













データベース設計は伝統的に、SQL、正規化ルール、アーキテクチャパターンに関する深い技術的専門知識を要する複雑な作業であった。しかし、現代のツールであるDB Modeler AIは、ユーザーが自然言語の記述を本番環境対応のスキーマに変換できるようにすることで、この分野を革新しています。この包括的なガイドでは、DB Modeler AIの7ステップワークフローを詳細に解説し、重要な概念、詳細なガイドライン、実用的なヒントを提供することで、データベースエンジニアリングの効率を最大化します。
 主要な概念
主要な概念
ワークフローに取り組む前に、DB Modeler AIエンジンを支える基盤となる用語と技術を理解することが不可欠です。
- 自然言語処理(NLP):平易な英語の記述を解釈し、構造化された技術的要件に変換するために使用される技術。
- エンティティ関係図(ERD):情報システム内の人物、物、場所、概念、または出来事の間の関係を視覚的に表現するもの。
- PlantUML:平易なテキスト言語から図を生成するために使用されるオープンソースツールであり、ここでは初期のドメイン可視化に利用されている。
- 正規化(1NF ~ 3NF):データベース内のデータを整理するプロセス。テーブルの作成と、それらのテーブル間の関係の確立を、データを保護し、冗長性や一貫性のない依存関係を排除することでデータベースの柔軟性を高めるために設計されたルールに従って行う。
- DDL(データ定義言語):データ構造、特にデータベーススキーマ(例:CREATE TABLE文など)を定義するための、コンピュータプログラミング言語に似た構文。
ガイドライン:7ステップワークフロー
