













数据库设计传统上是一项复杂的任务,需要在SQL、规范化规则和架构模式方面具备深厚的技术专长。然而,现代工具如DB Modeler AI正在彻底改变这一领域,使用户能够将自然语言描述转换为可投入生产的数据库模式。本全面指南详细介绍了DB Modeler AI的七步工作流程,提供关键概念、详细指南和实用技巧,以最大限度地提高您的数据库工程效率。
 关键概念
关键概念
在深入工作流程之前,必须理解支撑DB Modeler AI引擎的基础术语和技术。
- 自然语言处理(NLP):用于解析纯英文描述并将其转换为结构化技术需求的技术。
- 实体关系图(ERD):一种图形化表示,用于展示信息系统中人员、对象、地点、概念或事件之间的关系。
- PlantUML:一种开源工具,用于从纯文本语言创建图表,此处用于初始领域可视化。
- 规范化(1NF – 3NF):对数据库中的数据进行组织的过程。这包括根据旨在保护数据并消除冗余和不一致依赖关系以提高数据库灵活性的规则来创建表,并建立表之间的关系。
- DDL(数据定义语言):一种类似于计算机编程语言的语法,用于定义数据结构,尤其是数据库模式(例如,CREATE TABLE语句)。
指南:七步工作流程
DB Modeler AI的工作流程是从模糊的想法到成熟技术资产的结构化过程。遵循这些指南,以有效应对每个阶段。
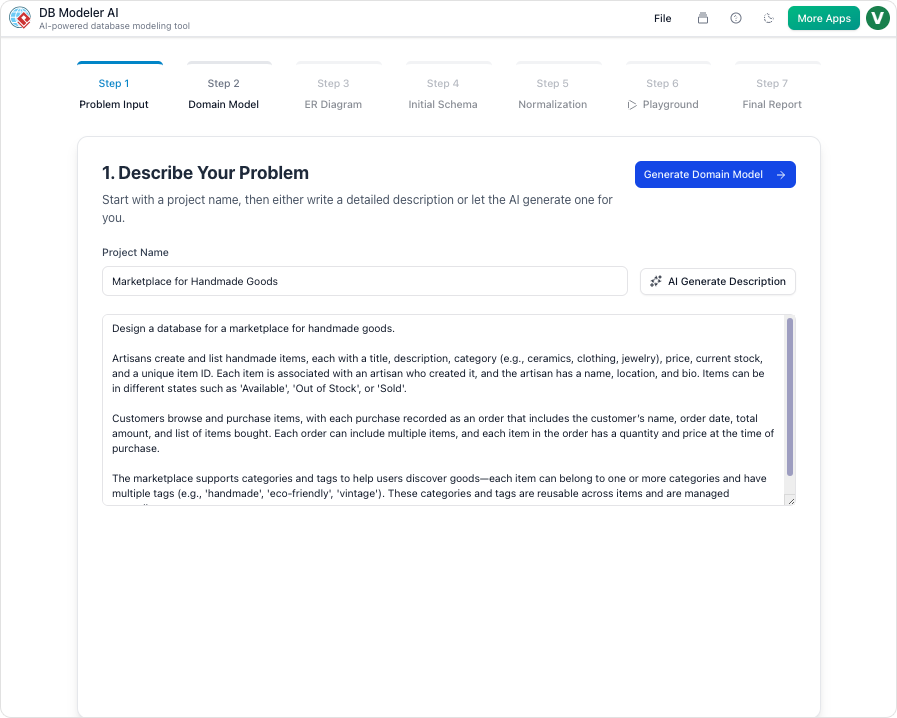
步骤1:问题输入与需求分析
该过程始于用户阐述其业务需求。与传统工具需要立即编写代码不同,此步骤接受纯英文。AI分析此输入以提取实体、属性和逻辑,并将其扩展为一组全面的技术需求。
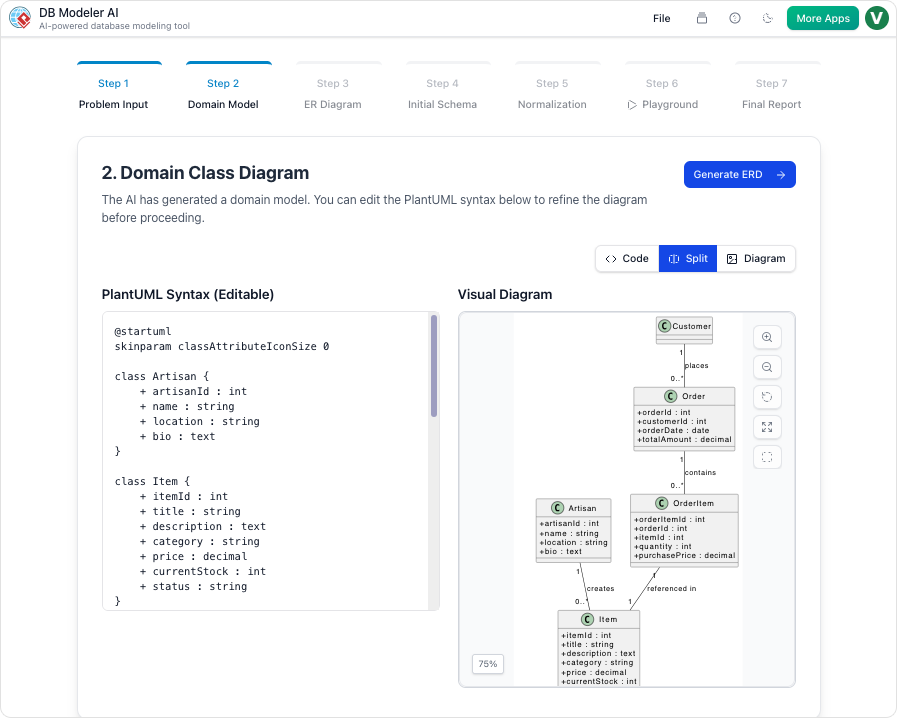
步骤2:领域类图可视化
一旦需求确定,系统将使用可编辑的PlantUML图。这在不陷入数据库特定细节的情况下,可视化高层对象及其属性。它作为结构蓝图。
步骤3:转换为ER图
概念模型随后被转化为一个严谨的实体关系图(ERD)。在此阶段,逻辑变得与数据库相关。系统定义主键、外键以及表之间的关系基数(例如,一对一、一对多、多对多)。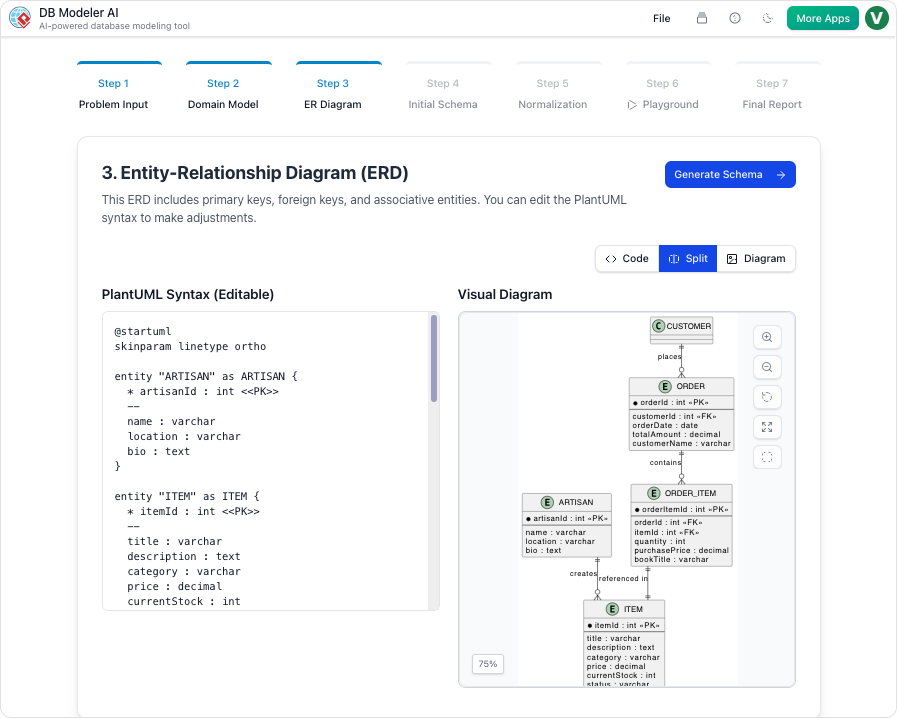
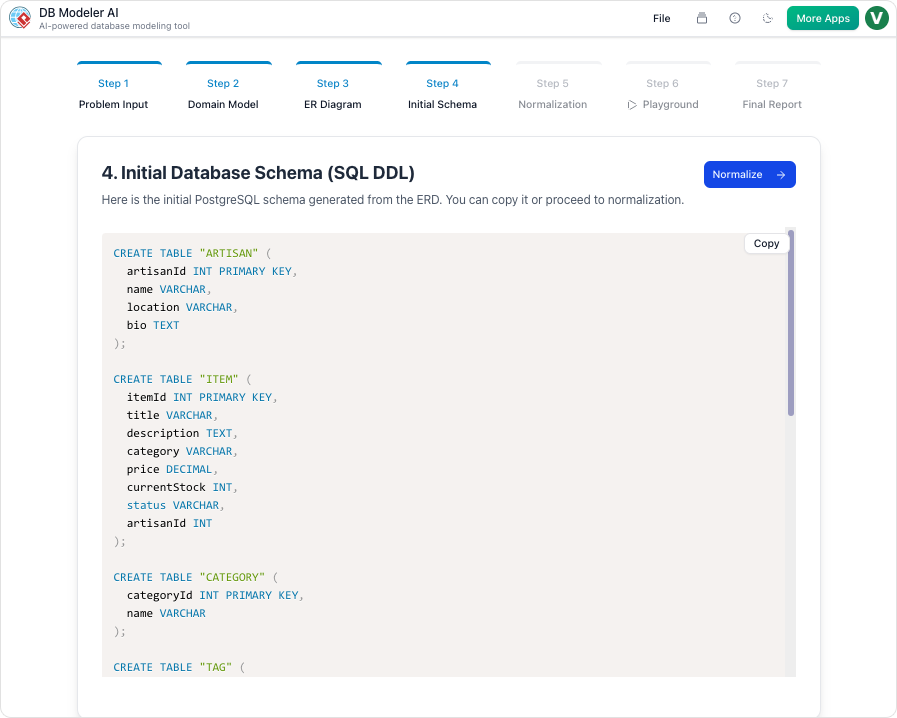
步骤 4:初始模式生成
在关系图确定后,平台将图表转换为可执行代码。它生成技术性与 PostgreSQL 兼容的 SQL DDL 语句。这些代码创建了实际的表和约束,构成了数据库的基础。
 步骤 5:智能规范化
步骤 5:智能规范化
