfasst (z. B. Protokollierung, Benachrichtigung, Wiederholung, Rückgängigmachen), kapseln Sie ihn in einen Unterprozess. Verunreinigen Sie das Hauptprozessdiagramm nicht mit den Details der Wiederherstellungslogik. Dadurch bleibt die Übersicht auf hoher Ebene sauber und Sie können nur bei Bedarf in die Fehlerbehandlung eindringen.
3. Halten Sie einen linearen Ablauf bei Gelegenheit aufrecht
Selbst bei Ausnahmen sollte der Prozess idealerweise einen linearen Ablauf vermitteln. Vermeiden Sie Schleifen, die zu weit in den Prozess zurückgehen. Falls eine Wiederholungsschleife notwendig ist, begrenzen Sie sie auf eine bestimmte Anzahl von Iterationen oder einen bestimmten Zeitraum. Unendliche Schleifen können dazu führen, dass der Prozess-Engine hängt oder übermäßige Protokolle generiert.
🛡️ Sicherstellung der Datenintegrität
Wenn eine Ausnahme auftritt, ist der Datenzustand oft die größte Gefahr. Ein Prozess könnte in Schritt 1 eine Datenbank-Datei aktualisiert, aber in Schritt 2 fehlschlagen. Wenn der Prozess beendet wird, bleibt diese Datei in einem halbfertigen Zustand. Um dies zu bewältigen:
- Definieren Sie Transaktionsgrenzen:Stellen Sie sicher, dass Aufgaben, die gemeinsam genutzte Daten aktualisieren, logisch gruppiert sind. Wenn eine Aufgabe fehlschlägt, sollte das System wissen, ob die damit verbundenen Datenänderungen rückgängig gemacht werden sollen.
- Protokollieren Sie den Ausnahmekontext:Wenn ein Fehler-Endereignis ausgelöst wird, stellen Sie sicher, dass die Prozessvariablen, die die Fehlerdetails enthalten, vor dem Ende der Instanz in ein dauerhaftes Protokoll gespeichert werden. Dies ist entscheidend für die spätere Fehlersuche.
- Verwenden Sie Nachrichtenkorrelation:Wenn der Prozess externe Systeme beinhaltet, verwenden Sie Korrelationschlüssel, um sicherzustellen, dass die Fehlermeldung der richtigen Prozessinstanz zugeordnet wird.
🧪 Testen von Ausnahmepfaden
Ein Prozessmodell ist nur so gut, wie seine Fähigkeit, die Realität zu bewältigen. Das Testen von Ausnahmeströmen erfordert einen anderen Ansatz als das Testen von Erfolgspfaden. Sie müssen Fehlerzustände simulieren.
Wichtige Test-Szenarien umfassen:
- Grenzbedingungen:Was passiert, wenn ein Feld leer ist? Was passiert, wenn eine Zahl negativ ist?
- Timeout-Szenarien:Was passiert, wenn ein System 30 Sekunden lang hängt?
- Gleichzeitige Ausfälle:Was passiert, wenn zwei Instanzen des Prozesses gleichzeitig versuchen, dieselbe Datensatz zu aktualisieren?
- Erfolgreiche Wiederherstellung:Wenn das System nach einem Fehler erneut versucht, wird der Prozess erfolgreich abgeschlossen, oder läuft er endlos in einer Schleife?
📝 Best Practices für die Wartung
Im Laufe der Zeit entwickeln sich Prozesse weiter. Die Anforderungen an die Ausnahmebehandlung ändern sich, wenn sich die Geschäftsregeln verschieben. Um Ihre BPMN-Modelle wartbar zu halten:
- Versionskontrolle: Verfolgen Sie immer Änderungen an der Ausnahmelogik. Eine Änderung in der Fehlerbehandlung kann die Compliance-Berichterstattung beeinflussen.
- Dokumentation: Fügen Sie Kommentare zu komplexen Grenzereignissen hinzu. Erklären Sie warum eine bestimmte Fehlerpfad existiert. Zukünftige Analysten könnten den geschäftlichen Kontext ohne diese Erklärung nicht verstehen.
