













该UML类图是系统结构的关键蓝图。它定义了核心数据实体(类)、它们的属性,以及它们之间的精确关系(关联、继承、多重性)。对于任何数据密集型应用,如图书馆管理系统,准确建模这些关系对于构建健壮且可扩展的数据库和代码库至关重要。
本案例研究展示了系统架构师如何使用Visual Paradigm AI聊天机器人快速从高层次概念过渡到复杂的面向对象模型,利用对话式指令来细化结构细节。
第一阶段:从构想到基础——初始提示
架构师从图书馆系统的根本实体开始。
初始AI提示:
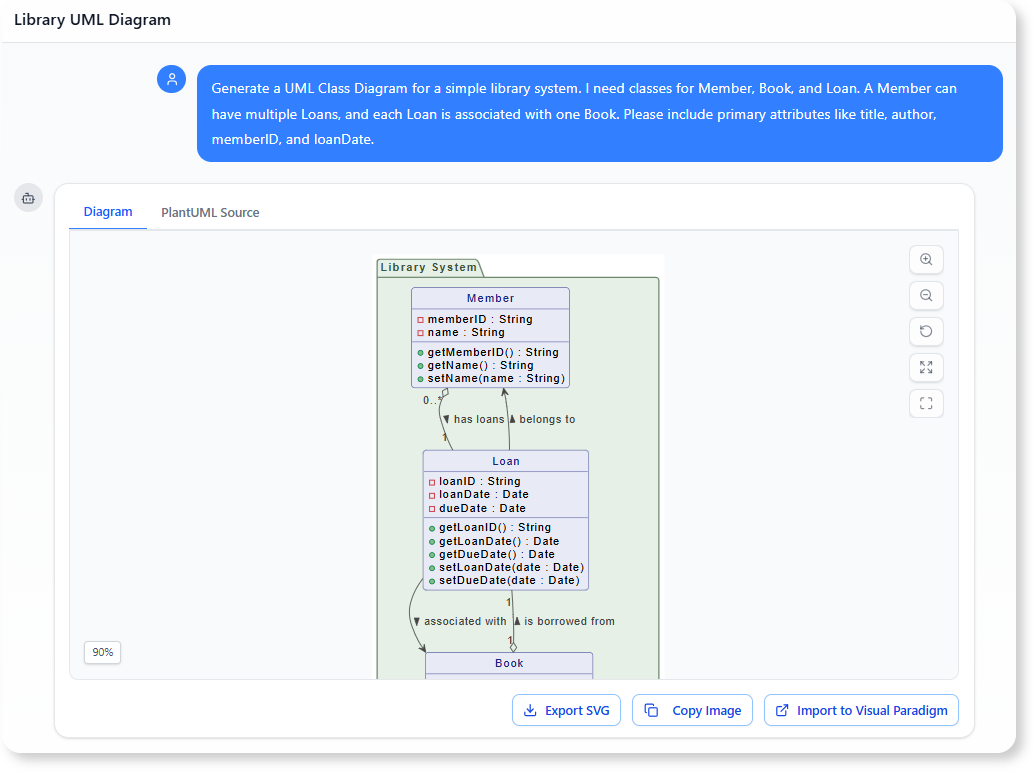
“为一个简单的图书馆系统生成一个UML类图。我需要以下类:会员, 书籍,以及借阅。一个会员可以有多个借阅记录,每个借阅记录与一本书相关联。请包含主要属性,如
书名,作者,会员ID,以及借阅日期.”