DB Modeler AIのワークフローは、曖昧なアイデアから完成度の高い技術的資産へと至る構造化されたプロセスです。各段階を効果的に進めるために、以下のガイドラインに従ってください。
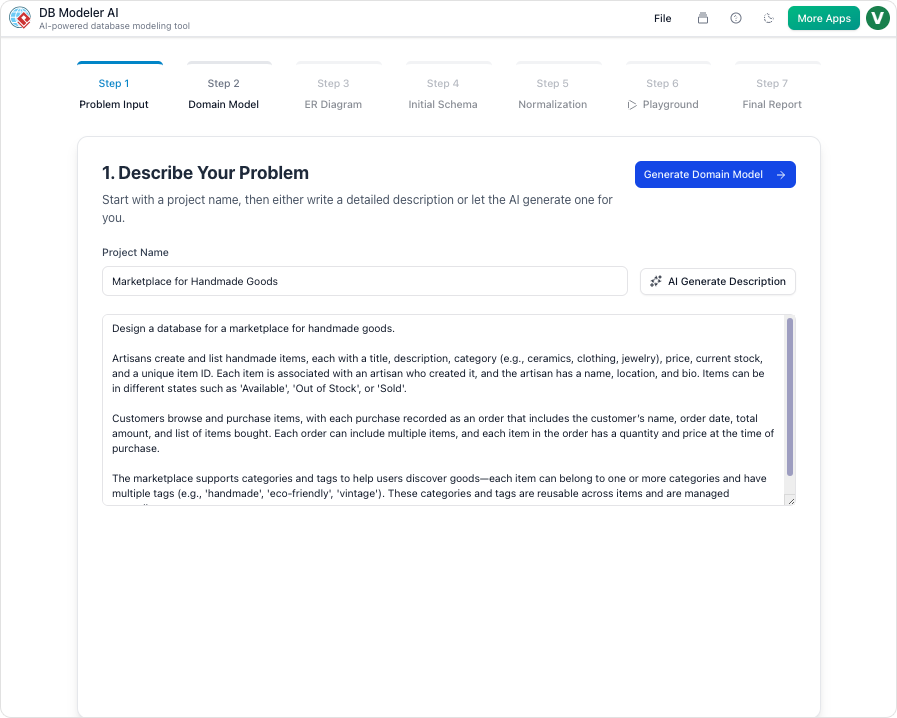
ステップ1:問題の入力と要件分析
このプロセスは、ユーザーがビジネスニーズを明確にすることから始まります。従来のツールがすぐにコードを要求するのに対し、この段階では平易な英語を受け入れます。AIはこの入力を分析し、エンティティ、属性、論理を抽出し、包括的な技術的要件のセットに拡張します。
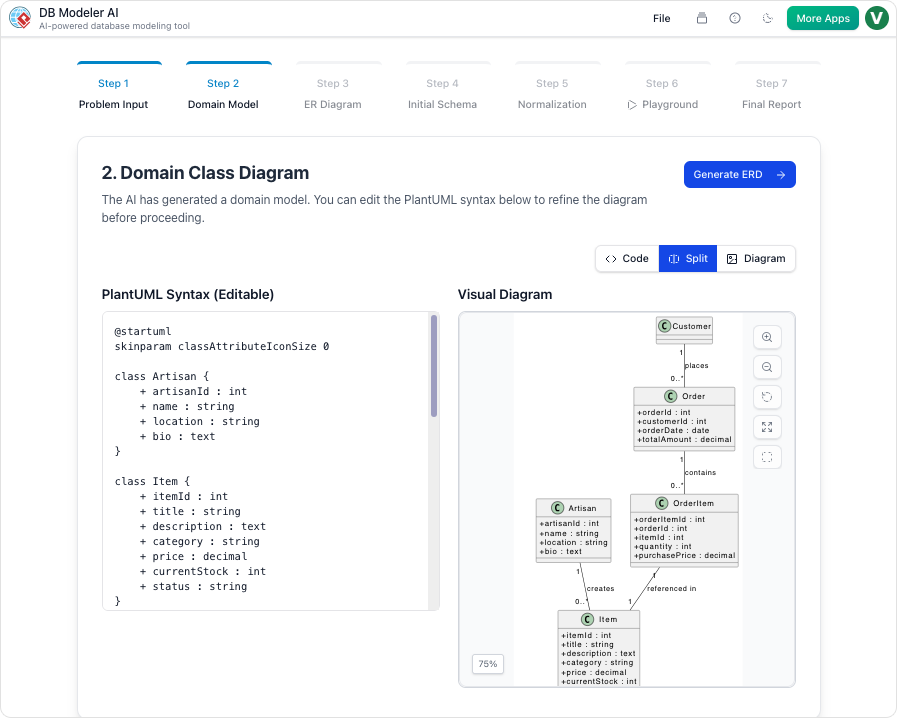
ステップ2:ドメインクラス図の可視化
要件が確定すると、システムは編集可能なPlantUML図を使用して概念的なビューを生成します。これにより、データベース固有の詳細に巻き込まれることなく、高レベルのオブジェクトとその属性を可視化できます。これは構造的なブループリントとして機能します。
ステップ3:ER図への変換
概念モデルはその後、厳密なエンティティ関係図(ERD)に変換されます。この段階で、論理がデータベース固有のものになります。システムは主キー、外部キー、およびテーブル間の関係の基数(例:1対多、多対多)を定義します。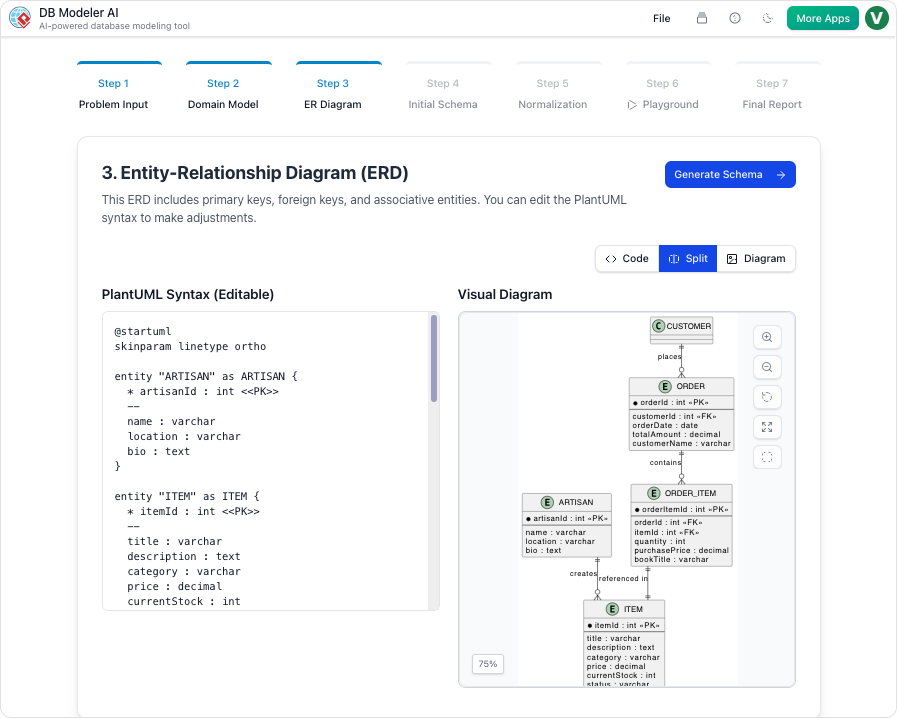
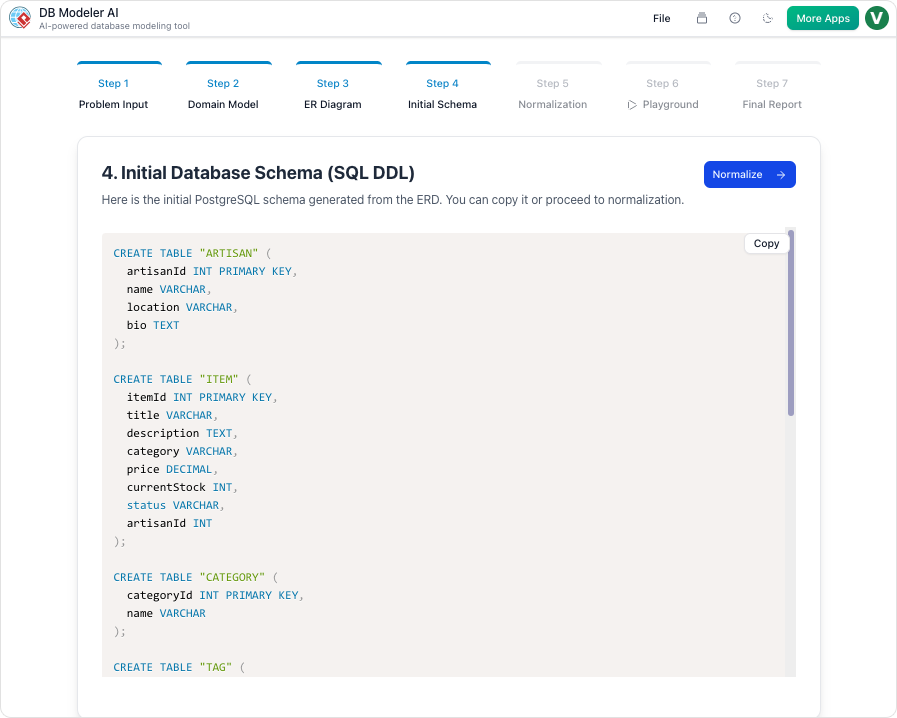
ステップ4:初期スキーマ生成
関係性マップが確定した後、プラットフォームは図を実行可能なコードに変換します。技術的なPostgreSQL互換のSQL DDL文。このコードにより、データベースの基盤となる実際のテーブルと制約が作成されます。
 ステップ5:インテリジェントな正規化
ステップ5:インテリジェントな正規化
