













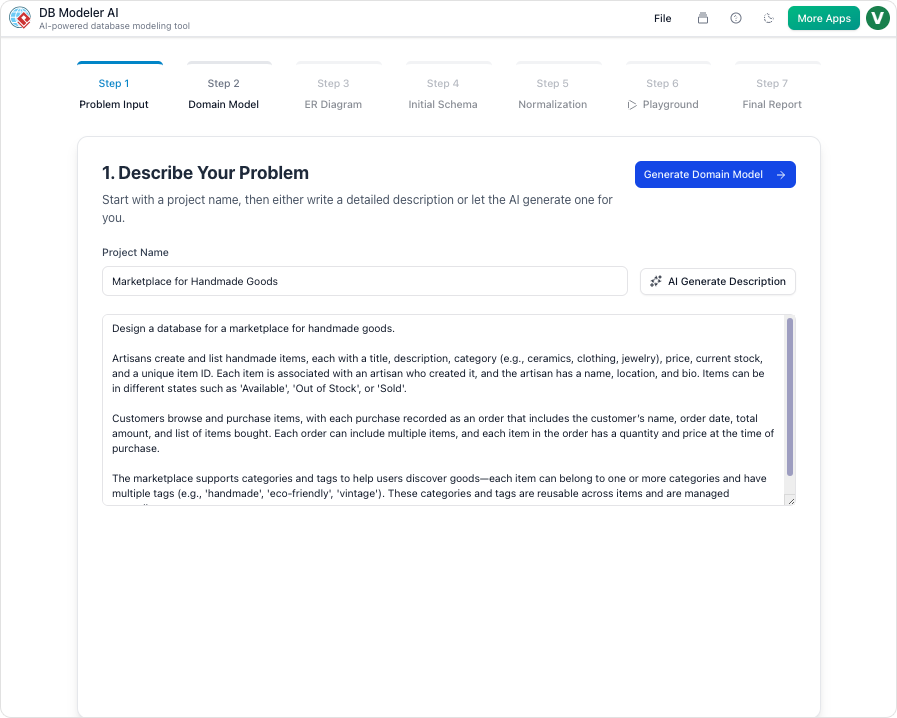
オブジェクト指向設計とリレーショナルデータベースの間の溝を埋める
ソフトウェア開発の複雑な領域において、概念的なアイデアから完全に機能的で効率的なデータベースシステムへと至るプロセスは、重要な道筋である。このプロセスは通常、いくつかの明確な段階を経る:オブジェクト指向構造を「クラス図」を用いてモデル化し、エンティティ関係図(ERD)」を通じてリレーショナルモデルを定義し、データベース正規化によってスキーマを最適化する。この順序は、アプリケーションの論理がデータストレージにスムーズに反映されることを保証し、開発者、アーキテクト、データ専門家の間の溝を埋める上で不可欠である。
しかし、これらの段階を手動で移行することは面倒で、誤りの原因になりやすい。Visual ParadigmのDBModeler AIは、この分野で変革的なツールとして登場した。人工知能を活用することで、自然言語やクラス構造を、堅牢で正規化されたデータベーススキーマに自動変換する。本ガイドでは、データベース設計の基本的な概念を解説し、AIツールが初期のクラス図から完全に正規化されたSQLデータベースへとワークフローを効率化する方法を示す。
