













Модель потока данных — это интуитивно понятный способ показать, как система обрабатывает данные. На аналитическом уровне их следует использовать для моделирования того, как данные обрабатываются в существующих системах.
После публикации книги ДеМарко «Анализ структурированных систем» модель потока данных стала все более широко использоваться в анализе. Они являются неотъемлемой частью структурированного подхода, разработанного на основе этой работы. Символы, используемые в этих моделях, представляют обработку функций (прямоугольники со скругленными углами), хранение данных (прямоугольники) и перемещение данных между функциями (маркированные стрелки).
Почему DFD по-прежнему полезен для разработки программного обеспечения?
Хотя некоторые инженеры-программисты считают моделирование, ориентированное на поток данных , устаревшей технологией, оно по-прежнему остается одним из наиболее широко используемых символов анализа требований. Хотя диаграммы потоков данных (DFD) не являются формальными частями UML, их можно использовать для дополнения диаграмм UML и предоставления дополнительных сведений о системных требованиях и процессах.
Модель потока данных ценна тем, что отслеживание и запись того, как данные, относящиеся к конкретному процессу, перемещаются по системе, помогает аналитикам понять, что происходит. Преимущество диаграмм потоков данных состоит в том, что, в отличие от некоторых других символов моделирования, они просты и интуитивно понятны. Обычно их можно объяснить потенциальным пользователям системы, которые могут участвовать в анализе и проверке требований.
Почему ДФД?
DFD графически представляет функции или процессы, которые собирают, обрабатывают, хранят и распределяют данные между системой и ее средой, а также между компонентами системы. Визуальное представление делает его хорошим средством связи между пользователем и разработчиком системы. Структура DFD позволяет начать с общего обзора и расширить его до иерархии подробных диаграмм. DFD часто используется по следующим причинам:
- Логический информационный поток системы
- Определение требований к построению физической системы
- Простота обозначений
- Установление требований к ручным и автоматизированным системам
DFD — это процесс декомпозиции сверху вниз
Моделирование потока данных — это процесс «сверху вниз». Сначала проанализируйте весь процесс закупок. Затем подпроцессы анализируются методом нисходящей декомпозиции.
DFD можно использовать для моделирования систем или программного обеспечения на любом уровне абстракции. Как упоминалось ранее, DFD можно разделить на уровни, которые представляют возрастающий поток информации и функциональных деталей. Номера уровней в DFD: 0, 1, 2 или выше. Здесь мы увидим, что на диаграмме потока данных есть три основных уровня, а именно: DFD уровня 0, DFD уровня 1 и DFD уровня 2.
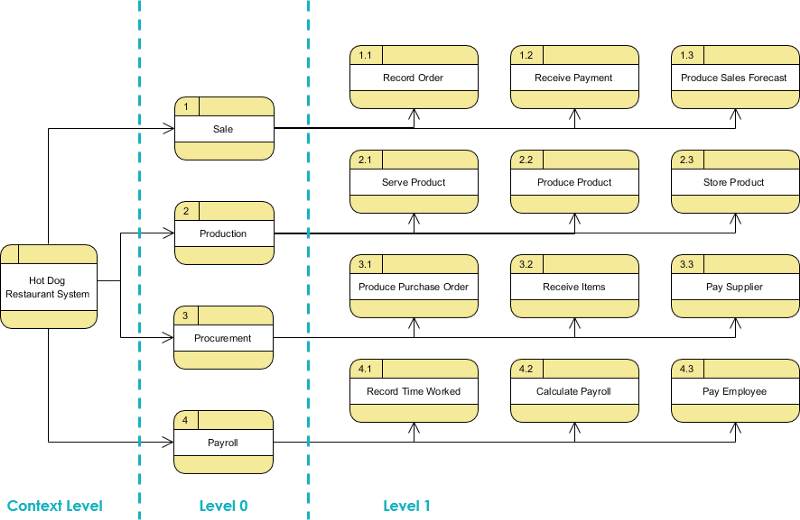
Контекстная диаграмма — уровни DFD
Контекстная диаграмма (также известная как DFD уровня 0) представляет все требования к программному обеспечению в виде пузырька, а входные и выходные данные представлены стрелками ввода и вывода.
Затем система разбивается на DFD с несколькими пузырьками. Части системы, представленные каждым кружком, затем разбиваются и записываются во все более подробные диаграммы потоков данных. Этот процесс можно повторять на необходимых уровнях до тех пор, пока программа не будет полностью понята.
Количество входов и выходов между уровнями должно поддерживаться, концепция, известная как выравнивание ДеМакро. Следовательно, если пузырек «А» имеет два входа X1 и X2 и один выход Y, то схема (диаграммы) потока данных подуровня, представляющая DFD «А» верхнего уровня, должна иметь ровно два внешних входа и один внешний выход.
В DFD 1-го уровня контекстная диаграмма разбивается на несколько процессов. На этом уровне мы выделяем основные функции системы и разбиваем высокоуровневый процесс DFD 0-го уровня на подпроцессы, чтобы дополнительно представить детали действий по обработке.
Контекстная диаграмма (уровень 0 DFD) — контекстная диаграмма DFD — это диаграмма, которая представляет обзор системы и ее взаимодействия с остальным «миром».
Диаграмма потока данных уровня 1 — DFD уровня 1 обеспечивает более подробное представление системы, чем контекстная диаграмма, показывая основные подпроцессы и хранилища данных, составляющие всю систему.
Уровень 2 (или ниже) — основное преимущество технологии моделирования потоков данных заключается в том, что подробной сложностью реальных систем можно управлять и моделировать на абстрактном уровне с помощью технологии, называемой «выравнивание». Некоторые элементы любой схемы потока данных могут быть декомпозированы («декомпозированы») в более детальную модель на более низком уровне в иерархии
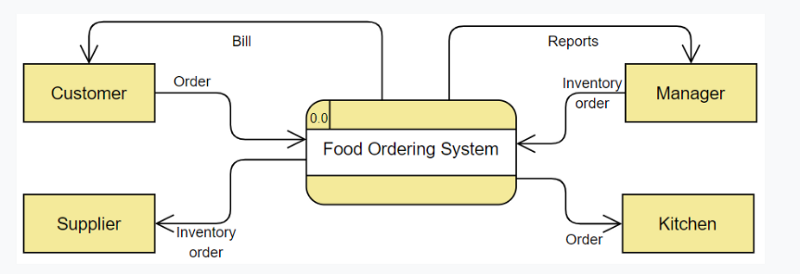
Уровни DFD — Пример — Система заказа еды
Уровень 0
Она также известна как контекстная диаграмма . Он разработан как абстрактное представление, показывающее систему как единый процесс с его отношениями с внешними объектами.
- Контекстная диаграмма должна умещаться на одной странице.
- Имя процесса на контекстной диаграмме должно быть именем информационной системы.
- Например, система оценок, система обработки заказов, система регистрации.
В DFD 1-го уровня контекстная диаграмма разбивается на несколько процессов. На этом уровне мы выделяем основные функции системы и разбиваем высокоуровневый процесс DFD 0-го уровня на подпроцессы, чтобы дополнительно представить детали действий по обработке.
Уровень 1 — Система заказа еды
В DFD 1-го уровня контекстная диаграмма разбивается на несколько процессов. На этом уровне мы выделяем основные функции системы и разбиваем высокоуровневый процесс DFD 0-го уровня на подпроцессы, чтобы дополнительно представить детали действий по обработке.
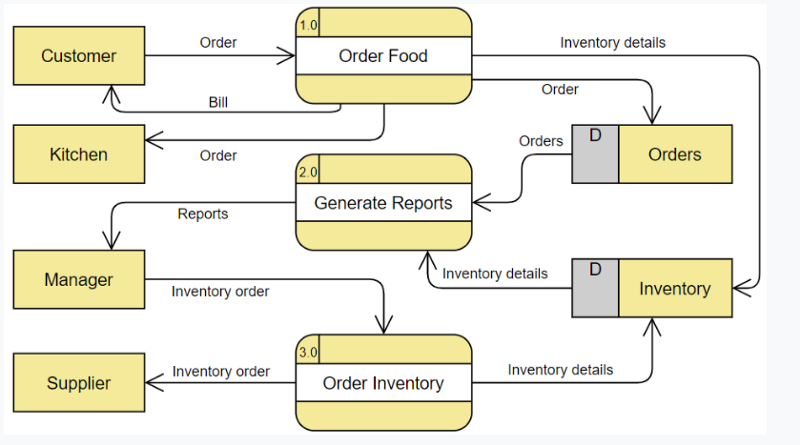
Если процесс с большим потоком данных связан между несколькими внешними объектами, мы могли бы сначала выделить этот конкретный процесс и связанные с ним внешние объекты в отдельную диаграмму, аналогичную контекстной диаграмме, прежде чем преобразовать процесс в отдельный уровень DFD; и таким образом вы можете обеспечить согласованность между ними намного проще.
ДФД-символы
Есть четыре основных символа , которые используются для представления диаграммы потока данных.
Обработать
Процесс получает входные данные и производит выходные данные с другим содержанием или формой. Процессы могут быть такими же простыми, как сбор входных данных и их сохранение в базе данных, или сложными, такими как создание отчета, содержащего ежемесячные данные о продажах всех розничных магазинов в северо-западном регионе.
У каждого процесса есть имя, определяющее выполняемую им функцию.
Имя состоит из глагола, за которым следует существительное в единственном числе.
Пример:
- Применить платеж
- Рассчитать комиссию
- Подтвердить заказ
Обозначение DFD
- Прямоугольник со скругленными углами представляет собой процесс
- Процессам присваиваются идентификаторы для удобства ссылок