最も重要なステップの一つは、スキーマの段階的な最適化です。AIは設計を第1正規形(1NF)から第3正規形(3NF)へと段階的に移行します。ユニークな点として、このツールは教育的な根拠をすべての構造的変更に提供し、データの重複がなぜ削除されたか、またはデータの整合性がどのように向上したかを説明しています。
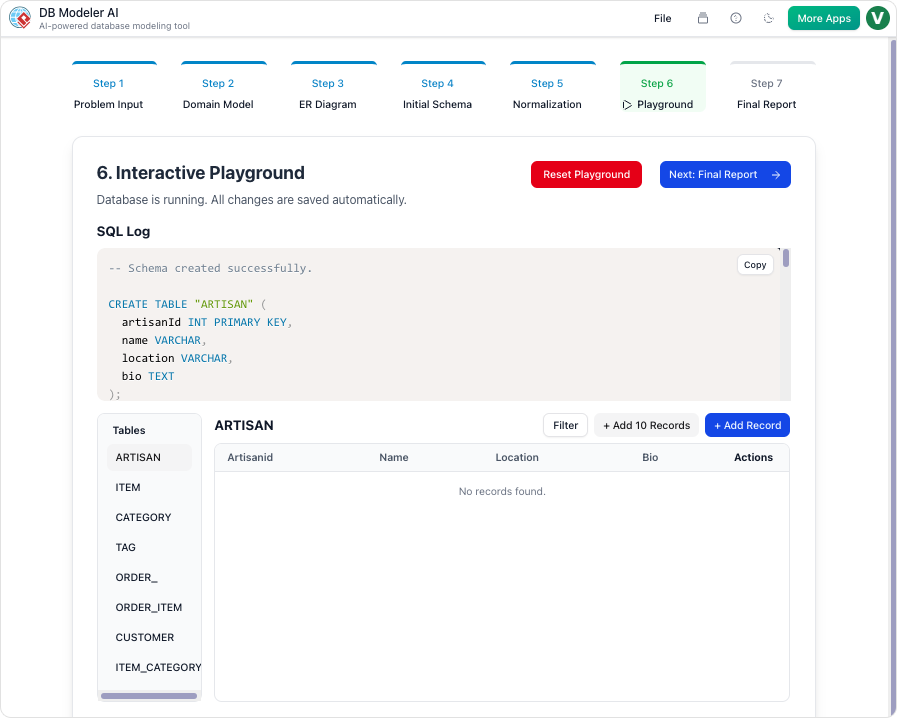
ステップ6:インタラクティブなプレイグラウンド
理論がブラウザ内SQLクライアントで実践と融合します。システムは新しいスキーマに自動的に現実的なAI生成サンプルデータを投入します。これにより、ユーザーはテーブルを手動で入力する必要なく、クエリを記述し、データベースの論理を即座にテストできます。
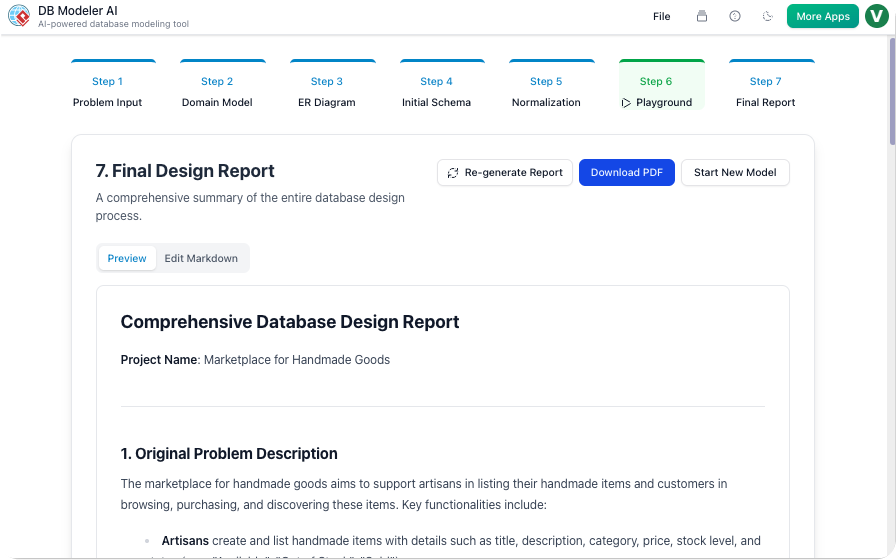
ステップ7:最終レポートとエクスポート
完了後、設計はデプロイ用にパッケージ化されます。プラットフォームはすべての図、技術文書、SQLスクリプトを洗練されたPDFまたはJSON形式に統合します。これにより、ドキュメントがコード実装と完全に一致することが保証されます。
ヒントとテクニック
DB Modeler AIの最大の効果を得るためには、以下の最適化戦略を検討してください:
- ステップ1で詳細に記述する:出力の品質は入力に大きく依存します。具体的なビジネスルール(例:「ユーザーは複数の住所を持つことができるが、プライマリ住所は1つだけ」)を、平易な英語で記述することで、初期要件が正確であることを確認できます。
- 正規化の根拠を確認する:ステップ5で提供される教育的ノートをスキップしないでください。AIがテーブルを分割した理由を理解することで、将来のデータベースのメンテナンスが容易になり、より優れたデータベースアーキテクトになれます。