最关键的步骤之一是模式的逐步优化。AI 将设计从第一范式(1NF)逐步提升到第三范式(3NF)。独特的是,该工具提供教育性解释以解释每次结构变更的原因,说明为何去除了数据冗余,或如何提升了数据完整性。
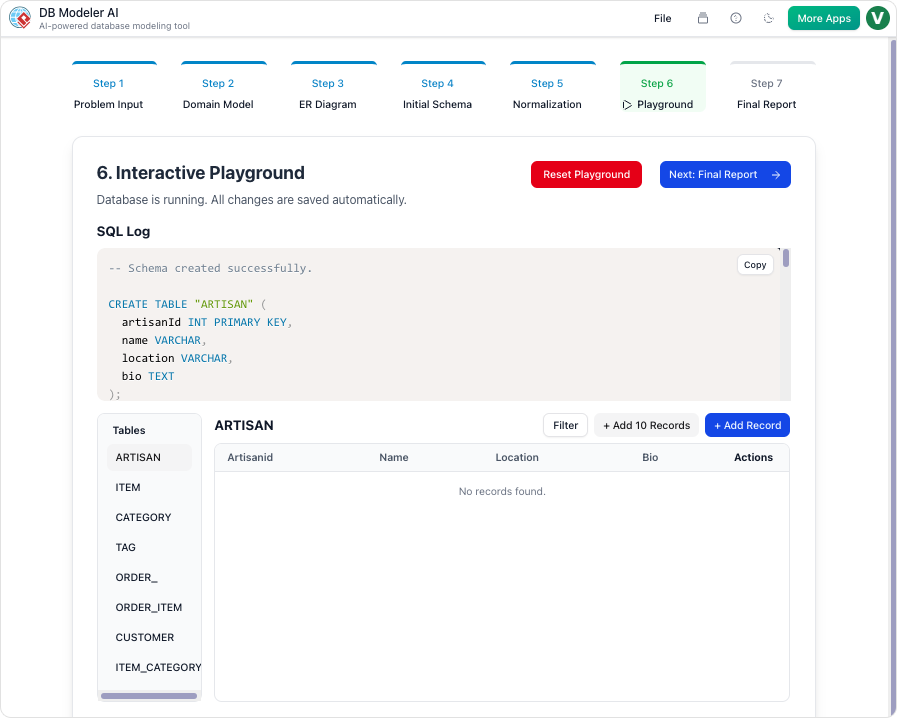
步骤 6:交互式沙盒
理论与实践在浏览器中的 SQL 客户端中结合。系统会自动使用逼真的 AI 生成示例数据来填充新模式。这使得用户可以立即编写查询并测试数据库逻辑,而无需手动填充表。
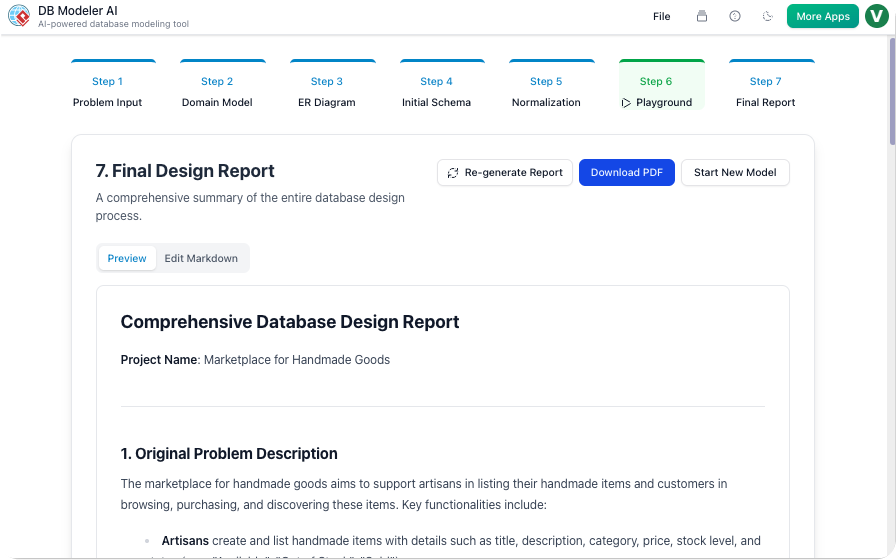
步骤 7:最终报告与导出
完成后,设计将被打包以供部署。平台将所有图表、技术文档和 SQL 脚本整合为精美的 PDF 或 JSON 格式。这确保了文档与代码实现完全一致。
技巧与窍门
为了最大限度地发挥 DB Modeler AI 的作用,建议采用以下优化策略:
- 在步骤 1 中要描述详尽: 输出质量在很大程度上取决于输入。请在您的自然语言描述中包含具体的业务规则(例如:“一个用户可以有多个地址,但只能有一个主地址”),以确保初始需求准确无误。
- 审查规范化解释:请不要跳过步骤 5 中提供的教育性说明。理解为何AI 会拆分一个表的原因,将有助于您未来维护数据库,并使您成为一名更优秀的数据库架构师。