Пример процесса
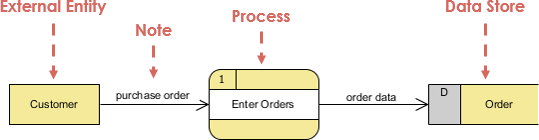
Поток данных
Поток данных — это путь, по которому данные перемещаются из одной части информационной системы в другую. Поток данных может представлять один элемент данных, такой как идентификатор клиента, или он может представлять набор элементов данных (или структуру данных).
Пример:
- Customer_info (фамилия, имя, номер SS, номер телефона и т. д.)
- Order_info (OrderId, Item#, OrderDate, CustomerID и т. д.).
Пример потока данных:
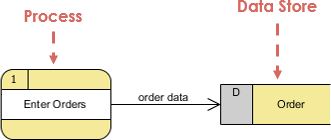
Обозначение
- Прямые линии с входящими стрелками — поток входных данных
- Прямые линии с исходящими стрелками — потоки выходных данных.
Обратите внимание, что:
Поскольку каждый процесс изменяет данные из одной формы в другую, по крайней мере один поток данных должен входить и один поток данных должен выходить из каждого символа процесса.
Хранилище данных
Хранилище данных или репозиторий данных используется в диаграмме потока данных для представления ситуации, когда система должна сохранить данные, потому что один или несколько процессов должны использовать сохраненные данные в более позднее время.
Обозначение
- Данные могут быть записаны в хранилище данных, которое показано отходящей стрелкой.
- Данные можно считывать из хранилища данных, которое показано входящей стрелкой.
- Примеры: запасы, дебиторская задолженность, заказы и ежедневные платежи.