- プレイグラウンドでストレステストを行う:生成されたサンプルデータを使って複雑なJOINクエリを実行します。これにより、ステップ3で定義された関係性が、データに対して意図する分析質問をサポートしているかどうかを確認できます。
- 図を繰り返し改善する:ステップ2のPlantUML図は編集可能であるため、この段階で構造的な誤りをSQLコードになる前に発見できます。データベースにデータが入った状態でリファクタリングするよりも、図を修正する方がはるかに簡単です。
これはDBModeler AIの主要なプロダクトランディングページであり、ドメインモデリング、ER図、スキーマ生成、ライブSQLテストといったAI駆動型機能の明確な概要を提供しており、最も適した選択です。
このリリースノートページでは、DBModeler AIの最新の更新点および改善点を紹介しており、ツールの進化する機能を最新の状態で把握したいユーザーにとって理想的です。
このガイドでは、DBModeler AIが専門家のアドバイス、視覚的な図示、ライブSQLテストを統合している点を詳しく解説しており、実際の用途を検討するユーザーにとって重要な側面をカバーしています。
AIに特化しているわけではありませんが、このチュートリアルでは、DBModeler AIをホストしているプラットフォームであるVisual Paradigmにおける実用的なデータベース設計ワークフローを示しており、ツールを導入するユーザーにとって貴重な文脈を提供します。
この無料ツールページでは、DBModeler AIの機能の基盤となるVisual ParadigmのERD機能を強調しており、データベースモデリングの基礎に興味を持つユーザーにとって関連性の高いリソースです。