AI聊天机器人通过创建三个类及其基本关联来响应(例如,1..*在会员和借阅),立即定义了核心数据关系。值得注意的是,AI主动添加了isbn到图书和到期日期到借阅,提供了比最初请求更强大和完整的模型。
第二阶段:对话式优化——增加复杂性和继承
初始图示是可行的,但架构师认识到有两个必要的主要改进:增加继承用于媒体类型,并明确界定多重性约束用于业务规则。
优化提示:
- 引入继承:为了处理未来的媒体类型(DVD、杂志),设计需要一个抽象且可重用的结构。
“创建一个抽象类名为
LibraryItem。让两者图书和一个新类DVD,都继承自它。将公共属性isReserved: 布尔值移到父类LibraryItem.”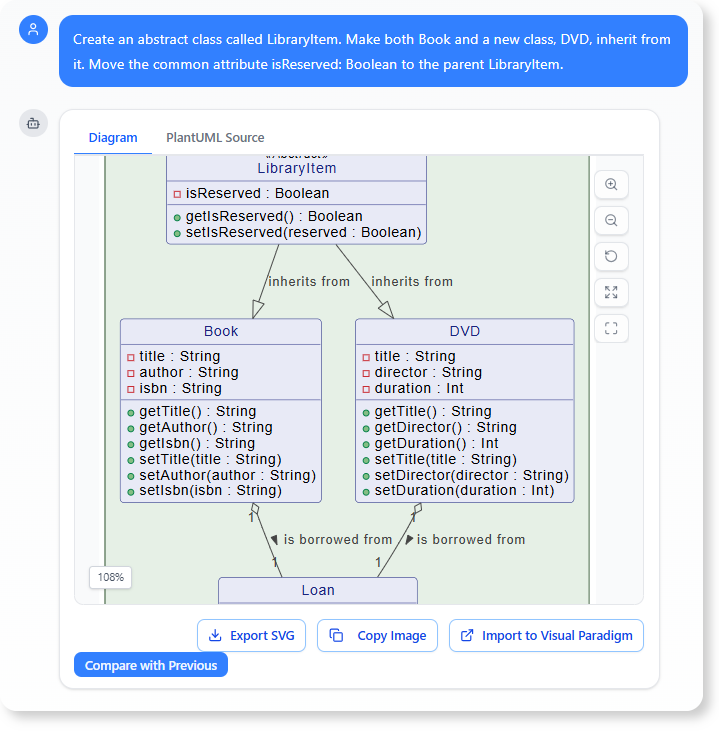
- 定义多重性约束(业务规则): 图书馆设定了明确的借阅限制。
“更新“
Member和Loan以反映最多借阅5件物品的限制。多重性应更新为每位成员最多5次借阅。”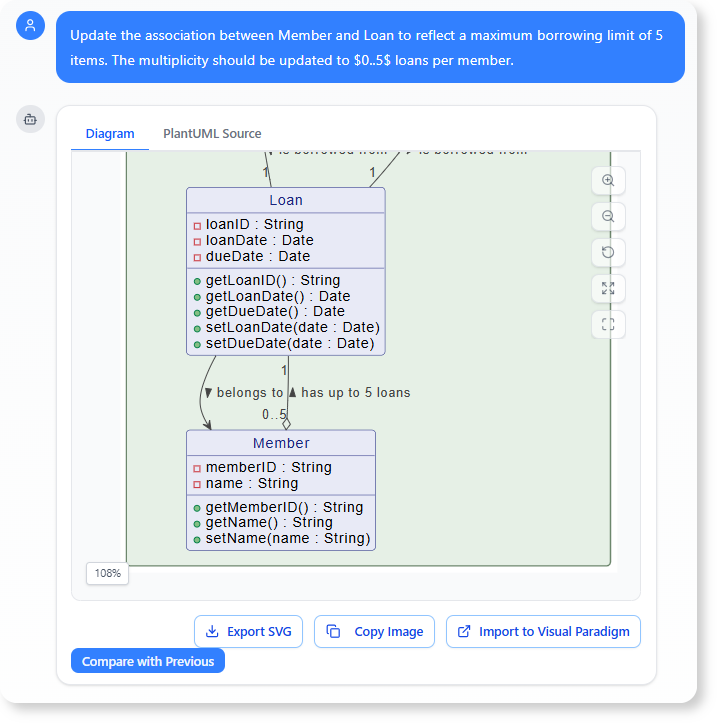
优势: 这展示了人工智能处理高级面向对象概念(如继承)的能力,并能根据简单的口头业务规则准确修改关键的多重性符号。该模型无需手动调整图表即可成为精确且符合规范的结构蓝图。
第三阶段:分析与实施——利用最终确定的图表
在结构模型确定后,类图成为下游文档任务的唯一真实来源。人工智能被用来直接将模型转换为关键项目文档.