システム設計の核心的な成果物
現代のツールが提供する自動化を理解するためには、まずシステムモデリングの基盤となる要素、すなわちクラス図、ERD、正規化を理解する必要がある。
1. クラス図:論理の設計図
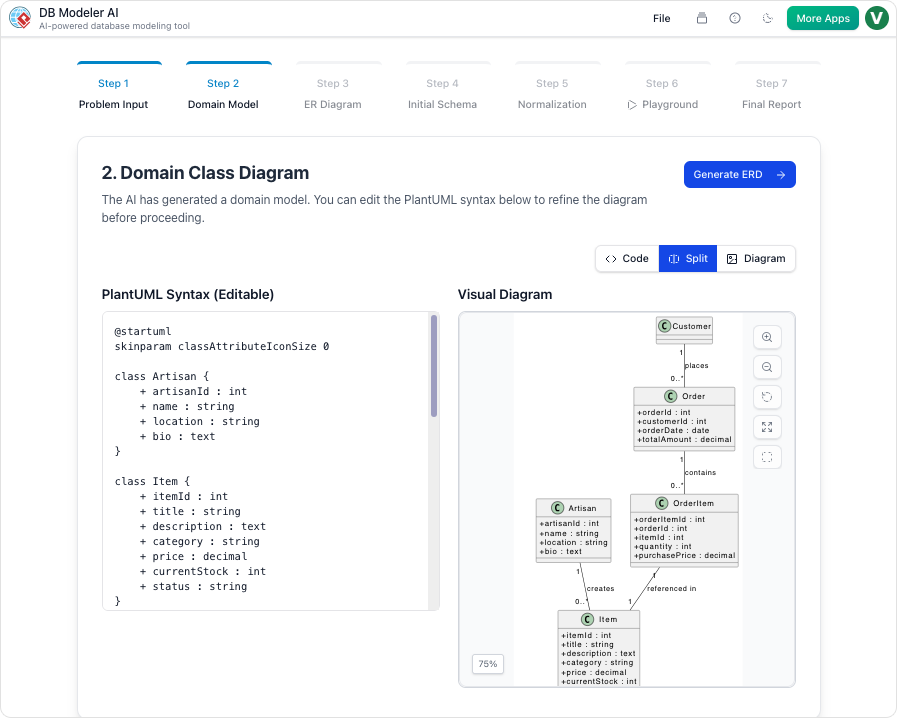
クラス図は「統一モデリング言語(UML)」の基本的な構成要素である。システムの静的構造を表し、「どのように」ではなく「何であるか」に焦点を当てる。オブジェクト指向設計において、クラス図はコード実装の設計図として機能する。
- クラス: ボックスとして表現され、例えば「学生」や「コース」などのエンティティを定義する。
- 属性と操作: 属性はプロパティ(例:「学生名」)を表し、操作は振る舞いやメソッド(例:「enroll()」)を定義する。
- 関係: クラスをつなぐ線は、オブジェクト間の相互作用を示し、継承、関連、集約、合成の記法を用いる。
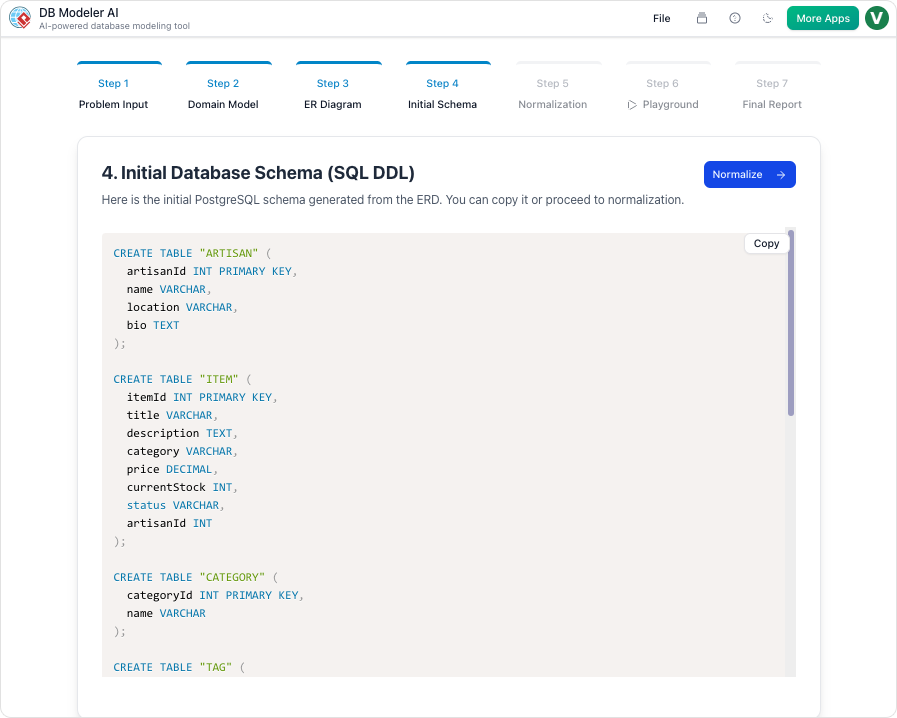
2. エンティティ関係図(ERD):データの視点
クラス図が振る舞いや構造に注目するのに対し、ERDはデータ保存にのみ焦点を当てる。ERDは「リレーショナルデータベースのモデリング.