- 在沙盒中进行压力测试:使用生成的示例数据运行复杂的 JOIN 查询。这有助于验证步骤 3 中定义的关系是否能够支持您未来对数据提出分析性问题。
- 迭代优化图表:由于步骤 2 中的 PlantUML 图表是可编辑的,可在该阶段捕捉结构错误,防止其变成 SQL 代码。修复图表比重构已填充的数据库要容易得多。
这是 DBModeler AI 的主产品落地页,清晰展示了其由人工智能驱动的功能,包括领域建模、ER 图、模式生成和实时 SQL 测试——使其成为首选之选。
此版本说明页面突出了 DBModeler AI 最近的更新和改进,非常适合希望了解该工具不断发展的功能的用户。
本指南全面探讨了 DBModeler AI 在专家指导、可视化绘图和实时 SQL 测试方面的整合——这些是用户评估其实际应用价值的关键方面。
尽管本教程并非 solely 关注 AI,但它展示了在托管 DBModeler AI 的平台 Visual Paradigm 中的实际数据库设计工作流程,为采用该工具的用户提供了宝贵的背景信息。
此免费工具页面突出了 Visual Paradigm 的 ERD 功能,这些功能是 DBModeler AI 功能的基础——使其成为对数据库建模基础感兴趣的用户的有用资源。