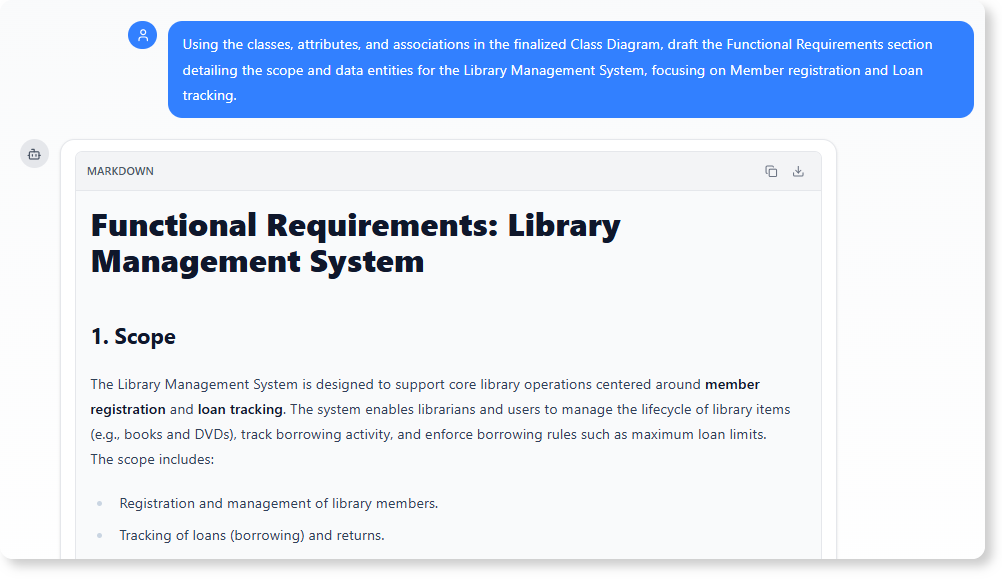
A. 生成功能需求文档(FRD)章节
类、属性和关联定义了系统的范围和功能。
分析提示:
“利用最终确定的类图中的类、属性和关联,起草功能需求章节,详细说明图书馆管理系统的范围和数据实体,重点在于会员注册和借阅跟踪。”
优势: 此任务可立即将视觉化的结构模型转化为FRD的正式章节,确保项目文档与已批准的设计蓝图保持一致。
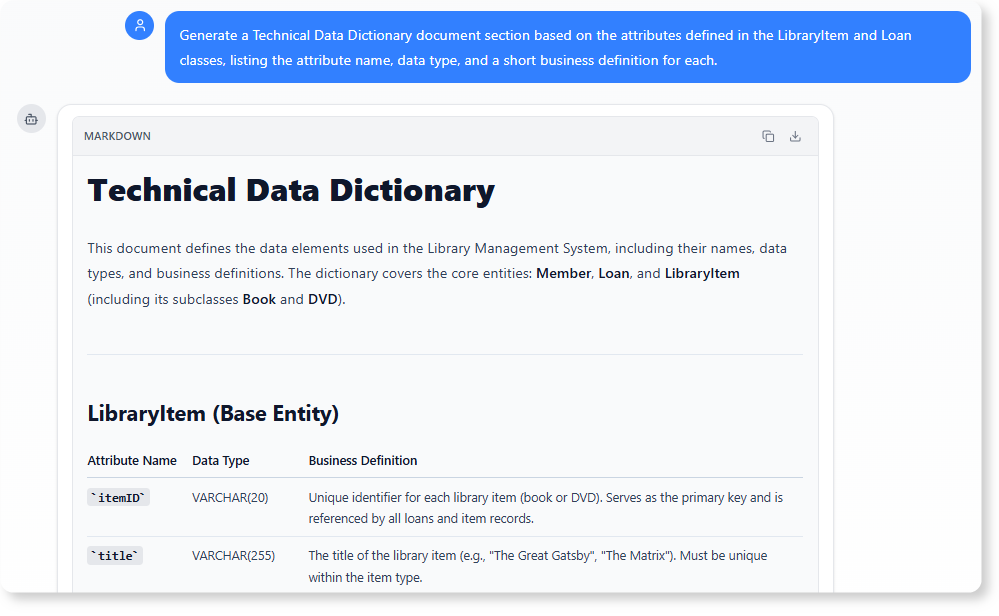
B. 生成技术数据字典
图表中定义的具体属性、数据类型和约束构成了系统技术规范的基础。
分析提示:
“生成一份技术数据字典文档章节,基于
LibraryItem和贷款类,列出每个属性的名称、数据类型以及简短的业务定义。”
优势: 人工智能提供了开发人员和数据库管理员所需的精确技术规格,利用直接在UML模型中定义的数据类型和名称,生成清晰且可直接实施的文档。
要了解有关UML及其人工智能驱动的可视化方法的更多信息,请访问我们的UML资源中心.