- エンティティ: これらはデータベース内のテーブルになる(例:「学生」テーブル)。
- 属性: これらは列(主キー(一意の識別子)や外部キー(他のテーブルへの参照)を含む)になる。
- 基数: これはエンティティ間の数的関係を定義し、1対1、1対多、多対多などの関係を示す。
3. データベース正規化:整合性の確保
正規化は、データの冗長性を最小限に抑え、データ操作(挿入、更新、削除)中に異常を防ぐためにデータを整理する数学的手順です。大きなテーブルをより小さな関連するテーブルに分解することを含みます。
- 第一正規形(1NF):原子性(繰り返しグループなし)を確保し、主キーを定義します。
- 第二正規形(2NF):部分的依存関係を排除し、非キー属性が主キー全体に依存することを保証します。
- 第三正規形(3NF):推移的依存関係を排除し、非キー属性が他の非キー属性に依存する状況を防ぎます。
ワークフロー:コンセプトから最適化されたスキーマへ
従来のワークフローでは、論理の手動翻訳が必要です。開発者はドメインオブジェクトを捉えるためにクラス図を描きます。次に、この図をERDにマッピングし、テーブルとキーを作成します。最後に、ERDを正規形に基づいて検証し、構造を最適化します。たとえば、大学システムでは、「Student」クラスが単純な形から、登録情報や教員情報の処理を別々に扱うために複数のテーブルに進化することがあります。これは3NFを満たすためです。
Visual ParadigmのDBModeler AIによる設計の簡素化
Visual ParadigmのDBModeler AIは、自動化とインタラクティブ性を導入することで、この線形プロセスを革新します。ユーザーが平易な英語の記述から生産用のSQLスキーマまで導く包括的な7段階ワークフローをサポートしています。
AI駆動型生成
プロセスは自然言語から始まります。ユーザーは「大学の授業、学生、登録を管理するシステム」といった問題文を入力できます。AIはこれを解釈し、ドメインクラス図を生成PlantUML構文を使用して生成します。これにより、クラスとその関係の即時視覚的表現が得られ、編集可能な出発点となります。
スムーズなERD変換
最も強力な機能の一つは、クラス図からERDへの自動変換です。このツールはオブジェクト指向の構造をデータベースエンティティに変換し、主キーと外部キーを自動的に割り当て、基数を解決します。これにより、テーブルの描画テーブルの描画と線の接続という手作業を排除し、アーキテクトが論理構造に集中できるようにします。
インタラクティブな段階的正規化
おそらく最も教育的で実用的な機能は、段階的正規化ウィザードです。初期スキーマから始まり、DBModeler AIはデータベースを段階的に最適化します:
- 1NFの適用:繰り返しグループを特定し、分割します。
- 2NFの最適化:部分的依存関係を分離し、必要に応じて教員の詳細を汎用的な授業テーブルから移動します。
- 3NFの最適化:推移的依存関係を削除し、明確で効率的な構造を確保します。
重要なのは、このツールが各変更について説明を提供し、冗長性がなぜ削除されたか、または依存関係がどのように解決されたかを強調している点です。これにより、設計プロセスが学びの機会になります。
実践例:大学データベースの設計
実際にこのプロセスを確認するため、大学管理システムの作成を検討してみましょう:
- 入力:ユーザーは要件を次のように記述します:「学生は教員が担当する授業に登録し、成績が記録される。」
- クラス図:AIは、Student(ID、名前)、Course(ID、タイトル)、Enrollment(成績)のクラスを含む図を生成し、適切な関連付けでそれらをリンクします。
- ERD変換:システムはクラスをエンティティに変換します。学生とコースの多対多関係は、外部キーを持つ中間エンティティ(Enrollment)を作成することで処理されます。
- 正規化:初期のデータモデルで教員の住所がCourseテーブル内にネストされている場合、AIは推移的依存関係を検出し、3NFを達成するためにそれを「教員」または「部署」テーブルに分離することを提案します。
- テスト:ユーザーはその後、ブラウザ内SQLプレイグラウンドにアクセスできます。AIはサンプルデータでデータベースを初期化し、ユーザーがクエリを実行して設計を即座に検証できるようにします。
効果的なデータベースモデリングのガイドライン
AIアシストによるデータベース設計の可能性を最大限に引き出すには、データベース設計以下のベストプラクティスに従ってください:
- シンプルに始める:簡潔な自然言語による記述から始めましょう。AIの初期出力に基づいて、段階的にモデルを改善できます。
- テキストベースの編集を活用する:素早い調整にはPlantUML構文を使用しましょう。図がテキストベースであるため、コピー・ペーストや構造の編集がドラッグアンドドロップよりも迅速です。
- 「なぜ」を確認する:正規化の過程でのAIの説明に注意を払いましょう。テーブルを分離する理由を理解することで、将来の設計上の落とし穴を回避できます。
- 徹底的にテストする:組み込みのSQLプレイグラウンドを使用しましょう。AIが生成したサンプルデータに対してクエリを実行することで、静的図では見えない構造上の問題が明らかになります。
- 3NFを目指す:ほとんどの汎用アプリケーションにおいて、第三正規形はデータ整合性とパフォーマンスの最適なバランスを提供します。特定のパフォーマンス指標が要求する場合を除き、非正規化は行わないでください。
結論
クラス図を正規化されたデータベースに変換することは、信頼性の高いソフトウェアシステムを構築するための基盤となるスキルです。UML、ERD、正規化の概念は時代を超えて変わらないものの、それらを実装するためのツールは急速に進化しています。Visual ParadigmのDBModeler AIは、概念設計と物理的実装の間の橋渡しを果たし、プロセスに知性と自動化をもたらします。手動での図の描画や計算の煩わしさを減らすことで、学生や専門家がイノベーションとアーキテクチャに集中できるようにし、最終的なデータベースが堅牢かつスケーラブルであることを保証します。クラス図関連リソース