Пример хранилища данных
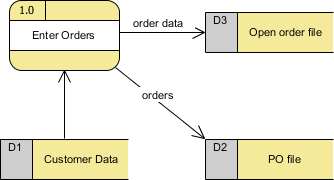
Обратите внимание, что:
- Хранилище данных должно быть подключено к процессу с потоком данных.
- Каждое хранилище данных должно иметь как минимум один входной поток данных и как минимум один выходной поток данных (даже если выходной поток данных является управляющим или подтверждающим сообщением).
Внешний объект
Внешний объект — это человек, отдел, внешняя организация или другая информационная система, которая предоставляет данные системе или получает выходные данные из системы. Внешние сущности — это компоненты, находящиеся за пределами информационных систем. Они представляют, как информационная система взаимодействует с внешним миром.
- Прямоугольник представляет внешний объект
- Они либо предоставляют данные, либо получают данные
- Они не обрабатывают данные
Обозначение
- Клиент отправляет заказ, а затем получает счет из системы
- Продавец выставляет счет

Пример внешнего объекта
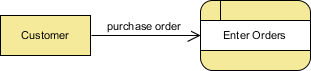
Обратите внимание, что:
- Внешние объекты также называются терминаторами, потому что они являются источниками данных или конечными пунктами назначения.
- Внешний объект должен быть подключен к процессу через поток данных.
Правило потока данных
Одно из правил разработки DFD заключается в том, что весь поток должен начинаться с этапа обработки и заканчиваться им. Это вполне логично, поскольку данные не могут трансформироваться сами по себе, будучи процессом. Используя эмпирическое правило, довольно легко идентифицировать незаконные потоки данных и исправить их в DFD.
Неверное/Правильное описание


Объект не может предоставлять данные другому объекту без какой-либо обработки.


Данные не могут перемещаться напрямую из сущности в историю данных без обработки.


Данные не могут перемещаться напрямую из хранилища данных без обработки.


Данные не могут перемещаться напрямую из одного хранилища данных в другое без обработки.
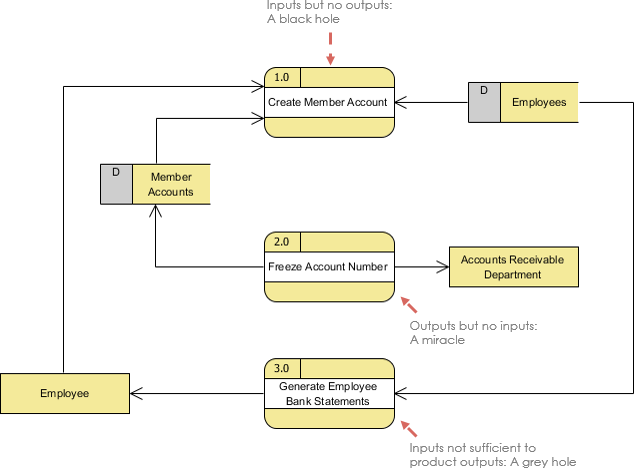
Другие часто допускаемые ошибки в DFD
Второй класс ошибок DFD возникает, когда выходные данные одного шага обработки не соответствуют его входным данным, и их можно классифицировать как:
- Черные дыры — шаг обработки может иметь входные потоки, но не выходные потоки.
- Чудеса. Шаг обработки может иметь выходные потоки, но не иметь входных потоков.
- Серые дыры — у шага обработки могут быть выходные данные, которые больше, чем сумма его входных данных.
Бесплатный инструмент UML
- Онлайн-конструктор диаграмм потоков данных
- Как создать диаграмму потока данных (DFD)?
- Программное обеспечение диаграммы потока данных (DFD)
DFD Другое обозначение
Эта статья также доступна на Deutsch, English, Español, فارسی, Français, English, Bahasa Indonesia, 日本語, Polski, Portuguese, Việt Nam, 简体中文 and 繁體中文