- Standardisierung: Legen Sie Namenskonventionen für Fehlerereignisse fest. Verwenden Sie Codes (z. B. „ERR_001“) konsistent in allen Prozessen, um das Debuggen zu vereinfachen.
- Überprüfungszyklen: Überprüfen Sie regelmäßig die Ausnahmepfade. Gibt es Pfade, die nie eingeschlagen werden? Gibt es Pfade, die zu komplex sind? Vereinfachen Sie, wo möglich.
🔍 Häufige Fehler, die Sie vermeiden sollten
Selbst erfahrene Modelle können bei der Gestaltung von Ausnahmepfaden in Fallen geraten. Seien Sie sich dieser häufigen Fehler bewusst:
- Ignorieren stiller Fehler: Dass eine Aufgabe keine Ausnahme wirft, bedeutet noch lange nicht, dass sie erfolgreich war. Stellen Sie sicher, dass die Validierungslogik explizit ist.
- Übermäßiger Einsatz von Gateways: Verwenden Sie keine X-Gateways zur Fehlerbehandlung. Verwenden Sie stattdessen Fehlerereignisse. Gateways dienen der Logikverzweigung, nicht der Ausnahmeabfangung.
- Verwaiste Pfade: Stellen Sie sicher, dass jedes Grenzereignis eine klare Zielposition hat. Ein Fehler, der erfasst wird, aber nirgendwohin führt, ist eine Sackgasse.
- Mischen von Logiktypen: Mischen Sie keine Nachrichtenereignisse und Fehlerereignisse am selben Rand. Sie dienen unterschiedlichen Zwecken und können die Ausführungsmaschine verwirren.
🚀 Der Einfluss von widerstandsfähigen Prozessen
Die Entwicklung von Prozessen, die Ausnahmen effektiv handhaben, ist eine Investition in die betriebliche Stabilität. Wenn ein Prozess widerstandsfähig ist, verringert sich die Belastung für Support-Teams. Fehler werden automatisch erfasst, korrekt protokolliert und an die richtigen Handler weitergeleitet. Dies führt zu:
- Höhere Kundenzufriedenheit aufgrund kürzerer Wiederherstellungszeiten.
- Geringere manuelle Eingriffe bei Routineausfällen.
- Bessere Datenqualität, da Rückgängigmachungsmechanismen partielle Aktualisierungen verhindern.
- Sicherstellung der Compliance, da alle Fehlerzustände verfolgt und geprüft werden.
Indem Sie Ausnahmepfade als gleichberechtigte Elemente in Ihrer BPMN-Modellierung behandeln, schaffen Sie Systeme, die robust und zuverlässig sind. Das Ziel ist nicht, Fehler zu eliminieren, sondern sicherzustellen, dass der Prozess auch bei deren Auftreten weiter funktioniert oder kontrolliert beendet wird.
🏁 Letzte Überlegungen zur Logikintegrität
Eine effektive BPMN-Modellierung erfordert ein Gleichgewicht zwischen idealer Ablauflogik und realistischen Fehlern. Indem Sie Fehlerereignisse, Kompensationshandler und Eskalationsereignisse korrekt nutzen, können Sie Diagramme erstellen, die die wahre Komplexität der Geschäftsprozesse widerspiegeln. Denken Sie daran, dass Klarheit König ist. Ein Prozessmodell sollte auch dann verständlich sein, wenn es fehlschlägt. Konzentrieren Sie sich darauf, eine saubere Struktur aufrechtzuerhalten, Ihre Logik zu dokumentieren und Ihre Wiederherstellungspfade gründlich zu testen. Dieser Ansatz stellt sicher, dass Ihre Geschäftsprozesse in jedem Umfeld funktionsfähig und anpassungsfähig bleiben.
Der Artikel ist auch in English, Español, فارسی, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Ру́сский, Việt Nam, 简体中文 and 繁體中文 verfügbar.